离线模仿学习的原理和步骤


Offline IL = 在静态数据集上加约束(保守 Q / 隐变量 / 扩散),防止策略在数据集外的状态"乱猜",核心是"学分布、不学单点"。

PART 01
核心问题
无法在线交互、无法请求专家标注 ,只有固定的离线演示数据集。传统 BC 会遇到协变量偏移,DAgger 需要专家在线,GAIL/IRL 需要环境交互——都不适用。
Offline IL 的目标: 仅用静态数据集,学出鲁棒的策略 。
PART 02
核心原理:约束策略不"乱猜"
离线数据的根本问题是 覆盖不足 ——策略可能访问数据集中不存在的状态。解决方案是 约束策略不要偏离数据集太远(在数据集覆盖的状态上) :
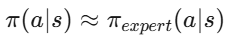
PART 03
主流方法
方法1:保守 Q 学习 (CQL / IQ-Learn)
原理 :在 Q 函数上加惩罚项,让 Q 值在数据集外的动作上被压低,防止策略"炒作"高 Q 值的动作。
算法:IQ-Learn(隐式 Q 学习)
输入:离线数据集 D = {(s,a,r,s')}
1. 初始化 Q 网络 Q_φ,目标网络 Q_target
2. for iter = 1 to N:
# 标准 Bellman 更新
Q_target = r + γ * max_a' Q_target(s', a')
loss_bellman = MSE(Q(s,a), Q_target)
# 保守性惩罚:数据集外的动作 Q 值要低
# 对随机采样的动作 a' ~ π,压低其 Q 值
loss_conservative = E[Q(s,a')]_random_a' # 负号:拉低
loss = loss_bellman + α * loss_conservative
update Q_φ
3. 策略:π(s) = argmax_a Q(s,a)方法2:条件行为克隆
原理 :建模条件分布 p(a∣s,z),其中 z是隐变量或上下文,表达"同一状态下的不同专家意图"。
算法:Conditional BC
输入:离线数据集 D = {(s,a)}
1. 训练条件 VAE:
Encoder: z ~ q(z|s,a) # 编码 (s,a) 到隐空间
Decoder: a ~ p(a|s,z) # 给定 (s,z) 重建动作
loss = Reconstruction + KL(q(z|s,a) || N(0,1))
2. 推理时:
z ~ N(0,1) 或从先验采样
a = argmax_a p(a|s,z) # 解码动作方法3:扩散策略
原理 :用扩散模型建模动作分布 p(a∣s),天然支持多模态动作。
算法:Diffusion Policy
输入:离线数据集 D = {(s,a)}
1. 训练去噪网络 ε_θ(a_noisy, s, t):
for each (s,a) in D:
noise = randn_like(a)
a_noisy = √α_t * a + √(1-α_t) * noise # 前向扩散
pred_noise = ε_θ(a_noisy, s, t)
loss = MSE(pred_noise, noise)
update ε_θ
2. 推理:
a_T = randn(action_dim) # 初始噪声
for t = T → 1: # 反向去噪
pred_noise = ε_θ(a_t, s, t)
a_{t-1} = denoise_step(a_t, pred_noise)
返回 a_0PART 04
方法对比
方法 | 核心机制 | 优势 | 劣势 |
|---|---|---|---|
IQ-Learn | 压低数据外 Q 值 | 理论保证强 | 需调超参 α |
Conditional BC | 隐变量建模多模态 | 表达能力强 | VAE 训练不稳定 |
Diffusion Policy | 扩散模型拟合动作分布 | 多模态支持好 | 推理慢(多步去噪) |
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号