【z-image V7最新整合包教程】图生图支持ControlNet姿势图/深度图/线条 直接下载即可使用!详细实测与使用技巧

【z-image V7最新整合包教程】图生图支持ControlNet姿势图/深度图/线条 直接下载即可使用!详细实测与使用技巧

代码简单说
发布于 2026-06-16 16:29:13
发布于 2026-06-16 16:29:13
【z-image整合包V7最新教程】图生图支持ControlNet姿势图/深度图/线条!详细实测与使用技巧
标签:z-image、ControlNet教程、AI绘图、姿态控图、深度图、ComfyUI、AI绘画、模型整合包、AI生成、提示词反推
z image教程、controlnet教程、z image control net、姿态图生图、深度图生图、AI绘图工具、z-image整合包下载、controlnet使用方法、AI图像生成教程、AI姿态控图、AI深度图控制
我平时做内容的时候,经常会需要各种 AI 生图素材。z-image 这个模型我一出来就开始关注了,说实话,它的画面质量真的是我用过同类工具里排前列的。
但老实说,它之前最大的遗憾,就是生态不够完善。 直到昨天—ControlNet 正式上线。
更夸张的是,今天 ComfyUI 也已经跟进支持,而我们整合包 V7 同步更新了 ControlNet 全套能力:姿势图、深度图、硬边缘、线条,全都能用。
整合包下载地址(直接下载即可使用): 👉 https://pan.quark.cn/s/097b62aae7a7
下面我会从“体验 + 实测演示 + 使用技巧”三个角度把所有功能讲透,让你不用踩坑也能一次上手。
准备好了就点赞收藏一下,我们开始吧。
在这里插入图片描述
一、ControlNet 四种控图方式到底差在哪?
在 z-image 整合包 V7 里,目前支持 4 种控图方式:
- 姿势控图(OpenPose 1)
- 姿势控图(OpenPose 2)
- 深度图控制(Depth)
- 硬边缘处理(Canny)
- 线条处理(Lineart)
为什么有两个姿态模型? ——因为它们不是同一个模型,表现差异非常明显。
下面我逐个通过真实案例演示。
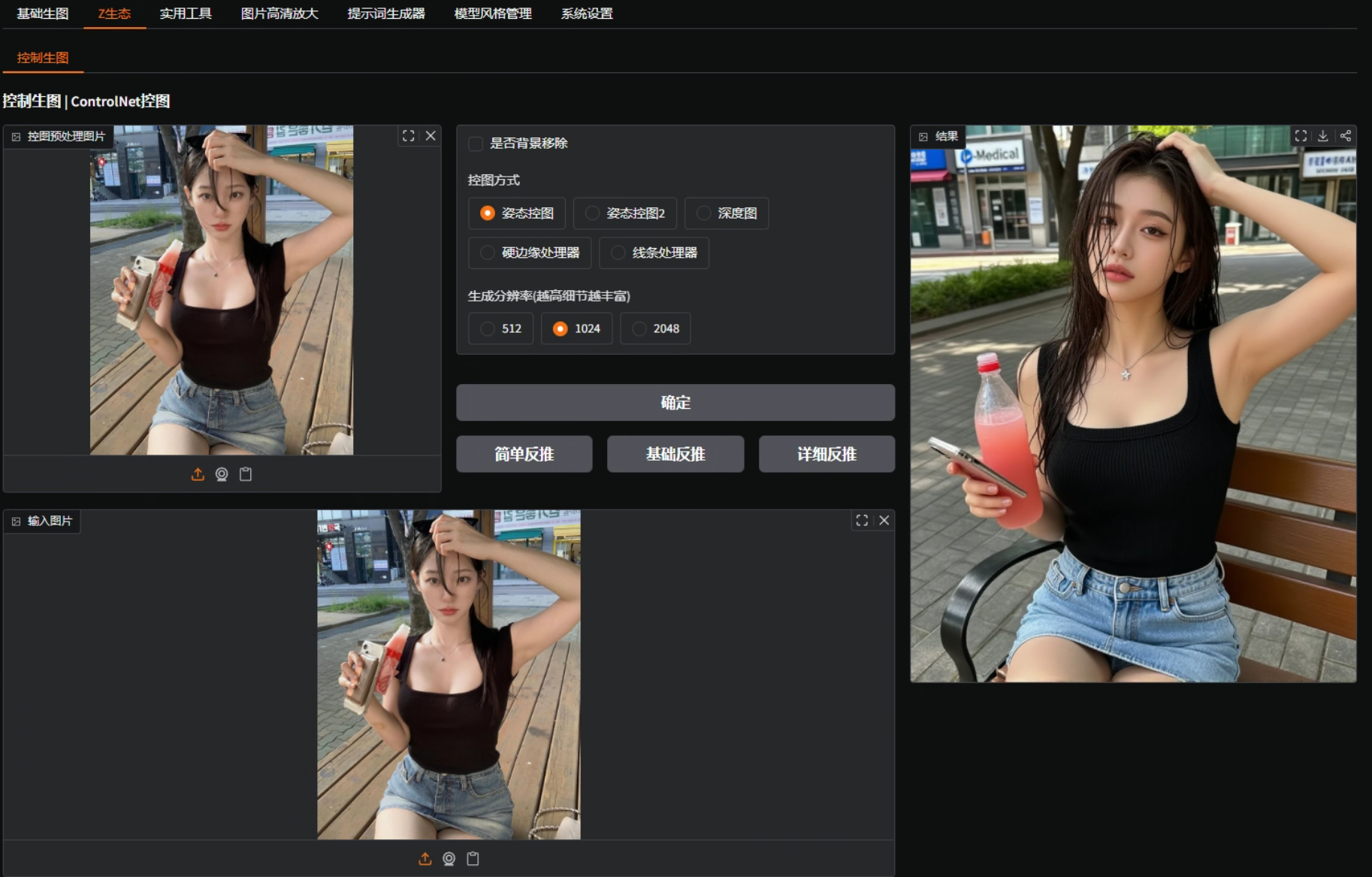
二、姿态控图(OpenPose 1 & 2):为什么要两个?
在这里插入图片描述
我直接拖一张图进去,点击“确定”,给大家看效果。
● OpenPose 一号模型
大多数情况下都能识别全身姿态,但手指细节、脚部细节不太行。
比如下面这种情况,手势里比“叶”字的姿势,它识别不到完整手型。
● 换成 OpenPose 二号模型
点击同样的图片,“确定”。
你会发现:
- 手指细节 ✔
- 脚部姿态 ✔
- 整体骨骼更完整 ✔
所以:
OpenPose 1 适合正常站姿、身体笔直、动作清晰的图片。 OpenPose 2 更适合手势复杂、有遮挡、有动作幅度的图片。
这也是整合包给两个姿态模型的原因。
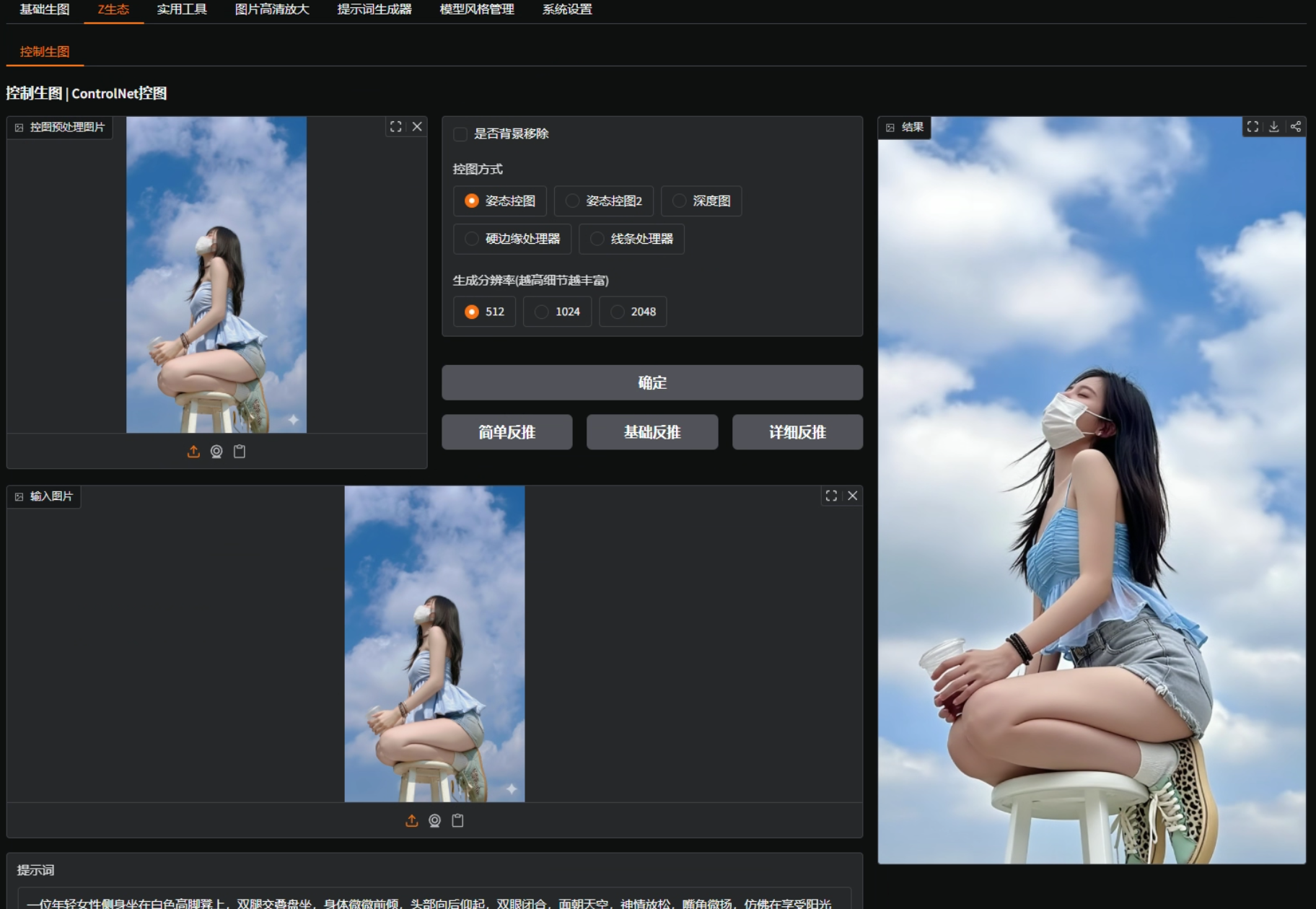
三、深度图控制:保留原图细节最强的方式
我把同样的图片拖进去,选择“深度图”,点击确定。
生成对比之后你会发现:
- 动作保持一致
- 连头发的造型都非常接近原图
- 衣服的褶皱、阴影、亮部都能跟随
深度图的控制能力明显强于姿态控图,适合对“细节一致性”要求高的场景。
比如:
- 原图人物脸型要保持一致
- 服装造型希望保留
- 动作不只是骨架,而是包含体块信息
深度图都能做到。
四、硬边缘处理(Canny):适合建筑、物体,不太适合人像
把人物拖进去你会发现:
- 边缘线条死板
- 人物像被“割出来”一样
- 效果很怪
但是用在建筑、街景、物体上,就很好。
适合:
- 建筑
- 机械
- 科技风
- 结构感强的物体
不适合人物。
五、线条处理(Lineart):比硬边缘柔和,但人物容易塑料感
线条处理器看上去比硬边缘要柔和一些,但在人像上的表现依然一般。
- 多数人物会出现“塑料感”
- 五官容易不自然
- 人像不推荐使用
但在插画、二次元、结构线稿场景是很好用的。
六、控制强度怎么调才是最优?
很多朋友不知道强度对效果影响非常大。
我给你一个万能原则:
姿态控图:0.75–0.85 最自然 深度图控制:0.70–0.90 更依赖图像本身情况 强度越高 = 越像原图,但越可能“质量下降”
我实际测试了一张手势图:
- 0.65 → 太松散,动作跑偏
- 0.80 → 人自然、动作一致
- 0.90 → 动作更像,但脸可能变形
所以建议从 0.8 附近开始微调。
七、生成图片尺寸设置:不懂这个会浪费你很多时间
z-image 的生成尺寸 = 原图尺寸
如果你传了一张特别大的图(例如 3000px),生成速度会非常慢。
可以通过“倍数”调整:
- 设置 1.0 → 原图
- 设置 1.5 → 更清晰
- 设置 0.8 → 更快速度
图小 → 放大 图大 → 缩小
非常实用。
八、提示词对画面影响非常大(一定要学会反推)
很多新手不会写提示词,所以 z-image 给了三个“提示词反推”按钮:
- 简单反推(90% 情况够用)
- 中级反推
- 高级反推(细节最多,适合复杂场景)
使用方法:
- 把图拖进去
- 点击“简单反推”
- 自动生成一段提示词
- 你可以对其中想改的部分做调整
- 点击生成
实测效果:
带提示词 → 有背景、有氛围、有细节 不带提示词 → 很空、效果差异大
举例: 输入“刘亦菲” + 姿态控图 效果完全不一样,人物自然度提升非常明显。
九、再给大家多看一个真实案例
我再拖一张人物照进去,不写提示词,直接生成。 ——画面干净,但没有背景。
然后我用“简单反推”补全提示词,再生成。
效果立马变成:
- 有草地背景
- 衣服细节更逼真
- 整体氛围一致
- 身体结构更合理
对于不会写提示词的人,这功能真的是救命。
十、总结:z-image ControlNet 虽然刚上线,但已经能实战
作为整合包第一次加入 ControlNet 功能,它并没有“卷到炸裂”,但:
- OpenPose 表现非常优秀
- 深度图控制力强
- 提示词反推很实用
- 和 ComfyUI 的支持速度非常快
按照 z-image 的更新节奏,我相信它的生态会非常快地完善起来。
你如果对“姿态生图”“深度图控图”“背景一致性”有需求,可以:
👉 直接下载 z-image 整合包 V7(含 ControlNet 全功能) https://pan.quark.cn/s/097b62aae7a7
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-06-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号