机器学习从入门到精通

机器学习从入门到精通

javpower
发布于 2026-06-15 16:38:48
发布于 2026-06-15 16:38:48
机器学习从入门到精通
很多人学机器学习,半途而废通常发生在两个节点:一是被繁杂的数学公式堵在门外,二是学了一堆算法却串不成一条线。
碎片化的学习不仅低效,还会让人产生“懂了却又没完全懂”的错觉。为了解决这个问题,我用30讲的篇幅,把机器学习从底层数学到前沿大模型,再到项目实战的完整链路梳理了一遍,并在公众号逐一发布。
今天这篇文章,是把这30讲的内容做一个系统的汇总,方便大家收藏查阅,作为学习时的案头索引。
壹 / 知识体系路线图
这30讲不是知识点的罗列,而是遵循一条严格的学习路径。建议在学习前,先通过下面的路线图建立全局观:
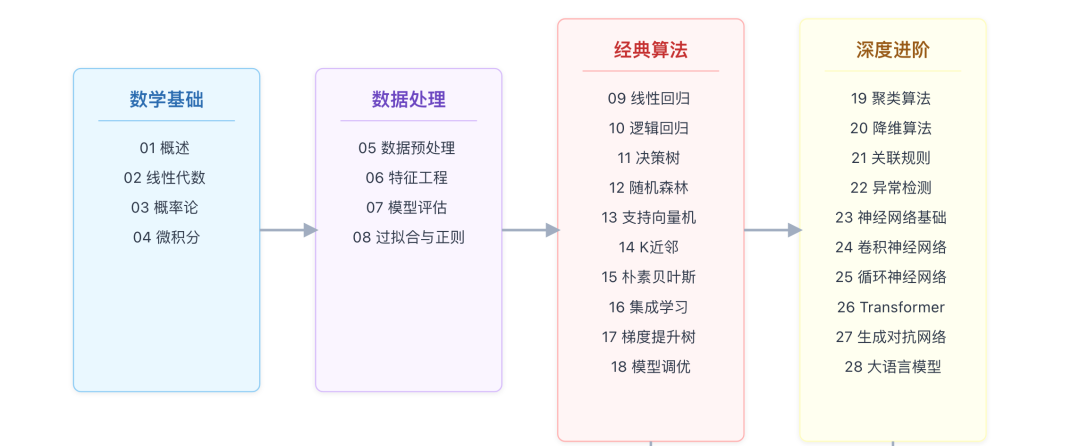
贰 / 30讲内容全景图
第一部分:数学与数据基石
跳过数学,算法永远是黑盒。这部分帮你补齐核心概念,并掌握数据清洗与特征构造的实战技巧。
- 01 机器学习概述 —— 什么是机器学习、发展历程、分类、应用场景
- 02 线性代数基础 —— 向量、矩阵、运算、特征值分解
- 03 概率论基础 —— 概率、条件概率、贝叶斯定理、概率分布
- 04 微积分基础 —— 导数、梯度、链式法则、梯度下降
- 05 数据预处理 —— 缺失值、异常值、标准化、编码
- 06 特征工程 —— 特征选择、特征提取、PCA
- 07 模型评估与选择 —— 交叉验证、ROC曲线、AIC/BIC
第二部分:经典算法与模型调优
从线性模型到非线性模型,从单模型到集成策略。不仅要懂算法原理,还要知道如何解决过拟合、如何把模型调到最优。
- 08 过拟合与正则化 —— 偏差方差、L1/L2正则化、早停
- 09 线性回归 —— 最小二乘法、梯度下降、正则化
- 10 逻辑回归 —— Sigmoid、交叉熵、多分类
- 11 决策树 —— 信息增益、基尼指数、剪枝
- 12 随机森林 —— Bagging、特征随机、OOB评估
- 13 支持向量机 —— 最大间隔、核函数、软间隔
- 14 K近邻 —— 距离度量、K值选择、KD树
- 15 朴素贝叶斯 —— 贝叶斯定理、拉普拉斯平滑
- 16 集成学习 —— Bagging vs Boosting、AdaBoost、Stacking
- 17 梯度提升树 —— XGBoost、LightGBM、CatBoost
- 18 模型调优 —— 网格搜索、随机搜索、贝叶斯优化
第三部分:无监督学习与深度网络
跳出监督学习的框架,掌握无监督数据的洞察方法,并系统学习从神经网络到当前主流大模型的结构与原理。
- 19 聚类算法 —— K-Means、DBSCAN、层次聚类
- 20 降维算法 —— PCA、t-SNE、UMAP
- 21 关联规则 —— Apriori、FP-Growth
- 22 异常检测 —— 孤立森林、LOF、One-Class SVM
- 23 神经网络基础 —— 感知机、激活函数、反向传播
- 24 卷积神经网络 —— 卷积、池化、经典架构
- 25 循环神经网络 —— RNN、LSTM、GRU
- 26 Transformer —— 自注意力、位置编码、BERT
- 27 生成对抗网络 —— GAN、DCGAN、StyleGAN
- 28 大语言模型 —— GPT、BERT、微调、RLHF
第四部分:工业级项目实战
告别纸上谈兵,用真实的数据集跑通全流程,检验从数据处理到模型部署的综合能力。
- 29 图像分类实战 —— CIFAR-10、迁移学习、部署
- 30 NLP实战 —— 文本分类、情感分析、BERT应用
叁 / 学习建议
对于零基础的学习者,建议严格按照1到30讲的顺序推进,不要跳跃,尤其是前7讲的基础部分,直接决定了后面算法学习的深度。
对于有一定基础的开发者,可以直接根据自己的薄弱环节进行针对性查漏补缺,重点攻克第16至18讲的集成策略与调优,或者第26至28讲的深度学习与大模型架构。
肆 / 专栏直达
点击下方链接,即可跳转对应章节阅读。建议将本篇汇总文章收藏,作为后续学习的目录。
- 第 1 章:机器学习概述
- 第 2 章:线性代数基础
- 第 3 章:概率论基础
- 第 4 章:微积分基础
- 第 5 章:数据预处理
- 第 6 章:特征工程
- 第 7 章:模型评估与选择
- 第 8 章:过拟合与正则化
- 第 9 章:线性回归
- 第 10 章:逻辑回归
- 第 11 章:决策树
- 第 12 章:随机森林
- 第 13 章:支持向量机
- 第 14 章:K近邻
- 第 15 章:朴素贝叶斯
- 第 16 章:集成学习
- 第 17 章:梯度提升树
- 第 18 章:模型调优
- 第 19 章:聚类算法
- 第 20 章:降维算法
- 第 21 章:关联规则
- 第 22 章:异常检测
- 第 23 章:神经网络基础
- 第 24 章:卷积神经网络
- 第 25 章:循环神经网络
- 第 26 章:Transformer
- 第 27 章:生成对抗网络
- 第 28 章:大语言模型
- 第 29 章:图像分类实战
- 第 30 章:NLP实战
系统学习从来不是一件轻松的事,但完整的知识结构会为你节省大量盲目摸索的时间。希望这30讲内容,能成为你掌握机器学习的可靠垫脚石。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号