Glyph:文本转图片解决长上下文困境,智谱把“DeepSeek-OCR”具像化了

Glyph:文本转图片解决长上下文困境,智谱把“DeepSeek-OCR”具像化了

用户11563501
发布于 2026-06-23 10:22:08
发布于 2026-06-23 10:22:08
传统的 token 扩展方式已经走到了算力成本的天花板。与其硬扛百万级 token 的计算压力,不如让 AI "看"文字,而不是"读"文字。

不知道是否是巧合,DeepSeek与智谱都想到了这一个思路,并同时对外发布,DeepSeek发布了DeepSeek-OCR,而智谱发布了一个名为 Glyph 的框架,直接工程化的实现了这一思路。
不过,大家可能被deepseek吸引了注意力,而没有注意到它,笔者今天介绍介绍。
核心思想
传统方法要么扩展位置编码,要么修改注意力机制,但计算和内存开销仍然随 token 数量线性增长。检索方法能减少输入,但可能遗漏关键信息,还会增加延迟。
Glyph 换了个角度:改变数据表示方式。把文本转成图片,让已经具备 OCR、布局理解和推理能力的视觉-语言模型来处理。这样每个视觉 token 能编码更多字符,固定的 token 预算能覆盖更多原始内容。它将传统的序列建模问题转化为多模态问题,在保持语义信息的同时大幅降低计算成本。
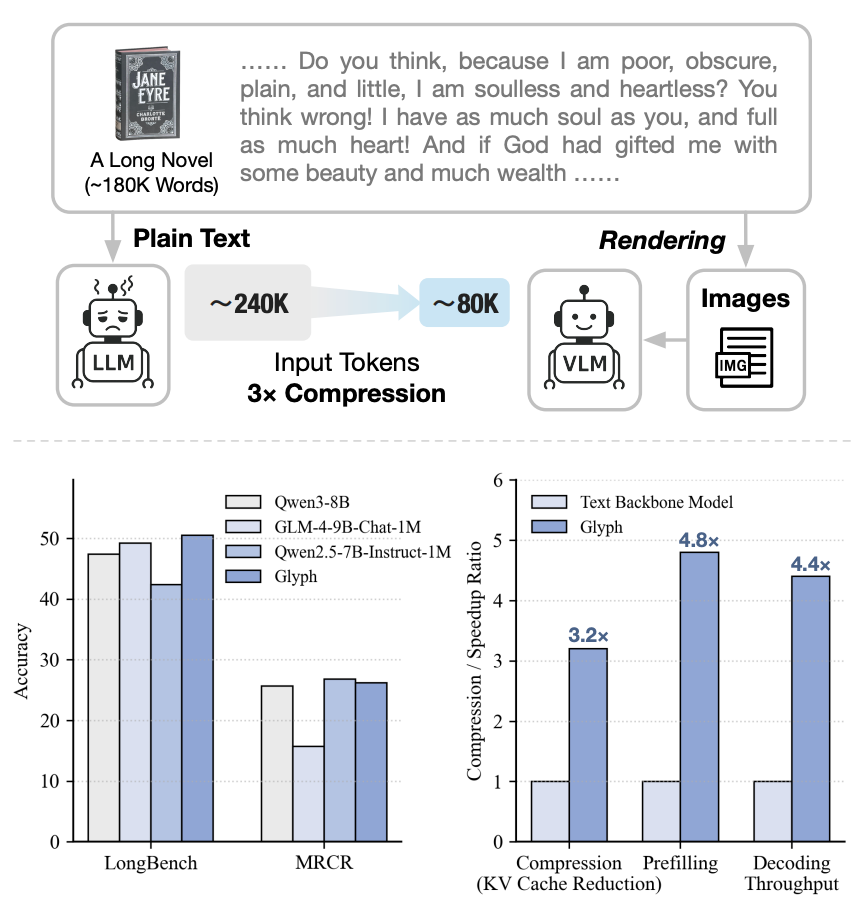
如图,240K tokens 的《简·爱》文本,通过 LLM 压缩到 80K tokens,然后转换成图像让 VLM 处理。整个过程实现了 3 倍压缩。
训练流程
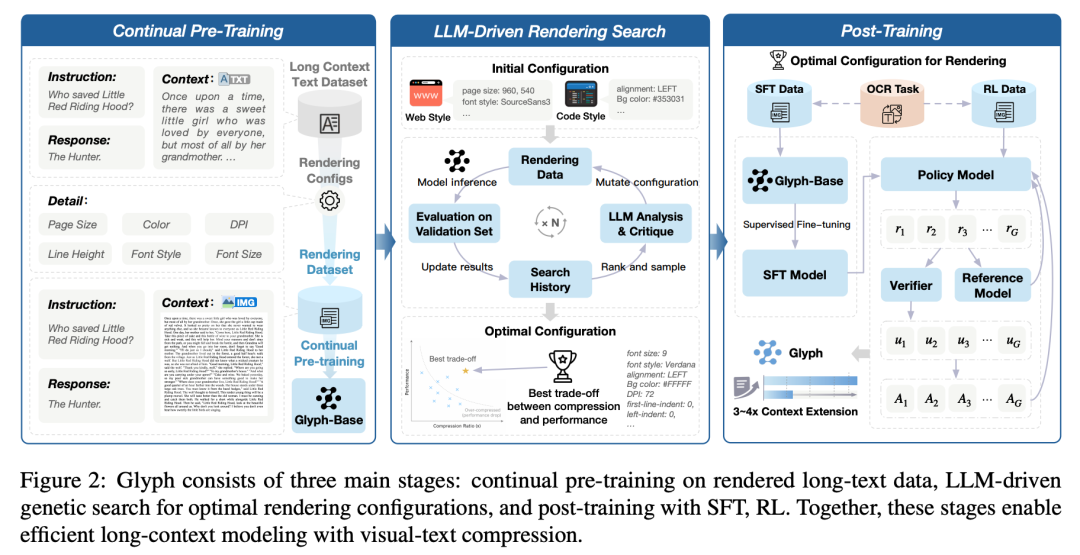
Glyph 的训练分三个阶段:
持续预训练:让视觉-语言模型接触大量不同排版风格的渲染长文本。目标是对齐视觉和文本表示,将长文本理解能力从文本 token 转移到视觉 token。
LLM 驱动的渲染搜索:这是个有趣的设计。用大语言模型驱动的遗传算法来优化渲染参数,包括页面大小、DPI、字体、字号、行高、对齐方式、缩进和间距。在验证集上评估候选配置,同时优化准确性和压缩比。
后训练:使用监督微调和强化学习(Group Relative Policy Optimization),外加一个辅助的 OCR 对齐任务。OCR 损失改善了小字体和紧密间距下的字符保真度。
实际效果
在 LongBench 和 MRCR 基准上,Glyph 实现了平均 3.3 倍的压缩比,某些任务接近 5 倍。MRCR 上平均 3 倍。这个收益随输入长度增加而扩大,因为每个视觉 token 承载的字符更多。
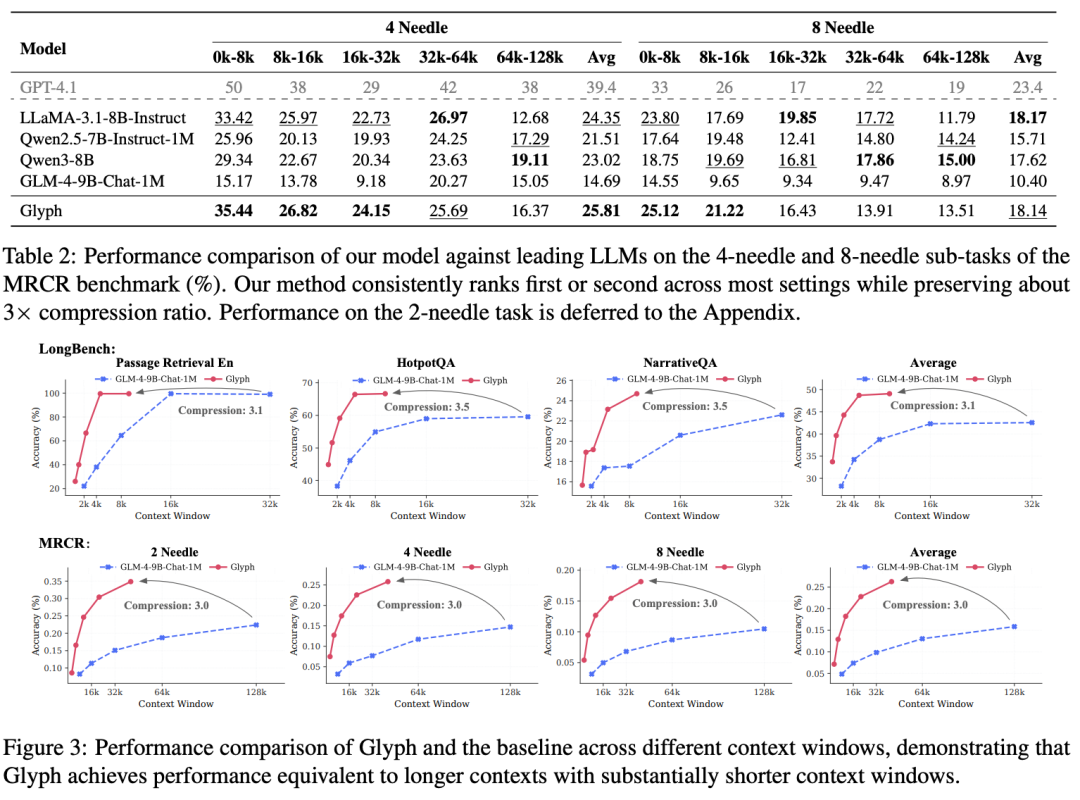
速度提升也很明显:在 128K 输入上,预填充速度提升约 4.8 倍,解码速度提升约 4.4 倍,监督微调吞吐量提升约 2 倍。
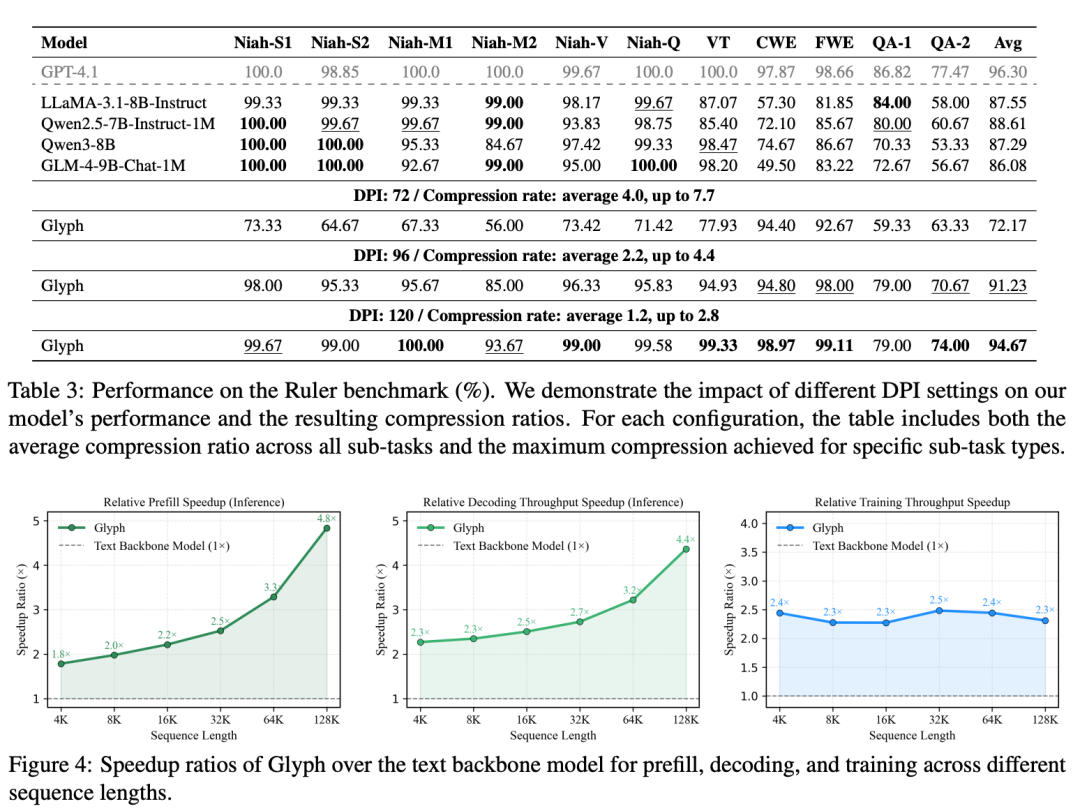
Ruler 基准证实,推理时使用更高的 DPI 能改善分数,因为更清晰的字形有助于 OCR 和布局解析。研究团队报告了不同 DPI 下的压缩比:
- DPI 72:平均压缩 4.0 倍,最高 7.7 倍
- DPI 96:平均压缩 2.2 倍,最高 4.4 倍
- DPI 120:平均压缩 1.2 倍,最高 2.8 倍
一些限制
Glyph 在多模态文档理解上表现不错。在渲染页面上的训练改善了 MMLongBench Doc 的性能,说明渲染目标对包含图表和布局的真实文档任务有用。
但也有明显的限制:
排版敏感性:过小的字体和过紧的间距会降低字符准确性,特别是对罕见的字母数字串。研究团队在 Ruler 上排除了 UUID 子任务。
OCR 挑战:识别细粒度或罕见的字母数字字符串仍然困难,超长输入时可能出现字符错误分类。
泛化限制:主要针对长文本理解训练,在更广泛任务上的能力还待研究。
小结
与DeepSeek-OCR一样,智谱的方案进一步证明了"视觉化文本处理"将会是一个新的热门方向。把长文本建模重新定义为多模态问题,在保持语义的同时减少token。从方案调性看,DeepSeek是概念方向验证,而Glyph来自于产品工程实践,更具体实用。对这个方向感兴趣,又不知道具体如何做,Glyph就是一个很好的学习样板。
代码:https://github.com/thu-coai/Glyph
模型:https://huggingface.co/zai-org/Glyph
论文:https://arxiv.org/abs/2510.17800
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-10-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号