拨云见日:Native Sparse Attention 如何重塑长上下文大模型效率边界

拨云见日:Native Sparse Attention 如何重塑长上下文大模型效率边界

翻身AI挖掘机
发布于 2026-06-22 16:22:14
发布于 2026-06-22 16:22:14
Native Sparse Attention : 如何重塑长上下文大模型效率边界 ✨
2025年计算语言学协会年会(ACL)的年度最佳论文奖项,DeepSeek与北京大学等机构联合呈现的《Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention》(以下简称NSA)脱颖而出,斩获殊荣。

这不仅是对DeepSeek在基础模型研究领域深厚积累的肯定,更预示着长上下文建模效率的未来走向。
长上下文的困境
Transformer架构中Attention机制对全局依赖的捕捉,赋予了LLM惊人的理解与生成能力。然而,这种"无差别"的全局关注也带来了显著的计算复杂度——其计算量与序列长度的平方成正比。
当序列长度从几千扩展到几十万甚至上百万时,计算资源需求呈指数级爆炸,导致训练成本高昂、推理延迟居高不下。
稀疏注意力(Sparse Attention)应运而生,旨在通过只计算"关键"的注意力对来削减计算量。然而,过往方法常陷入"高效推理的幻觉"和"可训练性之谜"两大困境。
"高效推理的幻觉":许多稀疏注意力方法理论上能大幅减少计算量,但实际部署时难以转化为显著的端到端加速。原因在于分散的内存访问模式与现代LLM普遍采用的MQA/GQA架构冲突,无法充分利用硬件并行能力。
"可训练性之谜":大多数稀疏注意力方法为推理设计,预训练后以"后处理"方式引入稀疏性,导致模型性能下降。一些方法中的离散操作导致计算图不连续,阻碍梯度回传;另一些虽理论可训练,但非连续内存访问模式使其无法利用FlashAttention等高效算子。
正是基于对这些痛点的深刻洞察,DeepSeek提出了NSA,旨在构建一种"原生"的、从训练到推理全生命周期都高效的稀疏注意力机制。
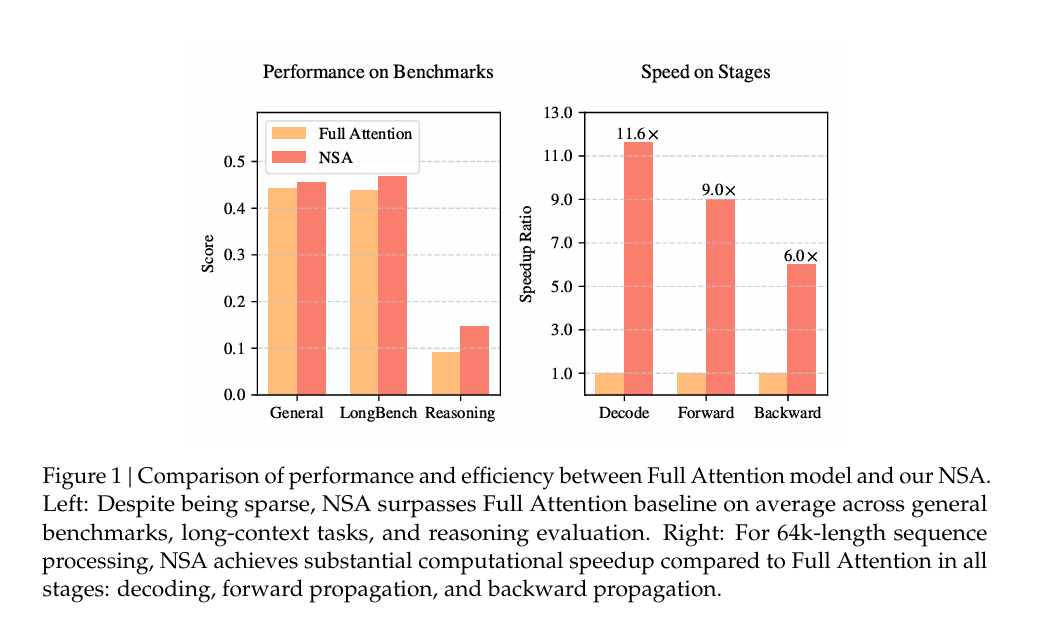
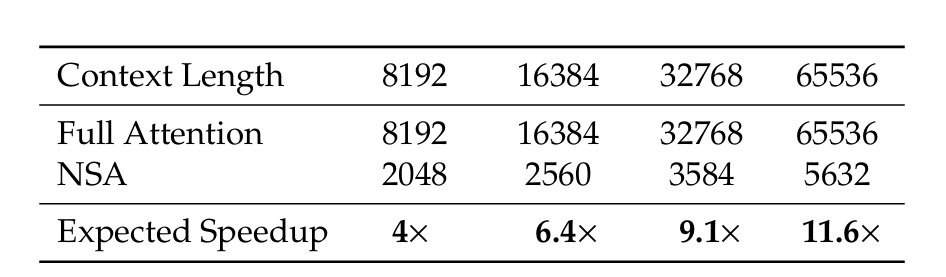
正如论文中图1 (Figure 1) 所展示的,NSA不仅在通用基准、长上下文任务和推理任务上保持甚至超越了全注意力模型的性能,更在64k序列长度下实现了解码、前向传播和反向传播的显著加速,最高可达11.6倍。💡
NSA的精妙设计
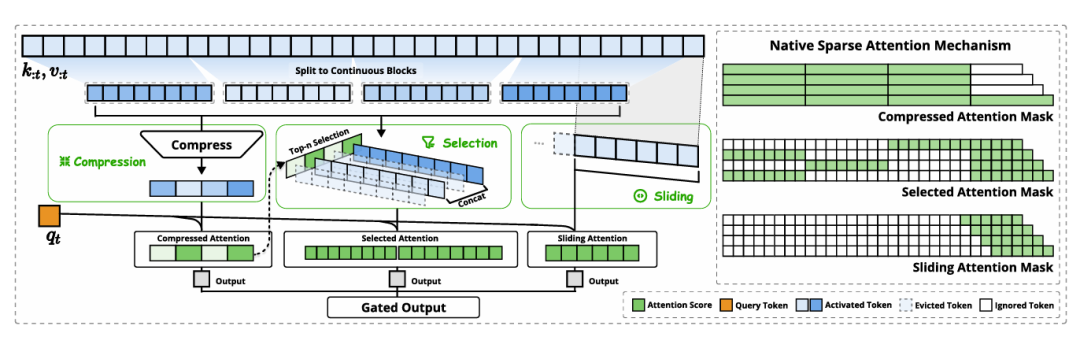
NSA的核心在于其动态分层稀疏策略,巧妙地将注意力机制分解为三个并行分支,分别处理不同粒度的上下文信息。这就像人类阅读长篇文献时,会先"粗读"摘要把握主旨,再"精读"关键段落,同时"强记"最近读过的内容。
全局视野:Token Compression
通过将连续的Key和Value序列聚合为"压缩Token"(Compressed Tokens),大幅减少需要计算注意力的Key/Value数量。每隔一定步长(stride)对一个固定长度的块(block)进行压缩,生成代表该块信息的压缩Key和Value。这种压缩通过可学习的MLP实现,并引入块内位置编码。
局部聚焦:Token Selection
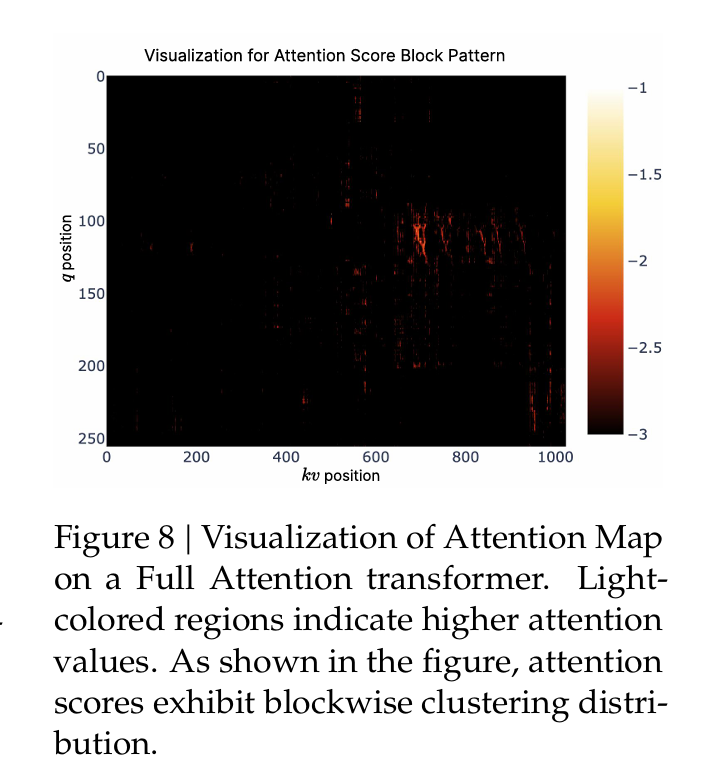
NSA采用Blockwise Selection,利用压缩Token分支中产生的中间注意力分数来计算每个选择块的重要性得分。得分最高的Top-N个块中的所有Token将被保留。这种设计与现代GPU的内存访问模式高度契合,能够实现连续的内存读取,充分利用Tensor Core的计算能力。
如论文中图8 (Figure 8) 所示,注意力分数在空间上往往呈现连续性。
即时记忆:滑动窗口(Sliding Window)
NSA还设置了一个独立的滑动窗口分支,维护固定大小的最近Token集合并对其进行全量注意力计算。这解决了稀疏注意力可能导致模型"遗忘"局部细节的问题,并允许压缩和选择分支更专注于学习长距离和全局模式。
这三个分支的输出通过一个可学习的门控机制(Gated Mechanism)进行聚合,形成最终的注意力输出。论文中图2 (Figure 2) 清晰地展示了NSA的整体架构和不同注意力模式的示意图。👍
硬件对齐与原生可训练的融合 🚀
NSA之所以能够将理论上的效率提升转化为实际的加速,关键在于其对硬件对齐和原生可训练性的深度考量。
硬件对齐的Kernel设计
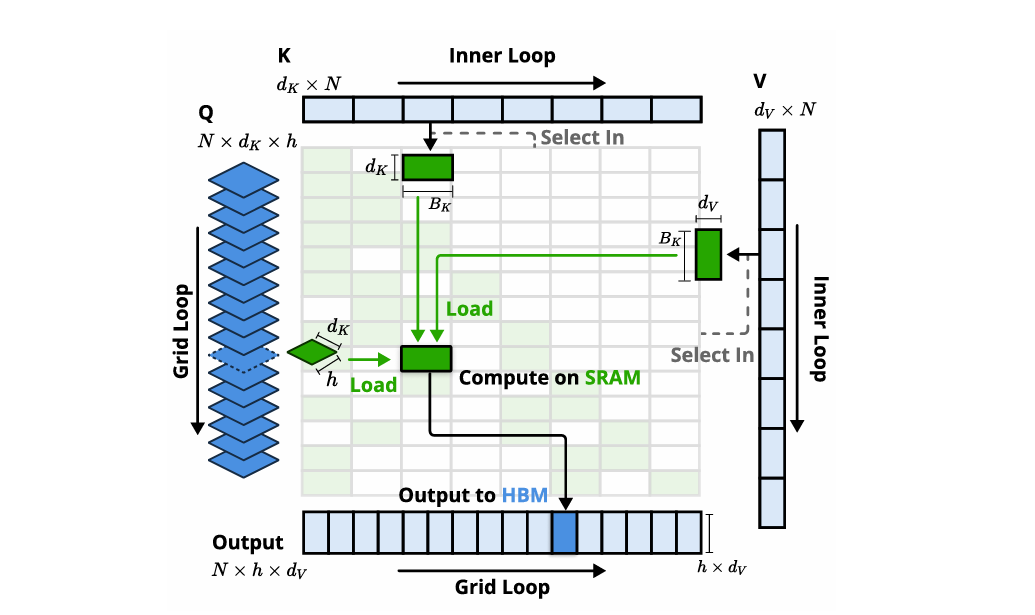
NSA在Triton上实现了定制化的稀疏注意力Kernel,针对MQA/GQA这种共享KV Cache的架构进行优化。
核心在于:组中心数据加载,确保数据访问局部性;共享KV获取,通过顺序加载连续的KV块到SRAM,最大限度减少HBM内存传输;以及网格调度,简化Kernel设计并优化并行执行。
这在论文中图3 (Figure 3) 的Kernel设计图中得到了详细阐述。
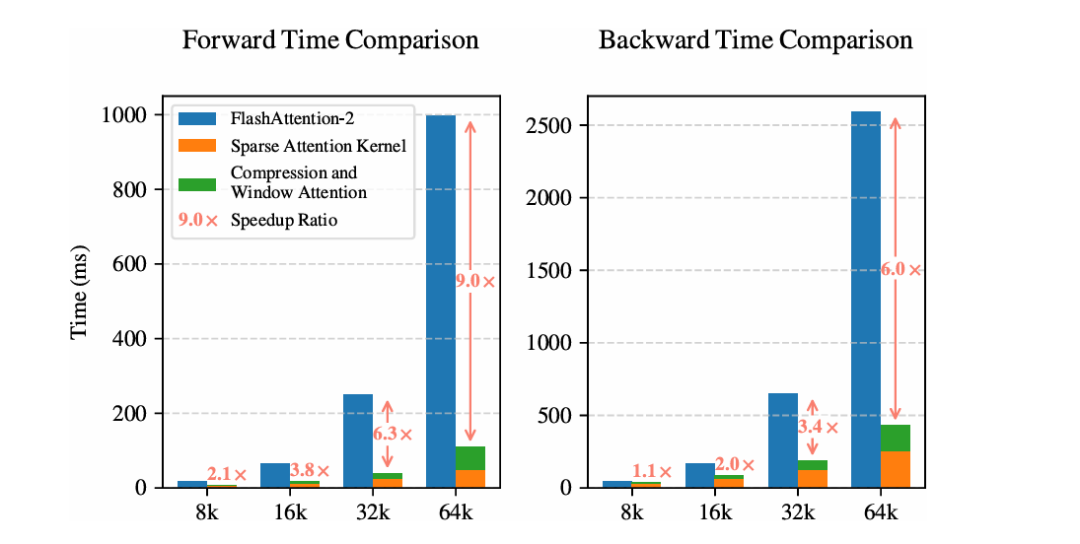
这些硬件层面的优化,使得NSA在处理长序列时,能够显著降低内存访问量(如表4 (Table 4) 所示)。
从而在解码、前向和反向传播阶段都实现了显著加速。在64k序列长度下,前向加速可达9.0倍,反向加速可达6.0倍,解码加速更是高达11.6倍(参见图6 (Figure 6))。
原生可训练的设计
NSA从预训练阶段就将稀疏注意力机制融入模型架构,使得模型在学习过程中就能适应并优化这种稀疏模式。
其"原生可训练"体现在:连续可微的操作,NSA避免了以往稀疏注意力中常见的离散操作,确保计算图连续可微,允许梯度平滑回传;以及训练效率提升,通过硬件对齐的Kernel设计,NSA在训练阶段也能享受到显著加速。
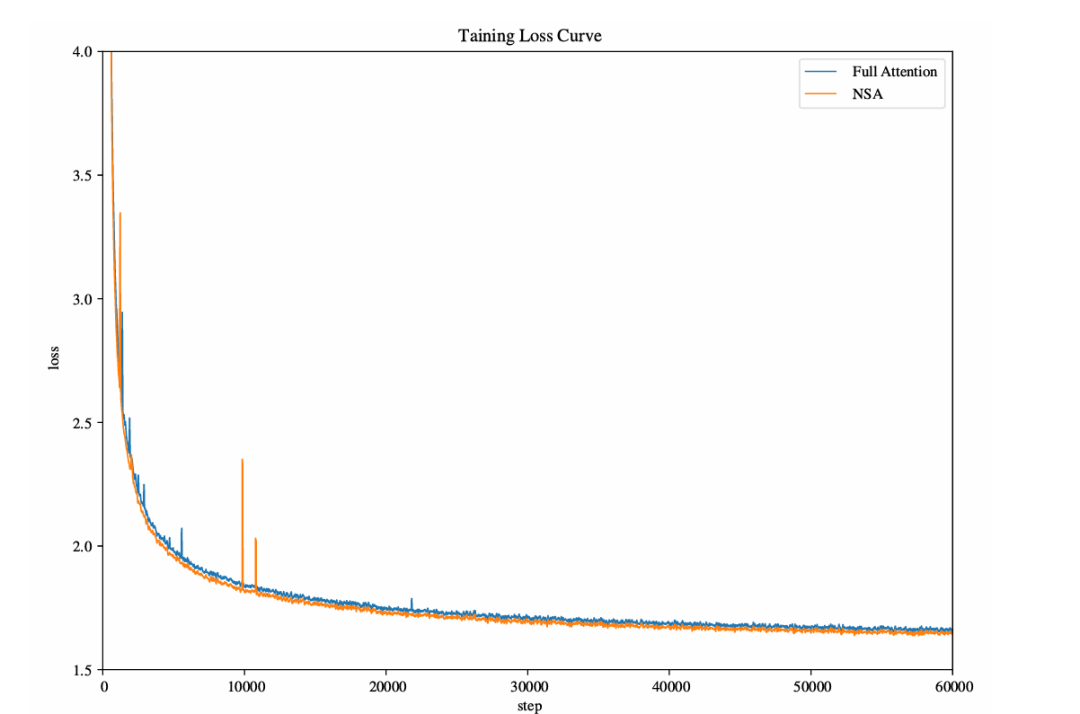
论文中图4 (Figure 4) 展示的训练损失曲线也印证了这一点:NSA不仅收敛稳定,甚至比全注意力模型取得了更低的损失值。💪
实验成果:性能与效率的双重奏 🏆

论文通过全面的实验验证了NSA的有效性。
通用基准性能:在MMLU、BBH、GSM8K等通用基准测试上,NSA性能与全注意力模型相当,甚至在某些推理任务上表现更优(参见表1 (Table 1))。这表明NSA在过滤"噪音"信息、专注于关键信息方面具有优势。
长上下文性能:在Needle-in-a-Haystack测试中,NSA在64k上下文长度下实现了完美的检索准确率。这得益于其分层设计,压缩Token用于全局扫描,选择Token用于精确检索。
而在LongBench这类长上下文基准测试上,NSA超越了包括全注意力模型在内的所有基线方法,尤其在多跳问答和代码理解等复杂任务上表现突出。
链式推理能力:通过对数学推理任务(AIME 24)的微调,NSA-R(NSA版本)在8k和16k上下文设置下均显著优于Full Attention-R(全注意力版本)。这表明NSA能够有效捕捉长距离逻辑依赖,支持更深层次的推理。📊
展望未来:长上下文大模型的演进之路 🗺️
从NSA中我们可以总结出几点关键洞察:稀疏性是必然趋势,随着模型规模和上下文长度的不断增长,全注意力机制的计算瓶颈将愈发突出。
原生集成的重要性,将稀疏机制从预训练阶段就融入模型,而非作为后处理步骤,是保证性能和训练效率的关键。
硬件感知的算法设计,仅仅在理论上减少计算量是不够的,必须考虑实际硬件的特性,才能将理论优势转化为实际加速。
动态,复杂问题往往需要分层解决,NSA的分层动态稀疏策略,为我们处理多尺度信息提供了一个优雅的范式。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号