硅基流动里的RPM和TPM是什么意思?


硅基流动里的RPM和TPM是什么意思?
标签:大模型、硅基流动、Rate Limit、模型限速、豆包大模型
最近想摸摸有没有什么免费的大模型可以薅一薅,就随手点开了硅基流动的后台页面看看。结果看到一句话把我整不会了:
您当前的用量级别为 L0;使用本模型时 RPM 为 1,000;TPM 为 50,000。
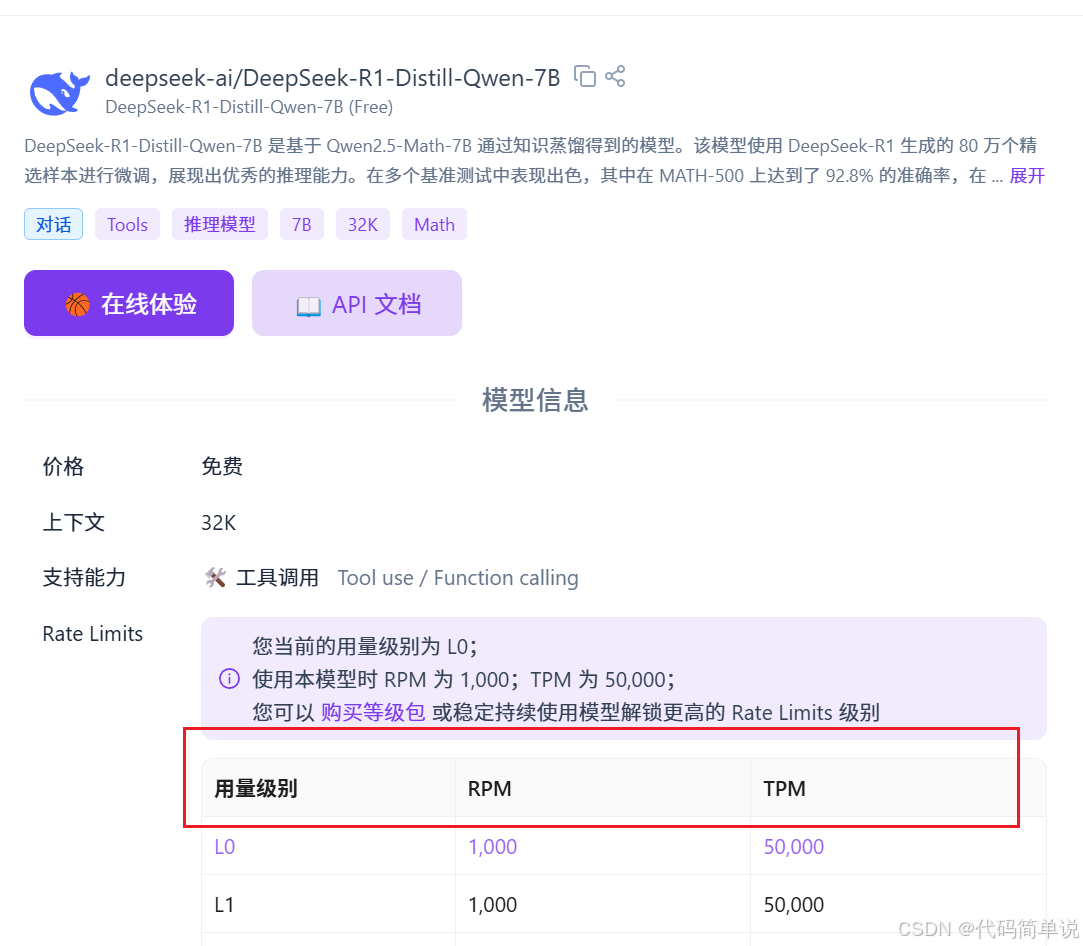
在这里插入图片描述
旁边还有提示说“可以购买等级包”,但我压根不知道“RPM”和“TPM”到底是啥,就更别提我需不需要升级了。
看似高深,其实和“流量”有关
第一眼看到这俩英文缩写,说实话我第一反应是:
- RPM?我懂,这不是“每分钟转速”嘛(机械控表示认同)
- TPM?这个是不是电脑的“安全芯片”?🤔
但在大模型平台这个语境下,它们另有所指。
我上网查了一圈文档,还顺手翻了下豆包大模型的说明,终于搞懂了这两个玩意的真实含义,来简单翻译一下——
什么是 RPM?
在 AI 模型里,RPM 不是转速,而是 Requests Per Minute,也就是每分钟最多能发多少次请求。
打个比方,如果你用的是一个 ChatGPT 接口,每问一次问题就是一个请求。那这个 RPM=1000,就意味着你每分钟最多能发 1000 次请求。
这其实就是一个限流措施,平台怕你刷太猛,把服务搞挂了,就给你定个请求频率上限。
比如 L0 级别用户就是每分钟最多 1000 个请求,高级用户可能可以到几万。
什么是 TPM?
TPM 全称是 Tokens Per Minute,也就是每分钟最多处理多少个 token。
这里的 token,可以理解为模型的“处理单位”,不是一个字,而是一个词片段。比如:
- “你好” 可能是 1 个 token,
- “Hello world!” 可能是 2~3 个 token,
- 你扔给模型一个 1000 字的文章,可能会被切成 1500~2000 个 token。
所以 TPM=50000 的意思是:你每分钟发给模型的内容 + 模型给你的回复,加起来不能超过 50000 个 token。
再打个比方,如果你一次请求用了 2000 个 token,那你每分钟最多也就发个 25 次,哪怕你 RPM 足够。
RPM 和 TPM 是两道限速器
可以这么理解: 🚗 RPM = 你一分钟最多可以发多少次“问题” 📦 TPM = 你一分钟总共能发多少“字数”(准确来说是 token)
模型平台就靠这两套机制来给用户划等级、控制消耗,防止有人刷接口刷得太猛,或者滥用资源。
豆包、硅基流动这些平台为什么都用这个?
很简单,因为大模型服务不是按次数收费,而是按 token 收费的。token 越多,意味着你消耗的计算资源越多。
举个很直观的例子:
- 你问一句“你是谁?”——模型处理快,token少。
- 你贴一篇一万字的小说说“帮我续写”——模型处理慢,还吃资源。
所以限制 token 就等于限制成本。而限制请求次数是限制频率,防止打爆系统。
那我怎么知道是不是“够用”?
这得看你怎么用这个模型了。如果你:
- 只是偶尔问两句,完全够用。
- 用它做接口服务(比如给 App 提供 AI 答案),那 L0 的额度可能不够,要升等级。
- 写爬虫自动生成内容?这时候 token 用量会飙升,更得注意 TPM。
你可以通过每次请求后查看“本次消耗了多少 token”这个字段,慢慢估算自己的使用习惯,再决定要不要升级套餐。
总结一句话:
RPM 是每分钟请求次数,TPM 是每分钟处理字数(准确来说是 token 数量),都是平台用来控制你使用大模型资源的“流量计”。
如果你跟我一样是在探索新平台、尝试免费额度,那知道这两个值能让你避免踩坑,也能判断什么时候需要付费升级。
本文由“代码简单说”出品,专注讲清科技背后的小细节。觉得有帮助的话,欢迎点赞、收藏、关注专栏~ 有更多国产大模型实测、工具盘点的干货等你来看!
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-12-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号