Harness Engineering落地前,先想清楚这几个问题

Harness Engineering落地前,先想清楚这几个问题

腾讯云开发者
发布于 2026-06-12 12:02:36
发布于 2026-06-12 12:02:36
关注腾讯云开发者,一手技术干货提前解锁👇
传统数据中台往往系统功能强大,但门槛也是真的高。对于熟悉数据分析、SQL、指标体系的用户来说,数据中台是效率工具。但对于更多的新手/小白用户来说,它更像是一套"需要先学会使用,才能开始解决问题"的系统。用户需要知道数据在哪、表怎么关联、SQL 怎么写、结果怎么看,甚至还要理解图表配置和看板搭建逻辑,上手成本那是相当高。
近两年 AI 带来了近乎完美破局路径:自然语言提问 → 生成 SQL\Python → 查询数据 → 展示数据 → 可视化图表。这条链路的价值不只是"帮用户写 SQL",更重要的是把原本需要专业知识才能完成的完整数据分析流程,改造成了更自然的对话式交互,门槛大幅降低。Dola 将这条链路跑通之后,在持续打磨产品体验的过程中,前端很快暴露出两类全新的问题:一类是"AI产品形态变了,传统前端架构跟不上";另一类更隐蔽——当我们开始大量用 CodeBuddy、Cursor来协作开发时,发现多年来习以为常的"优雅写法",在AI Coding协作中反而成了拖累。这两类问题逼着我重新思考前端在 AI 时代的定位。结论很简单,也是这篇文章想聊的两件事:
- 第一件事:服务好 AI 产品 —— 当产品形态变了,前端架构必须跟着变
- 第二件事:服务好 AI Coding —— 当协作对象变了,编码范式也有必要跟着变
插个题外话:
随着AI破局而出世的,还有我们PCG大数据平台部的新一代数据分析AI助手——Dola

Dola是一款基于Agentic AI能力开发的数据分析助手:用户只需要引入个人的数据表,就能得到一枚专属的AI分析师
它不仅能够完成日常的取数、跑数等基础任务,还能自主规划并执行复杂场景的数据分析,例如异动归因、画像对比分析、股票基金回测、房价预测等。Dola可以自行编写SQL、纠正SQL错误、执行查询、使用Python进行数据处理与可视化,并最终生成一份完整的分析报告。全程无需编写一行代码,只需通过自然语言对话,你就能拥有一个全自动工作的“数据小黑工”。
这里以1个股票回测的例子看看dola的效果:

可以看到dola在接收到“金叉买入法回测”这个问题之后,首先能自己生成一个计划,包括了需要进行的数据准备、策略实现、回测实现和结果分析等详细内容。
在按照自己的计划执行完毕后,dola最终产出回测结果,完成可视化并进行深入分析总结,产出一份完整的回测报告。
同时还可以将分析的报告做成一个美观的可视化插画/静态网页/看板,大大增加了报告的可读性:
(上图左为Dola生成的插画报告,右为静态网页。仅做样例展示参考,不构成分析建议)
这里只是以股票回测这样一个比较复杂的案例场景展开,大家应该可以想象到,在工作场景中,Dola对于日常数据分析工作的提效程度是显而易见的。
回到本期主题,对前端开发新范式感兴趣的同学欢迎接着往下阅读:
01
服务好 AI 产品之一:AI 数据分析可视化优化
这条链路里,"自动生成可视化图表"是用户感知比较强的环节。因为用户最终并不是为了看一段 SQL,也不是为了看一张原始表格,而是希望快速理解分析结论。图表推荐得准不准、展示得清不清楚,直接决定了用户对"AI 数据分析"的第一印象。
1.1 让大模型直接生成图表配置?
最自然的做法,是让大模型在生成完 SQL、拿到数据之后,再吐一份图表配置出来。实际尝试之后,碰到两个绕不开的问题:生成速度慢、复杂图表配置容易出错。
所以我们考虑把策略改成:工程化推荐 + 大模型微调。也就是前端基于已有上下文快速给出推荐配置,用户立刻就能看到一张相对合理的图;如果不满意,再让 AI 介入修改。这样既能拿到工程化的速度和稳定性,也能保留 AI 的灵活性。
1.2 主流图表推荐库为什么不够用?
要做工程化推荐,第一反应是看看业界已有方案能不能直接用。我们调研了 AntV/AVA 这类主流图表推荐库,结论是——在我们的场景下不太够用。这类库的核心思路是完全基于数据特征推荐图表:看字段类型、看字段数量、看基数、看分布,然后匹配规则。
这个思路在传统 BI 场景里是合理的。用户上传一份 Excel,或者手动选择了表,系统不知道用户在想什么,只能从数据特征出发猜一个相对合理的图表。但放到 AI 对话数据分析链路里,这套假设就不太成立了。
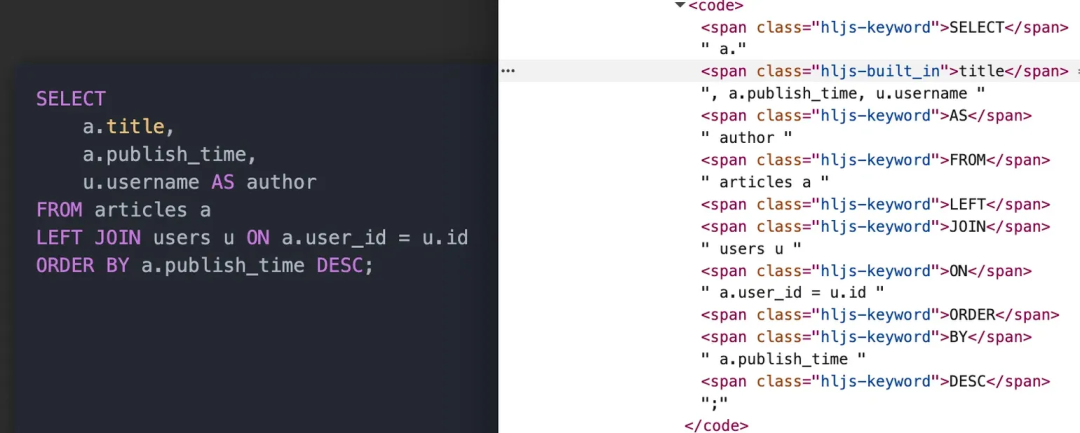
比如 AI 生成了一段 SQL。
SELECT
dt AS date,
channel,
SUM(gmv) AS gmv,
COUNT(DISTINCT order_id) AS order_count,
SUM(paid_order_cnt) / SUM(uv) AS conversion_rate
FROM dwd_trade_order
WHERE dt BETWEEN '2026-04-01' AND '2026-04-30'
GROUP BY dt, channel
ORDER BY gmv DESC
LIMIT 10;查询结果包含 date 、 channel 、 gmv 、 order_count 、 conversion_rate 五个字段。仅看字段类型,可以判断出:一个时间字段、一个分类字段、三个数值字段。那应该推荐什么图?
用户想看 GMV 趋势?看不同渠道的 GMV 对比?看转化率随时间的变化?还是看 GMV 和订单数的关系?
只看数据特征,传统库只能挑一个"最常见"的方案,比如默认按时间画折线图,把所有数值字段都画上去。但这不一定是用户真正想看的。也就是说:仅凭数据特征不一定能准确推断出用户的分析意图,这导致图表类型、维度、度量的推荐准确率都偏低。
1.3 其实我们手里其实有更多上下文
当我重新审视这条链路后发现,和传统 BI 场景相比,AI 对话数据分析场景有个巨大的优势:前端拿到的上下文更完整。在图表绘制之前,除了数据本身,对话上下文里还能拿到 生成数据的 SQL,以及 用户的原始 prompt。这正好能增强传统方案里"用户意图"识别这块的不足!
SQL 里藏着维度、度量和意图
SQL 不只是拿数据的工具,它本身就是一份结构化的分析意图描述。
- 举几个直接的例子:GROUP BY dt → 用户想看的"维度"很可能就是 dt ,而不是其他分类字段
- ORDER BY gmv DESC LIMIT 10 → 这是典型的 TopN 分析,柱状图比折线图更合适
- SUM(gmv) 、 COUNT(DISTINCT user_id) → 这些聚合函数本身就是"度量",不需要再去字段里猜
- WHERE dt BETWEEN '2026-04-01' AND '2026-04-30' → 时间范围明确,趋势分析的可行性高
- 出现 SUM(a) / SUM(b) → 计算字段往往是核心关注指标,应该优先作为主度量
这些信息在传统 BI 场景里完全拿不到,但在 AI 链路里缺是天然可见的。
用户 prompt 里藏着分析目标
用户的原始问题里也经常包含意图关键词:
- “趋势”、“变化”、“最近一个月” → 倾向时间序列;
- “对比”、“哪个更高”、“排名” → 倾向分类对比;
- “占比”、“构成”、“比例” → 倾向饼图、堆叠图;
- “分布”、“区间” → 倾向直方图、箱线图;
- “下降最明显”、“异常” → 倾向带标注的对比图。
同样是查 GMV,用户问"最近一个月各渠道 GMV 趋势"和"最近一个月哪个渠道 GMV 下降最明显",SQL 结果可能完全一样,但期望的图是不一样的。如果只看数据,这两种意图就被抹平了。如果把 prompt 也纳入推荐,它们就能被区分。
1.4 三维评分推荐引擎
基于这个思路,我尝试开发了图表三维评分推荐工具。核心思路是维护一套评分机制,把 数据特征 + SQL 特征 + Prompt 特征 综合起来,给候选图表打分,最终推荐得分最高的图表类型并生成配置。
评分规则覆盖时间趋势、分类对比、占比分析、TopN、分布、相关性、多维探索等典型分析任务,每条规则都会从三个维度出发综合判断。
举个简化的规则示例——时间趋势规则:
- 数据特征:存在时间字段,且时间点数量适中 → +分;
- SQL 特征: GROUP BY 中包含时间字段,或 ORDER BY 时间字段 → +分;
- Prompt 特征:包含"趋势"、“变化”、“增长”、"下降"等关键词 → +分;
- 反向条件:分类字段基数极高且 prompt 偏向对比 → -分。
分类对比规则类似:
- 数据特征:存在低/中基数分类字段 + 至少一个聚合度量 → +分;
- SQL 特征: GROUP BY category 、 ORDER BY metric DESC LIMIT N → +分;
- Prompt 特征:包含"对比"、“哪个”、“排名”、“TopN” → +分。
每条规则不会单独决定推荐结果,而是统一汇总到打分模型里,择优输出。
效果上,复杂多维数据场景下,推荐准确率从 55% 左右提升到近 90%,对维度和度量的识别准确性也明显提升。
1.5 几个有用的特色能力
在评分推荐之上,还做了一些工程层面的细节,体验差异其实主要来自这些地方。比如,支持交互式二次探索。再比如,数据量大的时候自动开启采样和缩略图导航、多度量量纲差异大的时候自动启动双 Y 轴、数值字段方差极大的时候自动启用对数坐标等,这些规则看似琐碎,但对最终展示效果影响很大。
在 Dola 项目中,如果对工程化推荐还是不满意,用户可以通过 AI 直接改配置——这时大模型只需要在已有配置基础上做局部修改,速度快、准确性也更可控。
做完这些之后我自己的体感是,AI 把自然语言变成 SQL、把 SQL 变成数据,已经干了最重的活。但用户最终看到的不是 SQL 也不是数据表,而是那张图。这一步与其再让大模型推一轮,不如交给前端用工程化的方式收尾——快、稳、准。
02
服务好 AI 产品之二:LLM 流式对话代码展示体验攻坚
这一章想聊的事其实可以用一句话概括:当产品形态从”静态展示“变成”流式增量输出“,渲染架构的底层假设也得跟着重写。下面是我们一路踩坑的过程。
2.1 Markdown 流式选中复制问题
最早的用户反馈很朴素——“AI 正在回答的时候我想把上一段复制出来,一松鼠标选区就没了”。这是早期 AI 大模型对话产品的通病,原因是传统 Markdown 解析工具并不是为流式输出设计的,在流式过程中频繁 re-render 导致 Selection API 引用失效。这个问题我们团队小伙伴通过在 Markdown 渲染层做增量输出解决了——让 DOM 在流式过程中尽量只追加、不重建。
以为就此结束,但很快发现代码块的增量渲染是另一个量级的难题。
2.2 代码高亮的增量渲染几乎无法实现
主流代码高亮库 highlight.js、Prism、Shiki 等,也都是为"已经写好的代码"设计的:每次调用都吐出一整棵 <span> 树,由调用方用 innerHTML 替换回去。流式场景下每个 chunk 到达时都触发一次完整重写,用户的选区、搜索命中、光标位置在每次重建时瞬间清空。
我们调研过给这些库打增量补丁,结论是着色与 DOM 的耦合让"稳定节点引用"在现有架构上几乎无法实现。举个最直接的例子:流式输出 const result = await fetch(...) 这一行,代码会以 chunk 切片到达:
chunk 1: "const re"
chunk 2: "sult = aw"
chunk 3: "ait fetch(...)" 第 1 个 chunk 到达时, re 会被 hljs 当作普通标识符着色为黑色;

第 2 个 chunk 拼上 sult = 后, result 的语义才完整,整段需要重新判定为变量名(蓝色);

第 3 个 chunk 出现 await 关键字时,前面的语法判定可能再次变化。

Token 边界不和 chunk 边界对齐是流式场景的常态——每一帧都要"撤销前一帧的着色判定",而撤销的实现就是"销毁旧 span、重建新 span"。这不是改个调度器或加个缓存能绕开的,它是高亮算法和 DOM 输出耦合的必然结果。
2.3 另一条线:用户反馈的卡顿,真正原因是 DOM 规模

差不多同时期有另一类反馈——“对话久了页面开始卡”。我通过 Chrome DevTools MCP 排查了用户提及的这个典型长对话页:多轮对话每轮含若干代码块,总 DOM 元素 33612 个,其中代码高亮相关节点占绝大多数。Style recalc 单次涉及上万元素,主线程持续承压,低端机和长会话场景尤其明显。
传统代码高亮工具,每一个语法元素着色都会成为一个独立的 DOM 节点,高亮前代码段只有一个 textNode,高亮后 DOM 数量爆炸
两条看似独立的反馈线汇到了同一个根因:社区高亮库的 DOM 模型与 AI 对话的流式、多块、长会话场景架构错配。
2.4 阶段一:自研代码高亮组件 2.x
我们没有立刻重新造轮子。先复用自研的代码高亮组件——它基于 Worker + OffscreenCanvas 离屏渲染,原本用于大规模代码展示场景。我们针对 AI 对话场景做了些针对性的优化和升级,发布了 2.x 版本:
- 补齐代码流式输出能力,支持流式过程中的选中和组件内搜索。
- 新增智能静态图片模式:代码块稳定后降级为图片,节省内存,鼠标交互时瞬间恢复 Canvas 画布组件。
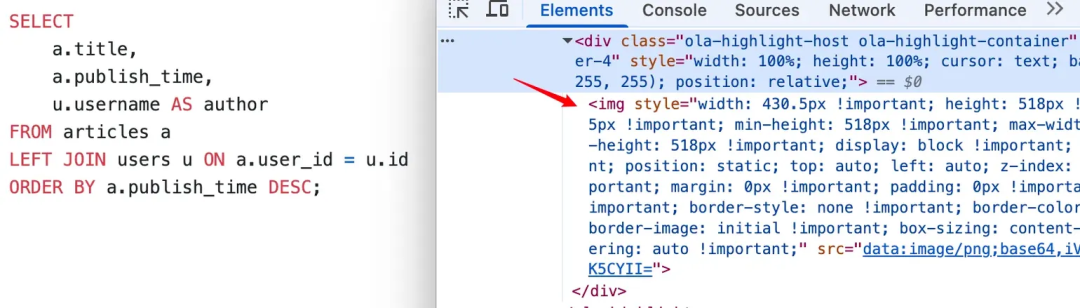
智能静态图片模式下,代码块稳定无交互时会自动从Canvas画布转换为一张静态图片,释放资源仅保留少量事件监听。
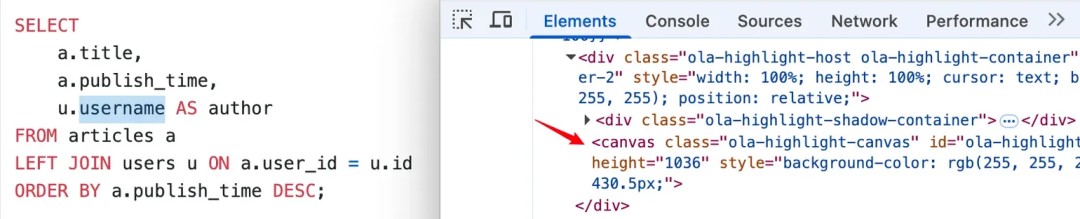
静态图片模式下,当鼠标交互时,瞬间恢复 Canvas 画布组件。
这一阶段基本拉平了体验问题,但实际用下来又发现几个新的不匹配:
- 该组件是为"单块大代码"场景设计的,而 AI 对话是"多块小代码"——每块代码都要启动 Worker、初始化 OffscreenCanvas,固定成本被放大
- Canvas 里的代码不是原生 DOM 文本,用户想把代码块内容和外部正文一起复制时体验欠佳——而这在 AI 对话里恰恰是高频动作
- 不支持浏览器原生页面搜索(Ctrl+F)——Canvas 里的文字对浏览器只是像素。我们虽然在组件内做了独立搜索框,但用户的肌肉记忆是 Ctrl+F,这个落差很难通过教育解决
2.5 阶段二:3.0,双模渲染 + 多线程
3.0 的核心改造不是"把 Canvas 换成 DOM",而是把两者收编成同一个门面下的两个 renderer,对外 API 一致,内部各擅其场。
DOM 模式的底层是 CSS Custom Highlight API——代码以单个 textNode 存在,着色通过 CSS.highlights 注册的 Range + ::highlight() 伪元素完成,不创建任何 <span> 。流式追加只是 textNode.appendData() ,DOM 结构始终不变;选区、Ctrl+F、屏幕阅读器全部基于原始文本节点工作,重新着色不影响其中任何一个。这一刀直接打掉了 AI 对话场景下"流式选中丢失"和"长会话 DOM 爆炸"两个老问题。
通过一个 textNode DOM 节点实现代码语法高亮,上色过程中 DOM 结构不变
Canvas 模式作为 3000 行以上超大代码、以及需要水印防复制的兜底保留,并继承了 2.x 的智能静态图片模式。
多线程是两个模式共同的底盘,但分工不同:Canvas 模式 Worker 里跑 ”tokenize + 绘制到 OffscreenCanvas“整套,主线程只转发消息;DOM 模式 Worker 只做 tokenize,token 流回主线程后交给 CssHighlightPainter 转成 Range 注册到 CSS.highlights ,绘制还给浏览器合成层。 hljs.highlight() 这个最重的活,无论走哪条路,都不再压在主线程上。
关键不是"多线程"三个字,而是三件事配合:文本同步追加 + 着色异步节流双轨,让用户永远先看到字、再看到颜色,绝不卡白屏;rAF 而非 setTimeout 做节流,后台 tab 不漂移、前台帧对齐合成;Worker 启动期的小代码主线程兜底、大代码等齐 Worker 的策略,把"首次 tokenize 卡顿"挡在用户感知之外。
业务侧无论 chunk 切得多碎,只需要持续调 updateCode(完整代码) ,token 边界与 chunk 边界对齐这件事完全交给调度器——这正是阶段一被 DOM 耦合卡死、做不到的事。
2.6 实际收益
指标 | highlight.js | 自研组件 2.x | 自研组件 3.0 |
|---|---|---|---|
DOM 节点数(20 轮对话) | ~15000 | ~300(Canvas 节点) | ~500(稳定 DOM 骨架) |
主线程长任务(>50ms) | 12 次 | 3 次 | 1 次 |
流式选中保留 | 不支持 | 支持(Canvas 模拟) | 支持(原生选区) |
Ctrl+F 可检索代码 | 不支持 | 支持(组件内) | 支持(原生选区) |
内存占用(30 分钟对话) | ~180MB | ~90MB | ~55MB |
03
服务好 AI Coding 之一:用 Harness Engineering 的思路改造存量项目
3.1 改造存量项目
前两部分讲的是前端如何服务 AI 产品体验。但 AI 时代还有另一条变化正在发生:研发过程本身也在被 AI 改造。
在新项目里使用 AI Coding / Vibe Coding 时,体验往往不错。因为新项目上下文干净、约束少、代码风格统一,AI 很容易生成一套"看起来还不错"的实现。但一旦落到存量项目里,问题就会明显变多:
- 命名风格和历史代码不一致
- 组件 import 五花八门
- 样式硬编码满天飞
- 明明项目有封装组件,AI 却直接引用底层三方库
- 生成代码看似能跑,但评审时大量细节被打回
很多时候,我们会把这些问题归因于"模型还不够强"。但深入排查后会发现,根因往往不完全在模型,而在于:项目本身缺少一套机器可读、可被 AI 稳定遵循的工程约束。
AI 看到的是历史代码里参差不齐的事实,它只能在这些事实里取一个"平均值"。如果一个项目里有三种按钮写法、五种颜色使用方式、两套请求封装、若干隐式团队约定,那么 AI 很难凭空推断出"当前团队真正希望它怎么写"。
所以,要让 AI 真正写出可合入的代码,存量项目需要做一定的 AI Coding 适配改造。
3.2 把规则变成 AI 的上下文,而不是只写在文档里
团队规范如果只躺在 iwiki、腾讯文档、README 或大家的脑子里,AI 是看不到的。因此,规则需要进入代码仓库,成为项目的一部分。
我们的做法是在版本库里建立一份"真相源"(例如 openspec/rules/ ),用结构化的 .mdc 文件沉淀:
- 编码铁律
- 样式规范
- 组件使用约束
- 第三方库使用边界
- 反模式清单
再通过一个轻量同步脚本,配合 postinstall 和 Git Hooks,自动分发到 .cursor/rules/ 、 .codebuddy/rules/ 等各类 AI 工具识别的目录。
规则只在一处维护,全员、全工具零漂移。新人 clone 项目后第一次 install ,AI 就已经"读过"了所有团队规范。
3.3 给 AI 一个收敛的代码出口
AI 出错的高发区,往往是项目里存在太多"都能用,但只有一种最推荐"的写法。比如业务代码里直接写:
import { Button } from 'antd'; 这在短期看没什么问题,但在存量项目里很容易造成风格失控。未来要替换组件库或定制交互,改造成本也会成倍放大。
- 我们把 UI 组件统一收口到 src/components/ui/ ,作为业务代码访问 UI 的唯一入口:封装层承接默认样式、统一交互、对接 Design Token;
- 用 ESLint no-restricted-imports 在工具链层强约束,杜绝绕过封装层直接引 antd 的写法。
AI 在"只有一条正确路径"的环境下,准确率显著提升。这类收敛对人也有价值:我们不需要每次纠结"到底该用哪个 Button",评审的时候也不用再反复指出同类问题。
3.4 把视觉决策从代码里抽离成 Design Token
颜色、间距、字号、圆角、阴影等,以 TS 为真相源沉淀在 src/themes/tokens/ ,通过脚本生成 less 变量、CSS 变量与 antd 主题配置,三端共享同一份数据。
AI 不再需要"猜"该用 #1677ff 还是 #1890ff ,而是从一张明确的 token 表里选。写出来的样式天然一致、可主题化、可演进。
对于存量代码,我们采用增量扩展策略:
- 存量文件原样保留,不动结构;
- 新代码强约束接入 token;
- 老代码通过"硬编码预算"机制逐迭代收敛。
我们做这套适配不是想把项目改干净,存量项目永远干净不了,只是想让它别越长越歪。
存量项目适配 AI Coding 的核心,不是加一个插件,也不是写几句 prompt,而是把项目改造成 AI 容易写对的样子。
规则机器可读、入口足够收敛、决策足够显式——AI 的输出方差就会大幅下降,评审成本随之降低,团队对 AI Coding 的信任才能真正建立起来。
04
服务好 AI Coding 之二:重新审视编程语法与范式
项目适配之外,还有一个更底层的问题:我们过去推崇的很多语法习惯和编程范式,在 AI Coding 时代是否还成立?
一个很小的例子,是 Sass 里的 &- 嵌套拼接。
.user-card {
&-header {
font-weight: bold;
}
&-content {
padding: 12px;
}
}
最终生成的类名是:
.user-card-header {}
.user-card-content {}这在过去看起来很优雅:少写重复前缀,结构也清楚。但问题是,当你在浏览器里看到 .user-card-header ,回到代码里全局搜索这个完整类名,可能搜不到。因为源码里不存在完整字符串,它是拼接出来的。人要脑内推导,AI 也要推导。
类似问题还有很多:
- JS 里过度复杂的解构、重命名、默认值混写;
- Python 里多层列表推导式;
- TypeScript 里炫技式类型体操;
- 过度抽象导致一个简单逻辑需要跨多个文件理解;
- 极致 DRY 让局部变化变成全局影响。
这些写法的共同点是:写起来省事,读、找、改、协作都变贵。
4.1 旧范式的底层初衷:减少人工手写成本
我们过去喜欢语法糖、缩写、嵌套、抽象、DRY,有其历史合理性。
因为在很长一段时间里,编程的主要成本之一就是人手写代码。
所以旧审美是:
- 短小 = 优雅
- 抽象 = 高级
- 复用 = 成熟
- 少写 = 高效
这些原则并没有错。它们确实帮助我们减少了重复劳动,提高了局部开发效率。但 AI Coding 改变了成本结构。
4.2 AI Coding 带来的成本结构反转
当 AI 可以快速生成代码后,"少打几个字符"不再是最稀缺的能力。
真正稀缺的是:
- 代码是否容易理解
- 是否容易搜索
- 是否容易让 AI 定位
- 是否容易 review
- 是否容易局部修改
- 是否容易验证正确性
我现在写代码越来越多在想:这件事我到底要解决什么?边界在哪?怎么算做完了?反而"怎么写"这一步,AI 比我快多了。 这意味着,过去一些为了减少输入成本而牺牲可读性的写法,需要重新评估。
4.3 新标准:显式、可搜索、直白、适度重复
我自己最近写代码会下意识做几件事,没什么大道理,纯粹是被 AI 教出来的肌肉记忆。
显式优于隐式
不要让关键信息藏在推导里。比如 CSS 类名,如果最终使用的是 .user-card-header ,源码里最好也能直接搜到 .user-card-header 。这对人有好处,对 AI 也有好处。
可搜索优于可推导
搜索是理解大型项目最重要的入口之一。如果一个变量名、类名、事件名、接口名在运行时才拼出来,那么它就会降低可定位性。过去我们觉得"能推导出来就行",但 AI Coding 时代,更重要的是"能直接匹配到"。
直白实现优于巧妙炫技
聪明代码的问题在于,它往往依赖作者当时的灵感。但工程代码不是智力竞赛,而是长期协作资产。AI 生成、AI 修改、人类 review,都更喜欢直白的控制流和清晰的数据结构。
适度重复优于过度抽象
DRY 仍然重要,但不是所有重复都应该立刻抽象。有些重复只是看起来相似,业务变化方向并不一致。过早抽象会让后续修改变得更困难。在 AI Coding 场景下,适度重复反而能让局部改动更安全,因为 AI 可以在明确上下文内完成修改,而不是牵动一套复杂抽象体系。
4.4 不是反语法糖,而是反"为了写得爽牺牲读得懂"
需要强调的是,这并不是说所有语法糖、抽象和 DRY 都过时了。
在这些场景里,旧范式依然成立:
- 领域核心模型层,DRY 依然是底线
- 系统边界处,抽象依然有巨大价值
- 表达力关键场景,适当语法糖可以显著提升清晰度
- 稳定公共能力,复用仍然比复制更好
真正需要反思的是:我们是否为了写得爽,牺牲了读得懂、搜得到、改得动。AI Coding 时代,代码不仅要对人友好,也要对 AI 友好。
4.5 前端开发者角色的变化
在这个变化里,前端开发者的角色也会发生变化。
过去我们很大一部分能力体现在熟悉语法和框架 API、手写代码快、能快速堆出页面等方面。这些能力仍然有价值,但不再是全部。
未来更重要的是:能不能准确拆解问题、定义清楚边界,能不能判断 AI 生成方案是否合理,能不能设计可维护的架构,能不能让项目持续适合人机协作。
也就是说,前端开发者会从"语法工匠"逐步转向意图拆解者、架构决策者、AI 编码验收者——落到日常就是:少写几行炫技代码,多花点时间想清楚到底要做什么。
05
总结
写到这里其实就一句话——前端在 AI 时代要做好两件事:对外,把 AI 能力变成顺滑的产品体验;对内,把工程体系改造成适合 AI 协作的新形态。
服务好 AI 产品,也服务好 AI Coding。
-End-
原创作者|franslee
感谢你读到这里,不如关注一下?👇

你对本文内容有哪些看法?同意、反对、困惑的地方是?欢迎留言,我们将邀请作者针对性回复你的评论,欢迎评论留言补充。我们将选取1则优质的评论,送出腾讯云定制文件袋套装1个(见下图)。6月19日中午12点开奖。

扫码领取腾讯云开发者专属服务器代金券!

图片





本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号