高阶Flume理论知识个人心得

高阶Flume理论知识个人心得

wuzhigang
发布于 2026-06-18 08:36:31
发布于 2026-06-18 08:36:31
高阶Flume理论知识个人心得
一、flume的概念
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志数据采集、聚合和传输的工具二、flume的作用
读取各类数据源数据,经过 采集-聚合-传输流程 ,将数据写入HDFS、hbase、hive、kafka等众多外部存储系统中三、Flume的运行原理及架构组成
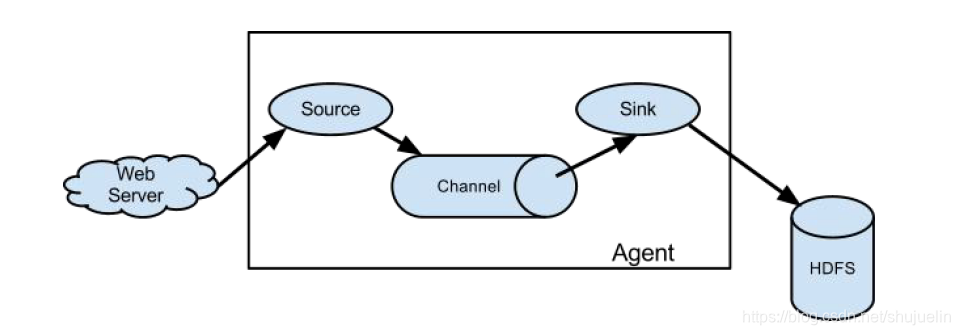
img
架构组成:
agent+collector+storage
agent 用于采集数据,agent是flume中产生数据流的地方,同时,agent会将产生的数据流传输到collector
collector 的作用是将多个agent的数据汇总后,加载到storage中。
storage 是存储系统,可以是一个普通file,也可以是HDFS,HIVE,HBase等
核心组件构成: Source Channel Sink
Source: 采集数据-负责完成对日志数据的收集,会将数据源数据处理成transtion 和 event 发送到channel中
Channel: 缓冲数据-负责提供一个队列的功能,对source提供中的数据进行简单的缓存
Sink: 存储与传输数据-负责拉取channel端的数据,并将其持久化到文件系统,数据库,或者提交到远程服务器,或者提供给其他的agent的Source
种类:
Source:
Kafka Source:就是用kafka consumer连接kafka,读取数据,然后转换成event,写入channel
AVRO Source:通过监听一个网络端口来接受数据,而且接受的数据必须是使用avro序列化框架序列化后的数据
Http Source:接收get和post的http请求,http请求会被HttpHandler接口实现类处理,从而将http请求转换为event事件提交到channel
TailDir Source: 监视指定目录下的一批文件,只要某个文件中有新写入的行,则会被tail到
Exec Source :启动一个用户所指定的linux shell命令,采集这个linux shell命令的标准输出,作为收集到的数据,转为event写入
channel
Channel:
Memory Channel
event事件保存在JavaHeap中,基于内存缓存,如果允许数据小量丢失,推荐使用。(宕机可能丢失数据)
File Channel
event事件保存在本地磁盘中,可靠性高,但吞吐量低于Memory Channel,如果对数据安全性较高,推荐使用
JDBC Channel
event事件保存在关系型数据中,一般不推荐使用
kafka channel
event事件保存于Kafka,基于磁盘,可靠性高
Sink:
HDFSSink
KafkaSink
HbaseSink
HiveSink
AvroSink
运行原理:
Flume的核心是一个agent,agent对外有两个进行交互的地方,一个是source,负责采集,接受数据的输入,另一个是sink,数据的输出,主要负责将数据发送到外部指定的目的地。在source接收到数据之后,会将数据传送到channel,channel是通道,作为一个数据缓冲区会临时将这些数据存放起来,之后sink会将channel中的数据发送到指定的地方。这里需要注意:只有sink将channel中的数据发送成功之后,channel才会删除临时数据,就是这种机制保证了数据传输的可靠性与安全性
二个单位:
NO1:运行单位
Agent-Flume运行的核心是Agent,Agent是flume最小的独立运行单位,一个agent就是一个JVM,它可以被看成是一个完整的数据采集工具
NO2:数据单位:
Event(事件)- 事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化
工作模式:
push Sources:外部系统会主动地将数据推送到Flume中,如RPC、syslog。
Polling Sources:Flume到外部系统中获取数据,一般使用轮询的方式,如text和exec四、Flume的面试题
flume如何保证数据可靠性
将channel设置为file
利用事务
Flume使用两个独立的事务分别负责从soucrce到channel,以及从channel到sink的事件传递。一旦事务中所有的事件全部传递到channel且提交成功,那么source就将该文件标记为完成。同理,事务以类似的方式处理从channel到sink的传递过程,如果因为某种原因使得事件无法记录,那么事务将会回滚。且所有的事件都会保持到channel中,等待重新传递。
使用Flume实时收集日志的过程中,尽管有事务机制保证数据不丢失,但仍然需要时刻关注Source、Channel、Sink之间的消息传输是否正常,比如,SouceàChannel传输了多少消息,ChannelàSink又传输了多少,两处的消息量是否偏差过大等等。
flume监控有多种,比如Http监控:
使用这种监控方式,只需要在启动flume的时候在启动参数上面加上监控配置。其中-Dflume.monitoring.type=http表示使用http方式来监控,后面的-Dflume.monitoring.port=1234表示我们需要启动的监控服务的端口号为1234,这个端口号可以自己随意配置。然后启动flume之后,通过http://ip:1234/metrics就可以得到flume的一个json格式的监控数据
4.flume 管道内存,flume 宕机了数据丢失怎么解决?
1)Flume 的 channel 分为很多种,可以将数据写入到文件
2)防止非首个 agent 宕机的方法数可以做集群或者主备
5. flume 和 kafka 采集日志区别,采集日志时中间停了,怎么记录之前的日志?
Flume 采集日志是通过流的方式直接将日志收集到存储层,而 kafka 是将缓存在 kafka集群,待后期可以采集到存储层
Flume 采集中间停了,可以采用文件的方式记录之前的日志,而 kafka 是采用 offset 的方式记录之前的日志
5 Flume的事务机制和可靠性
1) Flume的事务机制
所以这就不得不提Flume的事务机制(类似数据库的事务机制):Flume使用两个独立的事务分别负责从soucrce到channel,以及从channel到sink的事件传递。比如以上面一篇博客中的事例为例:spooling directory source 为文件的每一行创建一个事件,一旦事务中所有的事件全部传递到channel且提交成功,那么source就将该文件标记为完成。同理,事务以类似的方式处理从channel到sink的传递过程,如果因为某种 原因使得事件无法记录,那么事务将会回滚。且所有的事件都会保持到channel中,等待重新传递。
2) Flume的At-least-once提交方式
Flume的事务机制,总的来说,保证了source产生的每个事件都会传送到sink中。但是值得一说的是,实际上Flume作为高容量并行采集系统采用的是At-least-once(传统的企业系统采用的是exactly-once机制)提交方式,这样就造成每个source产生的事件至少到达sink一次,换句话说就是同一事件有可能重复到达。这样虽然看上去是一个缺陷,但是相比为了保证Flume能够可靠地将事件从source,channel传递到sink,这也是一个可以接受的权衡。如上博客中spooldir的使用,Flume会对已经处理完的数据进行标记。
3) Flume的批处理机制
为了提高效率,Flume尽可能的以事务为单位来处理事件,而不是逐一基于事件进行处理。比如上篇博客提到的spooling directory source以100行文本作为一个批次来读取(BatchSize属性来配置,类似数据库的批处理模式)。批处理的设置尤其有利于提高file channle的效率,这样整个事务只需要写入一次本地磁盘,或者调用一次fsync,速度回快很多
1.介绍一下flume的channel
channel被设计为event中转临时缓冲区,存储source收集并且没有被sink读取的event,平衡source收集和sink读取的速度,可以将其视为flume内部的消息队列。channel线程安全并且具有事务性,支持source写失败写,sink读失败重复读的操作。常见的类型包括Memory Channel,File Channel,Kafka Channel
2.Memory Channel与File Channel的优缺点
Memory Channel读写速度快,但是存储数据量小。Flume进程挂掉、服务器停机或者重启都会导致数据丢失。在资源充足,不关心数据丢失的场景下可以使用。
File Channel存储容量大,无数据丢失的风险。读写速度慢,但可以通过配置多磁盘文件路径,通过磁盘并行写入提高File Channel性能。Flume将Event顺序写入到File Channel文件的末尾,可以通过配置maxFileSize参数配置数据文件大小,当文件大小达到这个值,创建新的文件,并将该文件设置为只读,直到Flume把该文件读取完成,删除该文件。
3.Kafka Channel的优点有哪些
Memory Channel有很大程度丢失数据的风险,File Channel虽然无数据丢失风险,但如果缓存下来的消息来没来得及写入Sink,Agent就出现故障,File Channel中的消息一样不能被继续使用。Kafka的容错能力解决了这一点。
Flume一旦配置了Kafka为Channel,则不再需要配置Sink组件,减少了Flume启动的进程数,降低了服务器内存、磁盘等资源的使用率。
4.Flume的拦截器是什么
Source在将Event写入到Channel之前可以使用拦截器对Event进行各种形式的处理,Source和Channel之间可以设置多个拦截器,不同的拦截器可以设置不同的规则对Event进行处理
5.Flume的选择器是什么
Source发送的Event通过Channel选择器来选择以哪种方式写入到Channel中,Flume提供了三种类型的选择器,复制选择器、复用选择器以及自定义选择器
1)复制选择器:一个Source以复制的方式将一个Event写入到多个Channel中,不同的Sink可以从不同的Channel中获取到相同的Event。
如果Source没有指定Channel选择器,则该SOurce使用复制Channel选择器,复制选择器有一个配置参数optional,该参数指定的所有channel是可选的,当时间写入到这些channel时有失败发生,则忽略这些失败,否则抛出异常,要求Source重试。
a1.sources = r1
a1.channels = c1 c2 c3
a1.sources.r1.selector.type = replicating
a1.sources.r1.channels = c1 c2 c3
a1.sources.r1.selector.optional = c3
2)复用选择器:需要和拦截器配合使用,根据Event的头信息的不同写入到不同的Channel中。
a1.sources = r1
a1.channels = c1 c2 c3 c4
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = state
a1.sources.r1.selector.mapping.CZ = c1
a1.sources.r1.selector.mapping.US = c2 c3
a1.sources.r1.selector.optional.US = c4
a1.sources.r1.selector.default = c4
3)自定义选择器:自定义选择器需要实现ChannelSelector接口,或者继承AbstractChannelSelector类。
6.了解Flume的负载均衡和故障转移吗
设置sink组,同一个sink组内有多个sink,不同sink之间可以配置成负载均衡或故障转移
7.Flume的事务机制
flume基于事务传输event(批量传输),使用两个独立的事务分别处理source到channel和channel到sink,失败时会将所有数据回滚进行重试。该事务遵循“最少一次”语义,因此数据不会丢失,但有可能重复。
source-channel之间的重复可以靠TailDir Source自带的断点续传功能解决
put事务:
1)doPut:将批数据先写入到临时缓冲区putLIst(putList就是一个临时的缓冲区)
2)doCommit:检查channel内存队列是否足够合并
3)doRollback:channel内存队列空间不足,回滚,等待内存通道的容量满足合并
channel-sink之间的重复,可以延长等待时间,或者设置UUID拦截器,然后再redis里维护一个布隆表来使下游实时应用去重。
take事务:
1)doTake:将数据取到临时缓冲区takeList
2)将数据发送到下一个节点
3)doCommit:如果数据全部发送成功,则清除临时缓冲区takeList
4)doRollback:数据发送过程中如果出现异常,rollback将临时缓冲区takeList中的数据归还给channel内存队列五、Flume调优
source调优:
1 ,增加 source 个数,可以增大 source 读取能力。
2 ,具体做法 : 如果一个目录下生成的文件过多,可以将它拆分成多个目录。每个目录都配置一个 source
3 ,增大 batchSize : 可以增大一次性批处理的 event 条数,适当调大这个参数,可以调高 source 搬运数据到 channel 的性能
channel调优:
1 ,memory :性能好,但是,如果发生意外,可能丢失数据。
2 ,使用 file channel 时,dataDirs 配置多个不同盘下的目录可以提高性能。
3 ,transactionCapacity 需要大于 source 和 sink 的 batchSize 参数
sink调优:
增加 sink 个数可以增加消费 event 能力六、常用地址
https://www.cnblogs.com/zhangyinhua/p/7803486.html#_lab2_3_0
https://blog.csdn.net/heiren_a/article/details/112257688
https://blog.csdn.net/weixin_42796403/article/details/110518313?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-11.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-11.control
https://blog.csdn.net/ITgagaga/article/details/102888550?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-4.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-4.control本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-06-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号