Elasticsearch simdvec 深度解析:在内存的钢丝上行走,实现向量吞吐量翻倍

Elasticsearch simdvec 深度解析:在内存的钢丝上行走,实现向量吞吐量翻倍

点火三周
发布于 2026-06-12 16:40:13
发布于 2026-06-12 16:40:13
Elasticsearch simdvec 深度解析:在内存的钢丝上行走,实现向量吞吐量翻倍
想要亲身体验向量搜索?您可以使用这份自学式实践教程来探索搜索AI。现在就可以开始免费的云试用,或者在您的本地机器上试用 Elastic。
Elasticsearch 的 simdvec 在向量距离计算方面比串行代码快了高达 50 倍。要达到这一目标,需要解决四个连续的硬件瓶颈,每一次的修复都揭示了下一个瓶颈。本文将深入探讨级联展开(cascade unrolling)、批量预取(batch prefetching)、维度轴展开(dim-axis unrolling)以及一项结构性重构,后者被证明是最大的胜利,这些优化共同带来了高达 2 倍的吞吐量提升。本文是“我们如何构建 Elasticsearch simdvec,使其成为世界上最快的向量搜索之一”一文的配套内容。
Elasticsearch 中的每一次向量搜索查询,无论是分层可导航小世界(HNSW)遍历、倒排文件(IVF)扫描,还是重排序过程,最终都归结为同一个问题:在一次查询中,计算数百万次向量之间的距离。
Elasticsearch simdvec 是 Elasticsearch 中所有向量距离计算的引擎。计算向量之间的距离在指令执行方面是一个简单的操作;例如,一个点积仅仅是加法和乘法的组合。但要让这些操作变得极快,需要深入了解现代 CPU 的工作原理、不同的指令集架构(ISA)所提供的功能,以及它们的异同。
在本文中,我们将深入探讨 simdvec 如何优化内存访问。针对 x86 和 ARM 平台手动优化的单指令多数据(SIMD)内核,可以在几个 CPU 周期内完成向量距离计算;SIMD 内核通常受限于每个 CPU 周期能够获取和消耗的数据量,而不是能够执行的操作数量。
例如,一个 1024 维的 float32 嵌入向量,进行一次点积运算需要 1024 次乘加操作。一个 AVX-512 处理器可以将 16 个浮点数打包到每个 512 位寄存器中,并且每个周期可以发出两个融合乘加操作。以持续速率计算,在 4GHz 的 CPU 上,一次点积运算的吞吐量只需 32 个周期,即每个向量 8 纳秒。搜索一百万个候选向量意味着执行该内核一百万次,通过 CPU 流传输大约 4GB 的向量数据。硅芯片可以在总共 8 毫秒内完成数学运算;但问题在于,如何在这么短的时间内交付这 4GB 数据!这是一项不可能完成的任务,但我们能做到多接近呢?
本文的其余部分将探讨我们如何尽可能多地通过硅芯片处理向量。这就像走钢丝:每一步让我们更接近峰值吞吐量,就会收紧下一步的限制。我们按顺序应用了以下四项优化:
- 1. 级联展开(Cascade unrolling):通过独立的累加器链最大化 FMA 端口利用率。
- 2. 批量处理和预取(Batch processing and prefetching):通过提前预取数据来隐藏内存延迟。
- 3. 维度轴展开(Dim-axis unrolling):避开 L1d 缓存对于 2 的幂次维度造成的别名冲突。
- 4. 查询加载提升(Query load hoisting):消除每个文档中冗余的查询操作。
端口、管道、延迟、吞吐量……天哪!现代 CPU 如何执行 SIMD 向量操作
现代 CPU 能够在一个周期内发出多个操作,因为它们的硅芯片中实现了多个执行单元;操作通过被称为 x86 上的端口(在 ARM 上是执行管道,简称管道,参见 ARM 文档)的接口进行调度。端口并行处理不同类型的工作:一些内存加载和存储,一些整数算术运算,一些浮点数学运算。
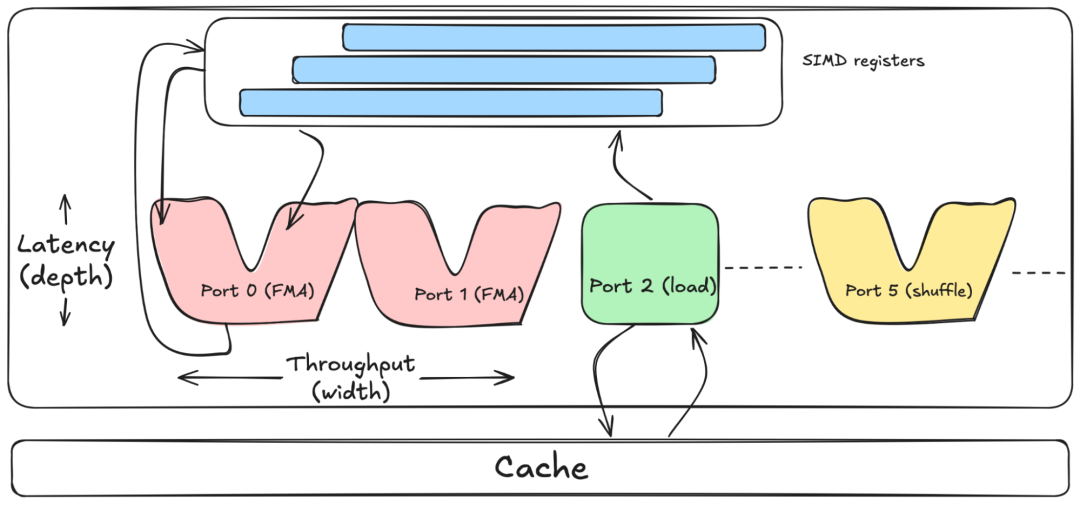
一张图表,显示了 SIMD 寄存器连接到标记为 FMA、加载和混洗的端口,下方是缓存。
端口可以处理的任何操作都有两个重要属性:延迟和吞吐量。延迟是指单个操作产生结果所需的 CPU 周期数;吞吐量是指每个周期可以开始的此类操作数量。吞吐量与给定操作可用的端口数量密切相关:如果 CPU 有两个可以执行 FMA 的端口,那么在理想条件下,它每个周期最多可以发出两个独立的 FMA 操作,峰值吞吐量为每周期两个。
以 AVX-512 为例。现代 Intel CPU 上的大多数 FMA 指令通常具有大约四个周期的延迟,并且可以在两个支持 FMA 的端口中的任意一个上执行。从冷启动开始,第一个结果会在四个周期后出现,但一旦管道满载,只要它们之间没有依赖关系,每个周期就可以开始两个新的 FMA 操作。
我们的第一步目标是最大限度地利用端口数量,平衡端口使用并考虑延迟。
级联展开:最大化 FMA 端口利用率
根据前面的例子,如果 FMA 指令的延迟为四个周期,吞吐量为两个周期,那么 CPU 在任何时刻都可以保持约八个 FMA 操作处于飞行中(已发出但尚未完成)。当然,这只有在有八个独立操作可用时才能发生。
如果我们将它们串联起来,每个 FMA 操作都等待前一个操作的结果,那么 CPU 将以延迟(每四个周期一个 FMA)而不是吞吐量(每周期两个)运行,速度比硬件所能提供的慢高达 8 倍。
很容易意外地形成一个链;例如,一个朴素的向量点积实现可能看起来像 foreach (i) { acc = acc + x[i]*y[i] }。由于只有一个累加器,每次迭代都依赖于前一次迭代的结果。一个自然的反应是考虑展开循环:如果我们需要保持 N 条指令在飞行中,我们就发出相同的指令 N 次。编译器甚至为此提供了特定的指令;例如,#pragma unroll。
循环展开在 simdvec 代码中被广泛使用,以利用现代 CPU 的内部并行性;#pragma unroll 的问题在于它只是对编译器的提示,而不是指令。此外,它的效率取决于编译标志和编译器启发式算法,因此编译器可能决定不展开,或者执行不完美的展开。例如,当我们查看编译器为这个循环生成的汇编代码时,我们发现它被展开了,但依赖链仍然存在。对于精确控制或可移植性,仍然需要手动展开,但这难以阅读和维护。
C++ 模板和元编程
C++ 模板允许您编写带有占位符类型或值的泛型代码,编译器会在编译时填充这些占位符。只需编写一次函数模板,编译器就会为每次使用它的一组参数发出一个专门的副本。占位符可以是类型(例如 float 与 int,或寄存器类型,如 __m512i 或 uint8x16_t)、函数、编译时整数……我们最常使用最后这种形式:通过整数 N 参数化的模板允许我们生成 N 个并行累加器或 N 个内循环体的副本。元编程本质上是编写代码的代码:它利用编译器在编译时执行计算,没有运行时成本。
我们的主要工具是 apply_indexed<N>,这是一个编译时函数,在展开时会发出 N 条语句:
1
2
3
4
5
6
7
template <int N, typename F, int I = 0>
static inline void apply_indexed(F&& f) {
if constexpr (I < N) {
f(std::integral_constant<int, I>{});
apply_indexed<N, F, I + 1>(std::forward<F>(f));
}
}
if constexpr 是一个编译时分支,使得 apply_indexed 成为编译时递归;编译器将解析 constexpr 并实例化模板的下一次迭代。所有内容都由编译器处理;不会发出运行时分支。
我们使用 apply_indexed<N> 来实现级联展开:
1
2
3
apply_indexed<N>([&](auto I) {
fma(acc[I], x[i + I*stride], y[i + I*stride]);
});
我们将其展开为级联:首先是 N=4 个独立的累加器链,对于任何半尺寸的尾部,降至 2 个,然后对于最终的标量尾部,降至 1 个。这使得我们的内核和 CPU 相比 #pragma unroll 获得了 +11–13% 的加速(所有详细信息和完整数据可在上述链接的 PR 中找到)。编译器只能帮助我们到此为止;通过 C++ 模板实例化实现的泛型编程,是我们在不同内核和 ISA 之间保持其极高效率、紧凑和易于管理的关键。
批量处理和预取:隐藏内存延迟
展开解决了单个向量计算中的指令级并行性问题,但并未利用批量处理的优势。
Elasticsearch 并非将一个向量与一个查询进行评分;仅 HNSW 遍历就需要为每个查询评分数百个邻居。批量评分(一个查询匹配多个文档)既带来了新问题,也提供了解决这些问题的工具。
我们评分的向量通常分散在内存中,产生不规则的访问模式,这使得 CPU 缓存和硬件预取器难以预测。这增加了 CPU 所需数据不在快速 L1d 缓存中,而必须从更远的地方获取的可能性(缓存未命中)。典型的成本范围从 L1d 命中约五个周期,到数据必须来自 RAM 时超过 200 个周期。
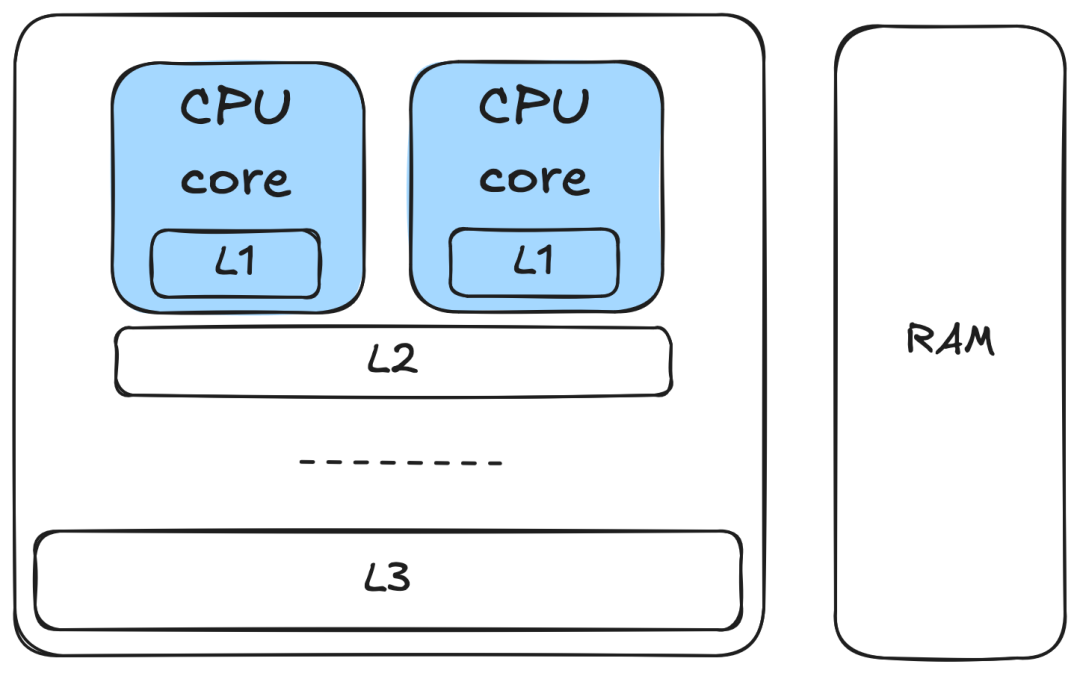
一张图表,显示了两个带有 L1 缓存的 CPU 核心,共享的 L2 和 L3 缓存,以及独立的 RAM。
即使我们最大化了加载端口的占用率,如果这些端口因等待数据而停滞,计算端口也会闲置。我们通过级联展开饱和的 FMA 吞吐量将因此浪费。将数据从内存检索到 L1d 缓存非常耗时,特别是如果我们需要遍历整个内存层次结构直至 RAM。幸运的是,由于我们知道将要对多个向量进行评分,因此我们可以用下一个向量(或多个向量)来预热 CPU 缓存,从而有效地减少或隐藏内存访问延迟。
批处理也有助于解决指令延迟问题,原因与级联展开相同:N 个独立的向量流为 CPU 提供了 N 个独立的累加器链以进行交错,从而隐藏了我们之前讨论的 FMA 管道延迟。
这就是为什么我们在批量评分中添加了批次(从 int7 开始,后来扩展到所有数据类型);这与级联展开的机制相同,但应用于向量之间。我们不是一次处理一个向量,而是同时处理 N 个向量,在此期间,我们预加载(预取)下一个 N 个向量的数据。这应该有助于预取和指令延迟,在许多情况下确实如此:例如,对于 int7,我们立即看到了比未展开的批量处理 +20–50% 的改进(所有详细信息和 JMH 基准测试都可以在链接的 PR 中找到)。但当我们尝试将其应用于所有批量函数时,我们注意到它引入了新的问题/限制。
物极必反:为什么突发预取会导致行填充缓冲区溢出
预取只有在内循环需要数据之前,缓存行能到达 L1d 缓存时才有效。我们最初的尝试是在批处理边界处发出下一个批次的所有预取请求,这是一个突发操作,根据内核的不同,会有大约 28 到 100 个软件预取指令连续发出。
处理器每个核心都拥有有限的行填充缓冲区(LFB);这直接对应于核心可以同时跟踪的最大未完成缓存未命中数。例如,Sapphire Rapids 的 LFB 只有 16 个条目。如此大的突发预取会使 LFB 溢出,多余的预取请求会被悄无声息地丢弃。内循环最终会因为等待我们以为已经在路上的缓存行而停滞。
解决方案是将预取操作分散到内循环中。在批处理边界,我们只发出少量头部突发预取,足以覆盖内循环将消耗的第一批缓存行,然后将剩余的预取操作分散到迭代中,每次迭代拉入下一批的缓存行。预取总数不变,但 LFB 的峰值占用率下降了一个数量级。缓存行在大约一个外部迭代之前到达,从而隐藏了 L2 到 L1 的传输延迟,并且 L2 流预取器与稳定的步长配合得比边界突发更好。头部 + 分散预取首先应用于 int8,然后扩展到 int7 和其余内核,性能提升高达 +30%。
自作自受:为什么批处理会降低 2 的幂次维度上的性能?
正确的预取量应该能带来高吞吐量,隐藏大部分内存延迟。而且在大多数情况下确实如此。当向量数据以稀疏、随机的方式高效访问时,它的效果非常好。但是,当我们尝试在四批次的批量处理中并行处理连续的文档,并且维度是 2 的幂次时,性能却急剧下降。
N 路关联缓存如何导致 2 的幂次冲突
CPU 缓存被组织成缓存行和组。缓存行是数据在内存层次结构中传输的单位;在 ARM 和 x86 上,它都是 64 字节长。每个缓存行精确地映射到一个缓存组,并且每个组可以容纳固定数量的缓存行。这被称为N 路关联缓存。
一个有用的类比是哈希表,其中每个桶恰好有 N 个槽位。多个内存地址可能映射到同一个桶(组),但一旦所有 N 个槽位都被占用,插入新条目就会强制驱逐一个现有条目。
让我们举一个具体的例子。Sapphire Rapids L1d 缓存是 48 KiB,12 路关联。每条缓存行 64 字节,这意味着我们有 768 条缓存行,组织成 64 个组。缓存行的组索引(“哈希表键”)由地址的 [11:6] 位决定(换句话说,由 (address / 64) % 64) 决定)。
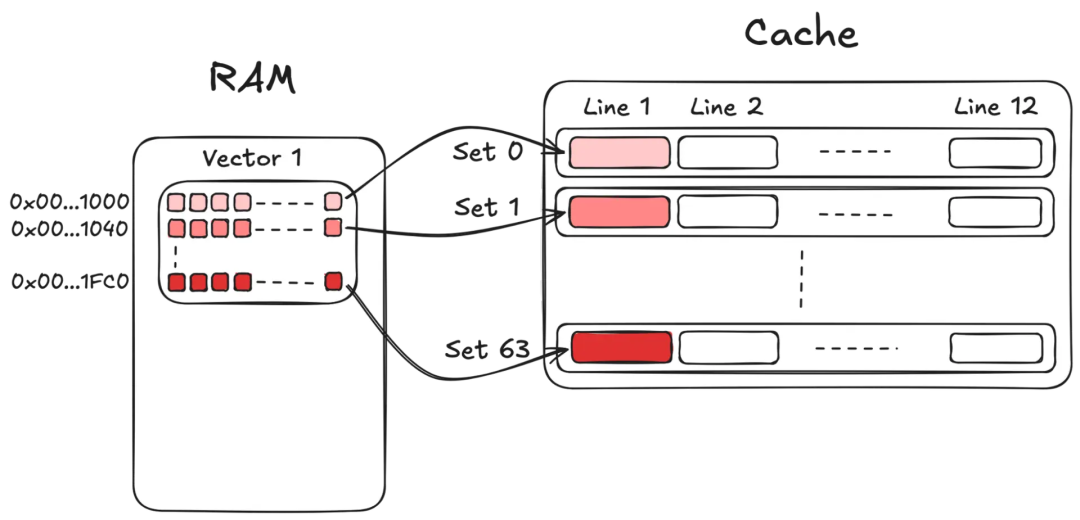
一张图表,显示了来自 RAM 的数据块(标记为 Vector 1)如何映射到缓存组和缓存行。
假设我们有一个 1024 维的 float32 嵌入向量,它在内存中连续存储。每个向量占用 dims * sizeof(float32) = 4096 字节,或者正好 64 个缓存行。因此,连续向量之间的步长是 4096 字节。由于 4096 字节恰好是 64 个组索引空间的一次完整环绕,所以组索引完美地循环:每个向量的第 i 个缓存行都映射到完全相同的缓存组。
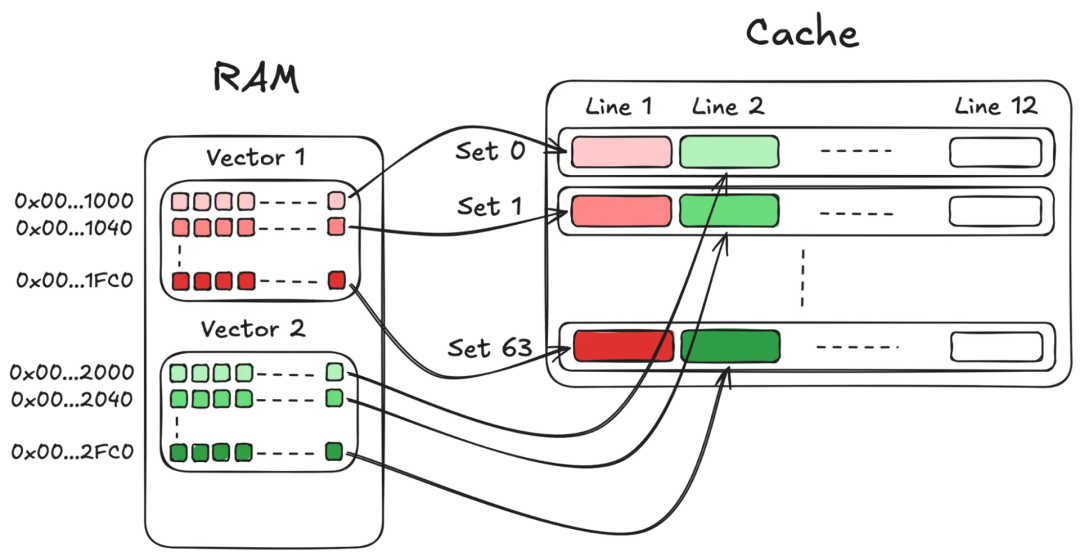
一张图表,显示了来自两个 RAM 向量的数据块如何使用红色和绿色块映射到缓存组和缓存行。
常见的 2 的幂次向量尺寸会产生以字节为单位的 2 的幂次步长,它能被 64 组整除,因此它们以这种方式与缓存产生病态的交互。同时处理一批 N 个具有此类维度的文档会加剧这种情况:当它们落入相同的 L1d 组时,它们会导致冲突和缓存抖动。
通过减少批处理并行度来修复缓存别名
我们首次深入研究这种效应是在开发 bf16 数据类型的内核时。在为新内核尝试不同的实现和 batches 值时,我们进行了大量的基准测试,这证实了以下假设:对于 2 的幂次维度大小,连续向量的步长映射到相同的缓存组,并且交错多个加载流会导致逐出。因此,我们立即采取的修复措施很简单:在具有顺序访问的函数(*_bulk)上设置 batches=1,以避免 L1d 缓存组别名。
然而,我们知道这只是权宜之计;批量处理和更宽的并行性将有助于解决例如延迟等问题,因此我们希望在不重新引入缓存冲突的情况下实现这些目标。
沿不同轴展开:在不产生别名的情况下使 FMA 管道饱和
batches 在文档之间并行化,但这不是我们唯一的可用轴。我们可以沿着向量维度轴进行展开。我们不是并行处理多个向量,而是并行处理同一向量对的多个独立块。
因此,我们引入了 unroll_dim。至关重要的是,通过保持 batches=1,我们完全避开了缓存组别名陷阱,并且 unroll_dim 保持 FMA 管道饱和,而无需额外的并行文档加载来触发最初的别名。
在某些情况下,它的效果非常好(点积的性能提升为 +35–65%,您可以在上述 PR 中看到),但在其他情况下,增益比我们预期的要小(欧氏距离的性能提升约为 +10%)。与其他情况一样,所有详细信息和 JMH 基准测试都可以在链接的 PR 中找到。
不要重复自己:提升查询加载以消除冗余的端口压力
unroll_dim 在欧氏距离上获得的微薄收益表明,批量循环中仍然隐藏着另一个瓶颈。我们发现的是批量函数模板中隐藏的结构性低效:现有的批量评分器为每个文档调用单对评分器,在每个外部步骤中重新加载查询元素 N (4) 次。
对于某些函数,我们还多次不必要地重复与查询元素相关的操作。例如,int8 欧氏距离内核(sqri8)在每个外部步骤中调用 vpmovsxbw 符号扩展指令四次。
将查询加载和操作从每个文档循环中提升出来,将查询元素的 L1D 带宽减少了 4 倍;对于 sqri8,它消除了每个外部步骤中四个 vpmovsxbw 符号扩展指令中的三个。回想一下,吞吐量取决于端口可用性:vpmovsxbw 只能在一个端口上执行(Sapphire Rapids 上的端口 5),因此每个步骤发出四个副本会完全饱和该端口;仅符号扩展本身就是瓶颈。
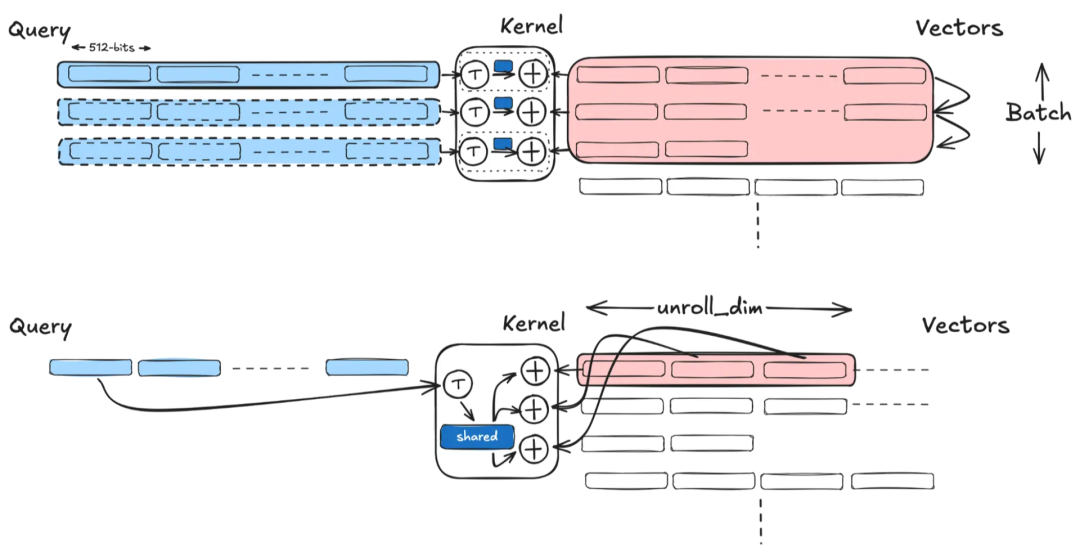
一张图表,比较了两种计算方法:一种显示批量查询由内核处理成向量,另一种显示共享内核跨查询展开。
即使没有特定于查询的操作需要提升,这种改变也很重要。对于 doti8,vpdpbusd 在两个端口上执行(Sapphire Rapids 上的端口 0 和 5),延迟为五个周期,因此我们需要大约 10 个独立的飞行中操作才能达到峰值吞吐量。通过提升查询加载,内循环变得依赖于每个批处理元素的一个累加器链。冗余工作消除后,unroll_dim=2 可以通过沿维度轴添加独立的链来填充延迟窗口。
这种结构性重构给我们带来了显著的加速:点积提升了 +19–22%,欧氏距离提升了 +44–51%(所有详细信息和完整数据可在链接的 PR 中找到)。
为了完美落地,有时需要退一步
并非所有的优化都能存活下来。毕竟,在引入 unroll_dim 之后,基准测试表明它并非总是有效:对于某些内核和访问模式,额外的寄存器压力和代码复杂性并没有带来任何可衡量的收益。我们可以将其保留,设置 unroll_dim=1(功能上是空操作),但无用的脚手架会成为技术债务,使后续的修改更难理解。因此,我们在它没有带来收益的地方将其移除,从而保持了代码的整洁。
在走钢丝时,有时后退一步才是正确的选择。
关键要点:优化向量搜索的低层内存访问
本文中的每一次优化都遵循相同的模式:解决一个瓶颈,然后揭示下一个。级联展开使 FMA 端口饱和,从而暴露出内存延迟。批量处理和预取隐藏了该延迟,进而揭示了 L1d 组别名。维度轴展开避开了别名问题,从而揭示了冗余的查询工作。最终,消除冗余才让整个管道得以顺畅运行。
simdvec 内核的快速运行并非依赖于单一的优化。每一次改进都只是改变了瓶颈,而非彻底消除它,并且每一步都可能暴露出新的、意想不到的限制。在这个层面上,内存抽象只是一种错觉:性能取决于理解 CPU 实际在做什么,而不仅仅是模型所暗示的。唯一的出路是测量、理解并重新平衡。
优化项 | 收益 |
|---|---|
级联展开(对比 #pragma unroll) | +11-13% |
批量处理 / 预取(int7) | +20-50% |
头部 + 分散预取 | 高达 +30% |
维度轴展开(点积) | +35-65% |
查询加载提升(点积) | +19-22% |
查询加载提升(欧氏距离) | +44-51% |
这是 Elasticsearch simdvec 深度解析系列的第一部分。下一次,我们将探讨代数重写如何让我们完全避开 CPU 限制。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号