高级SQL优化 | 告别临时表分组!PawSQL智能重写让跨表GROUP BY性能提升超百倍

高级SQL优化 | 告别临时表分组!PawSQL智能重写让跨表GROUP BY性能提升超百倍

PawSQL
发布于 2026-06-17 20:39:16
发布于 2026-06-17 20:39:16
✨ 引言
在数据分析类 SQL 中,GROUP BY 是最常用的SQL功能之一。然而,当分组字段来自多个不同的表时,往往会导致严重的性能问题。多表分组不仅无法有效利用索引,只能执行全量扫描 + 临时表聚合,性能骤降。
本文将深入解析PawSQL团队开发的GROUP BY优化算法,该算法能够智能识别跨表分组场景,并通过等值关系分析,将多表分组重写为单表分组,从而显著提升查询性能。
⚠️ 问题场景
来看一个典型的多表分组 SQL:
select o.o_custkey, c.c_name, sum(o.O_TOTALPRICE)
from customer as c, orders as o
where c.c_name like 'A%'
and o.o_custkey = c.c_custkey
group by c.c_name, o.o_custkey;问题:
GROUP BY同时包含了customer和orders两张表的字段。- 尽管
c.c_custkey = o.o_custkey,但优化器无法自动推断合并。 - 结果:只能进行 全表扫描 + 临时表分组,索引完全失效。
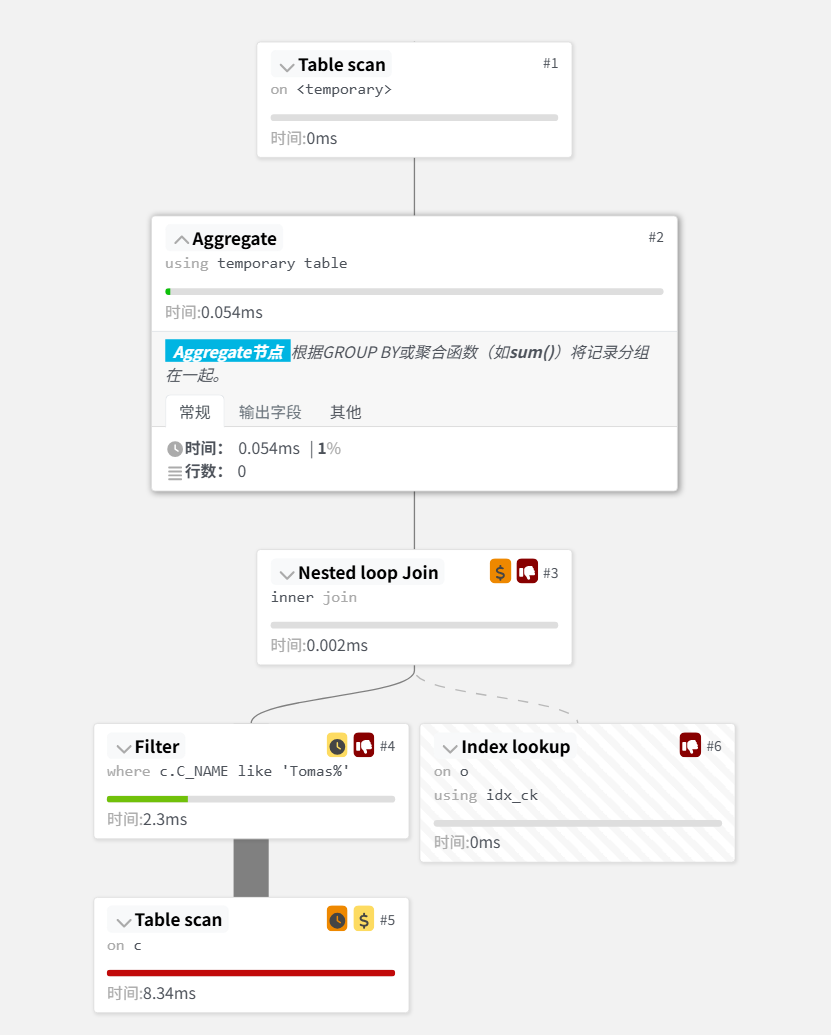
🔧 PawSQL 改写逻辑
从代码可以看出,GroupFromDiffTablesRewrite 主要做了几件事:
- 检测 GROUP BY 字段来源
- 如果分组字段来自多个表,触发优化逻辑。
- 查找等值连接关系
- 通过
equals集合,识别哪些字段在关联条件里等价(如c.c_custkey = o.o_custkey)。
- 通过
- 字段替换
- 将跨表的分组列统一替换为同一张表的字段,例如将
o.o_custkey替换为 c.c_custkey 。
- 将跨表的分组列统一替换为同一张表的字段,例如将
- 去重清理
- 删除冗余的分组列(因为
c_custkey和o_custkey等价,保留一个即可)。
- 删除冗余的分组列(因为
✅ 改写后 SQL
经过 PawSQL 自动改写后,SQL 会变成:
select c.c_custkey as o_custkey, c.c_name, sum(o.O_TOTALPRICE)
from customer as c, orders as o
where c.c_name like 'A%'
and o.o_custkey = c.c_custkey
group by c.c_name, c.c_custkey优化点:
- 分组字段只来自 cutomer 表。
- 优化器可直接使用 cutomer上的索引。
- 避免了临时表分组操作,性能显著提升。
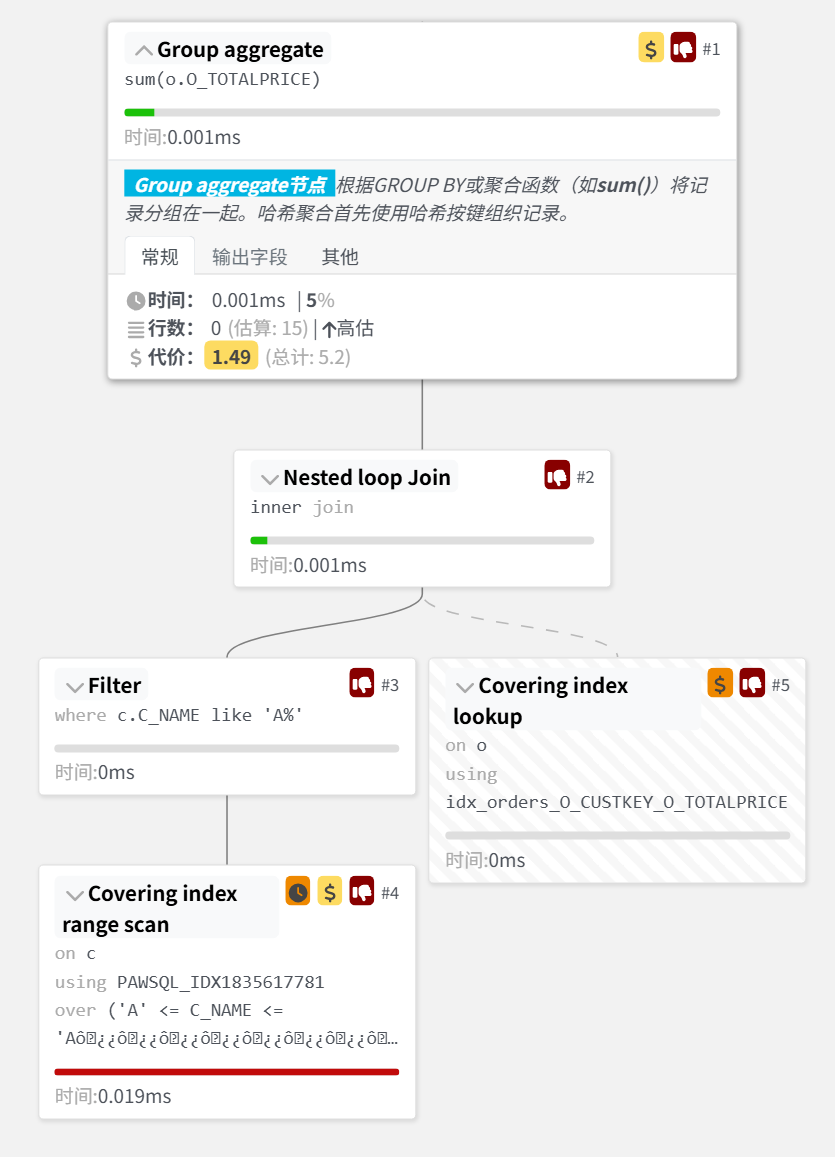
📊 性能对比(22919.05%⚡)
场景 | Extra 信息 | 分组方式 | 是否用索引 |
|---|---|---|---|
改写前 (跨表) | Using temporary | 全量临时分组 | ❌ |
改写后 (单表) | Using index | 索引分组扫描 | ✅ |
📌 总结
PawSQL 的 GroupFromDiffTablesRewrite 实现了:
- 🚨 自动识别 跨表分组 场景
- 🔄 统一分组字段到单表,保障索引可用
- 🧹 自动清理冗余分组列
- ⚡ 将临时表扫描 → 索引扫描,显著提升性能
这类改写在传统 DBA 优化中需要人工介入,而 PawSQL 能在 SQL 审核阶段提供自动重写优化的建议.
🌐关于PawSQL
PawSQL专注于数据库性能优化自动化和智能化,提供的解决方案覆盖SQL开发、测试、运维的整个流程,广泛支持多种主流商用、国产和开源数据库,为开发者和企业提供一站式的创新SQL优化解决方案。
图片
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号