重新定义智能渗透:TCH优秀开源项目CyberStrikeAI 技术解析与行业观察

重新定义智能渗透:TCH优秀开源项目CyberStrikeAI 技术解析与行业观察

云鼎实验室
发布于 2026-06-04 09:44:03
发布于 2026-06-04 09:44:03

图1:CyberStrikeAI 工具标识
在 AI 与网络安全深度融合的今天,自动化渗透测试早已从基于规则的线性脚本执行进化到智能决策驱动阶段。腾讯云黑客松智能渗透挑战赛获奖项目 CyberStrikeAI(GitHub: Ed1s0nZ/CyberStrikeAI)正是这一趋势的集大成者之一 —— 作为一款纯 Go 语言构建的 AI 原生安全测试平台,它不仅实现了从自然语言指令到攻击链执行的端到端自动化,更通过 MCP 协议原生集成、多智能体编排、角色化测试等创新设计,解决了传统 AI 渗透工具工具调用与决策逻辑分离、缺乏全局态势感知和动态攻击路径规划能力的核心痛点,成为 2026 年安全圈最受关注的开源项目之一。
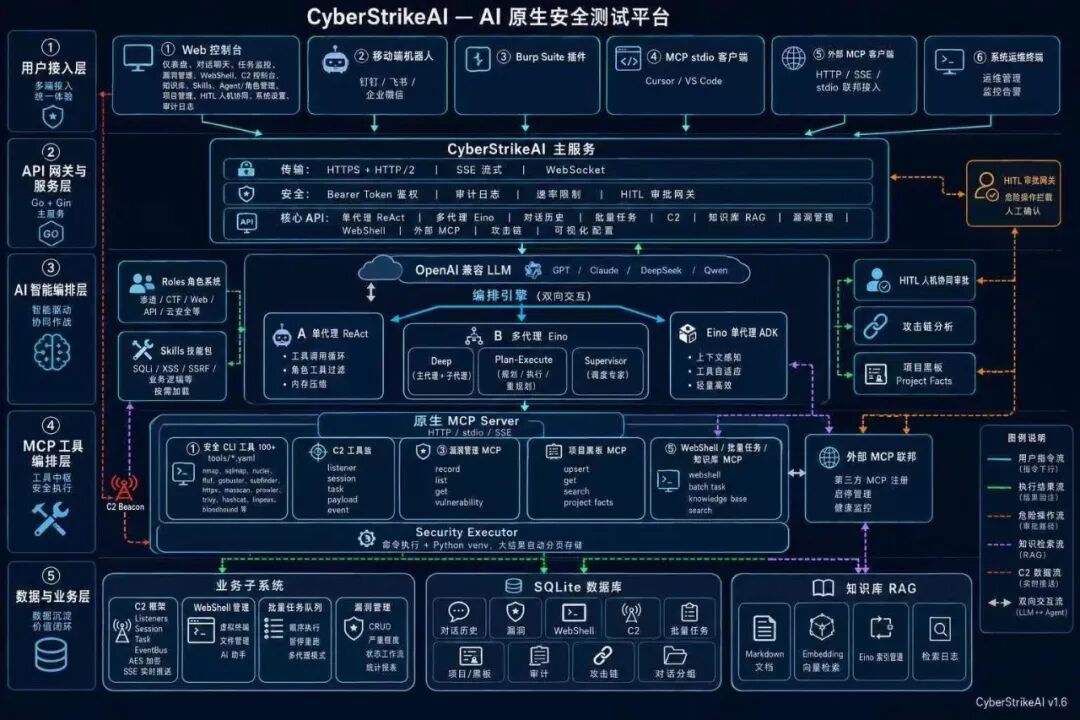
图2:系统架构设计
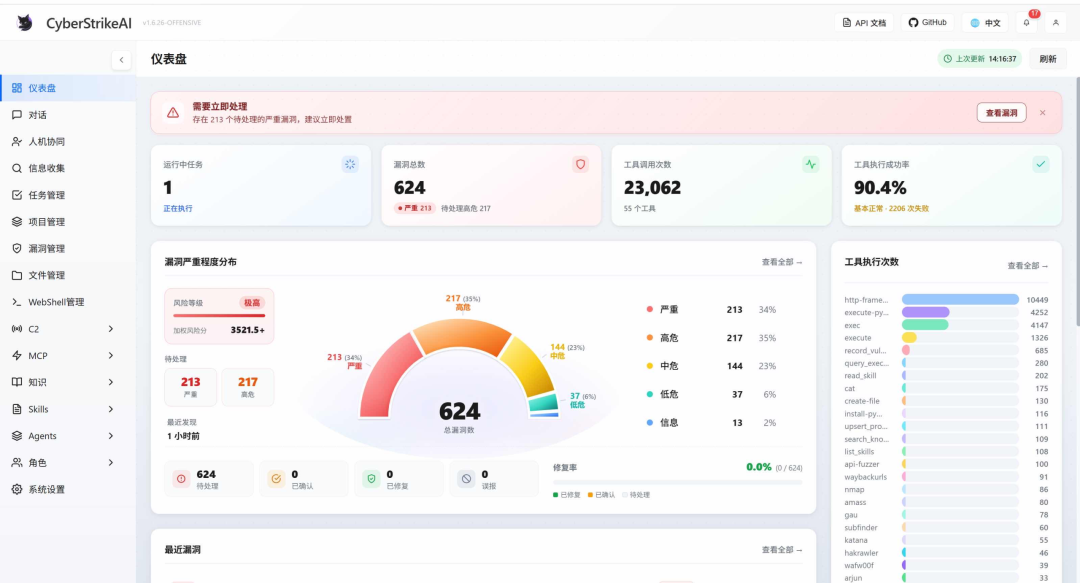
图3:CyberStrikeAI仪表盘
许多 AI 安全产品仍停在「大模型 + 命令行包装」——聊完即散、难复核、难交接。CyberStrikeAI 用执行、认知、修复三条闭环把测试做成可运营系统:工具串成攻击链,认知跨会话沉淀,漏洞进台账推动整改。对话是入口,资产与流程才是出口——定位更接近面向授权场景的安全测试操作系统,而非一次性对话玩具。三条闭环的具体落点如下:
闭环 | 解决什么问题 | 平台怎么落地 |
|---|---|---|
执行闭环 | 工具多、上下文易爆、难串联 | MCP 统一接入大量安全工具配方(YAML 扩展);tool_search动态工具池;单代理 ReAct / Eino 多代理按任务选型;reduction与分页归档 |
认知闭环 | 换会话就「失忆」 | 项目级事实黑板:渐进式注入与按需拉取 |
修复闭环 | 测完即走,难推动整改 | record_vulnerability登记 → 台账流转 → 复测与导出 |
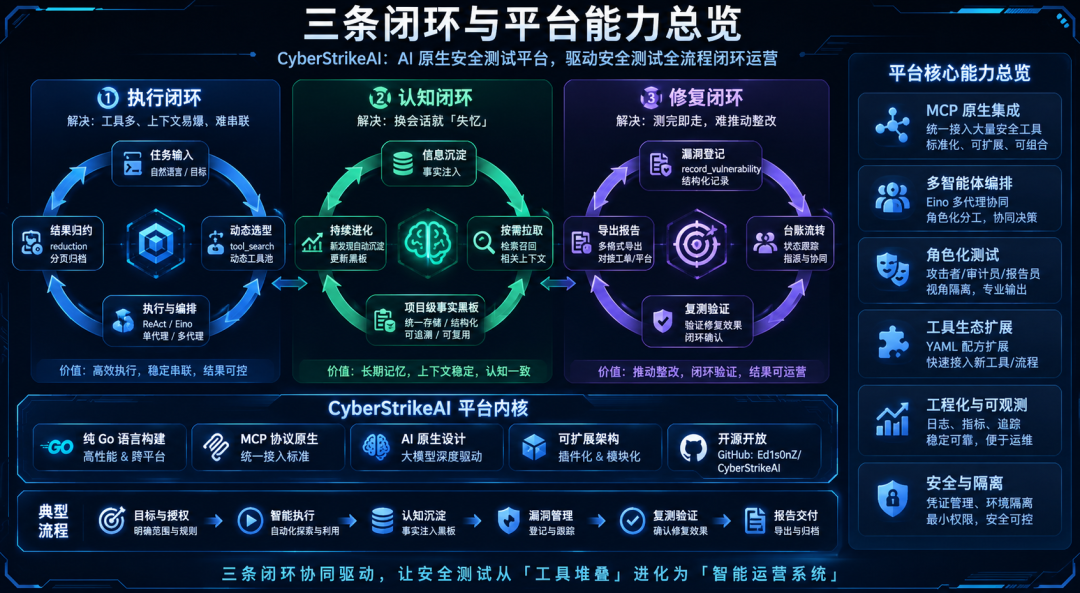
图4:三条闭环与平台能力总览
一、核心技术架构:关键工程设计
平台以 Go 为底座(并发、部署与资源占用更适合多任务并行),从架构上避开「Python 脚本 + LLM 包装」的常见路径。其工程优势主要体现在以下七个能力面。
1. MCP 原生集成 + 可扩展工具面
将 MCP(Model Context Protocol) 作为工具集成的一等公民,支持 HTTP、stdio、SSE;内置大量安全工具配方(Nmap、Sqlmap、Nuclei 等),可接入外部 MCP 联邦(自研封装、Burp 协同、情报 API 等),并支持 YAML 配方扩展;提供 Burp Suite 插件,可对接 Cursor、Claude Code 等 IDE。
相较「Shell 一把梭」,MCP 让模型按具名工具拿参数契约与结构化结果;每次调用可留工具级记录(参数、状态、结果、耗时),与会话、攻击链、HITL 关联。工具面扩大时,tool_search、reduction 与大结果分页缓解上下文膨胀——多数 Demo 型产品较少覆盖这一点。
经 MCP 暴露的能力与 Web 主流程语义一致:控制台典型操作,在授权策略内可由 Agent 等价编排;主流程亦可 API / MCP 嵌入 SOC、DevSecOps、CI/CD,作为安全能力中间层。
2. 单代理与多代理并存:按复杂度选型
采用字节跳动开源的 Eino 框架,坚持简单任务不铺张、复杂任务再编排:
- 单代理 ReAct(/api/agent-loop):常规对话式测试,成本与路径可控。
- 多代理 Eino(/api/multi-agent/stream):deep、plan_execute、supervisor 三种编排,界面或请求显式选择,可配批量队列与机器人策略。
- 角色 + 技能:预置多类安全专家角色(渗透、API、云审计、CTF 等),约束提示词与工具权限;技能包遵循 Agent Skills 规范,在会话中由 skill 渐进披露(先 name/description,再按需拉取 SKILL.md等),避免一次性撑满上下文。
信息收集、漏洞识别、后渗透可由不同角色协作,协调者整合为攻击链——更接近人类团队,而非「全家桶多 Agent」。
3. 攻击链可视化与可解释交付
除文本结论外,平台提供攻击链图、风险打分与步骤回放,把「发现了什么」变成「如何串联、证据在哪」。这对红蓝复盘、管理层汇报与争议复核很重要,也区别于只会堆扫描日志的 AI 工具。
4. 后渗透与持续作业
- 轻量 C2:TCP 反向、HTTP/HTTPS beacon、WebSocket;会话、任务、Payload 经 REST/MCP 与 Agent 同语义操作。
- WebShell 管理:连接治理、命令与文件操作,按连接隔离 AI 会话,降低串台。
- HITL 与 OPSEC:高风险工具可审批,工具白名单与会话策略联动,命令类动作可配置拒绝规则。
C2/WebShell 的价值在于纳入同一治理平面(权限、审批、留痕、复盘),而非脱离管控的外挂。
5. 项目管理与事实黑板:跨会话「长期记忆」
授权测试常跨天、跨人、多轮对话。平台用项目收拢对话、漏洞与范围,用事实黑板沉淀「测到哪、证据在哪」,让目标、环境、证据在多次会话间可持续复用:
- 自动注入(轻量):会话启动只带黑板索引(key、摘要),不含完整 body。
- 按需拉取(完整):复现 POC 时 get_project_fact;较多时用 list_project_facts / search_project_facts。
- 边测边写(持久):upsert_project_fact 更新环境认知;正式漏洞走 record_vulnerability。
新人接手、隔天续测时,认知落在数据库与工具链上,而非散落聊天记录。
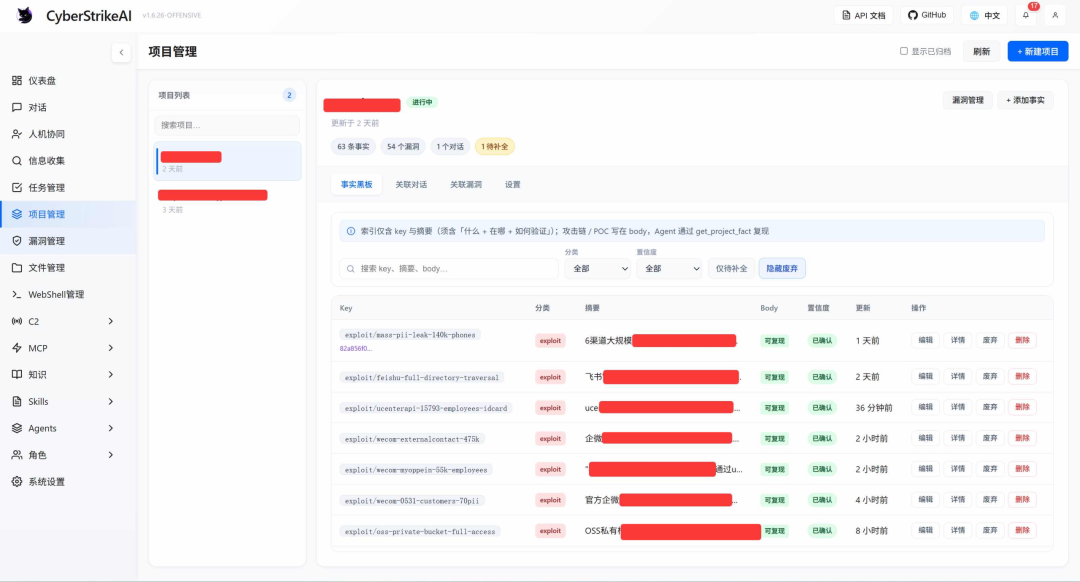
图5:项目管理与黑版示意
6. 知识、漏洞与协作:从「测一次」到「养资产」
- 知识库 RAG:剧本、漏洞知识、内部规范可向量索引,检索可留痕、结论可复核。
- 漏洞台账:分级、状态流转、导出与看板,衔接修复闭环。
- 批量任务队列:多目标顺序执行、独立会话与状态跟踪。
- 平台可管:Web 登录保护、HTTPS、SQLite 持久化;兼容 OpenAI 协议,国产模型适配持续迭代。
7. Agent 全生命周期与分层留痕
授权测试既要「跑得动」,也要「查得着、说得清」。平台对 Agent 会话、工具执行、审批决策与业务对象提供状态管理与分层留痕,构成区别于「聊完即散」类 AI 工具的企业向底座:
留痕类型 | 覆盖范围 | 典型用途 |
|---|---|---|
会话与执行档案 | 对话、工具调用写入 SQLite,支持历史重放;工具监控可查看任务队列、执行日志;超大输出分页存附件,可按页检索 | 复盘某次测试「做了什么」、核对证据 |
工具级记录 | 参数、状态、结果、耗时,与攻击链、HITL 关联 | 争议复核、对齐攻击链节点 |
人机协同记录 | 高风险工具待审批 / 已批准等审批链 | 界定授权边界与放行责任 |
业务对象生命周期 | 漏洞台账状态流转;批量任务待执行 / 执行中 / 完成 / 失败;项目与事实黑板持续更新 | 运营看板、整改跟踪、跨人交接 |
平台操作审计 | 登录、配置变更等管理操作(系统设置 → 日志审计,可配置保留策略) | 平台自身合规与追责 |
知识检索留痕 | RAG 检索过程可记录 | 结论可复核、排障 |
上述能力在同一治理平面内衔接:自然语言入口与控制台手操、机器人与流水线调用,均走同一套审批与留痕策略,而非「自动化无痕、手工另算一套账」。
工具编排、攻击链交付、事实沉淀、漏洞台账与分层留痕相互衔接,形成「测得清、记得住、查得到、推得动整改」的完整链路。
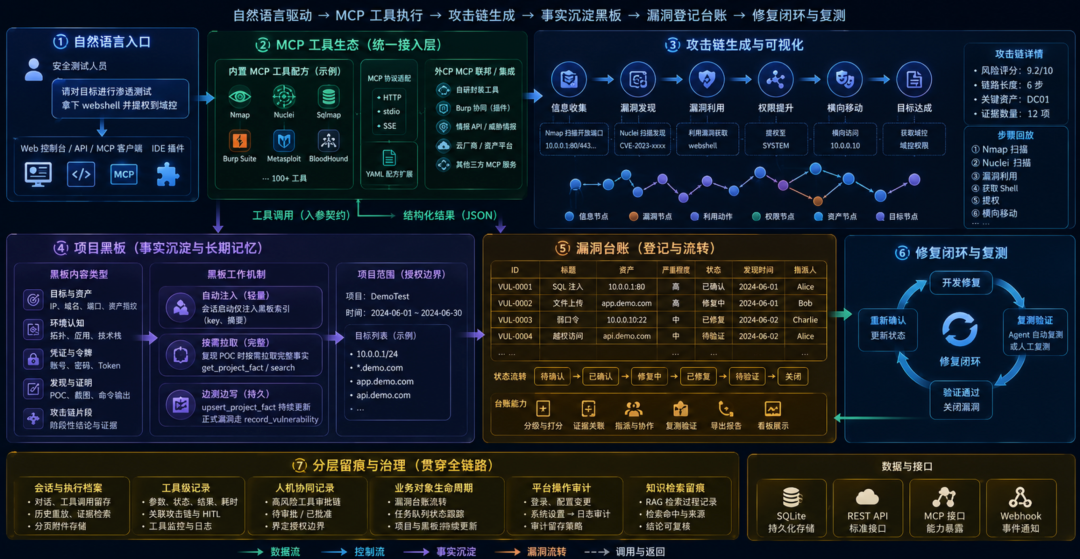
图6:攻击链与MCP、漏洞台账、项目黑板协同示意
二、差异化能力:解决传统渗透测试的核心痛点
CyberStrikeAI 之所以能在众多 AI 渗透项目中受到关注,核心在于上述工程能力在业务侧转化为可感知的价值,精准击中三类长期痛点:
行业痛点 | 传统做法的局限 | CyberStrikeAI 的差异化 |
|---|---|---|
门槛高 | 强依赖个人对工具命令、参数、编排的记忆 | 自然语言驱动 + Web/MCP 双通道,同一套治理下人机皆可操作 |
质量不稳 | 同一目标,不同测试员覆盖面和结论差异大 | 角色化方法论 + 技能渐进加载,把经验固化为可复用资产 |
难闭环 | 扫描完即走,利用验证、整改推动断裂 | 授权范围内全流程编排 + 攻击链交付 + 漏洞台账与事实黑板 |
难审计 | 聊天型 AI 结论难复核,责任与过程难追溯 | Agent/任务全生命周期 + 会话与工具档案 + 平台操作审计 + 审批留痕 |
上述痛点并非孤立:门槛、质量、闭环与审计能力,共同支撑「可运营的安全测试」;其中分层留痕贯穿三条闭环,是标准化与合规落地的底座。
1. 零门槛:自然语言驱动的渗透测试
痛点:传统渗透高度依赖专家对 Nmap、Sqlmap、Nuclei 等工具的记忆——记命令、记参数组合、记多工具串联顺序。AI 安全产品若只做「聊天建议」而不能落地执行,门槛并未真正降低。
做法:CyberStrikeAI 实现「说人话就能做测试」。用户输入例如「扫描 192.168.1.0/24 网段的开放端口并检测高危漏洞」「检查 https://example.com 是否存在 SQL 注入」,系统即自动拆解子任务、选择工具配方、执行并输出结构化报告(含步骤、证据引用与风险说明),而非一段无法复核的散文。
技术支撑:依托 MCP 原生工具面,模型按具名工具调用而非让用户自行拼 Shell,tool_search 等在工具规模较大时仍能控制上下文;Web 控制台与 Agent、机器人、流水线经 MCP/API 共享同一主流程——资深工程师可手控,初级成员或 SOC 值班亦可用自然语言委托。简单问询走单代理 ReAct,复杂目标再启用多代理编排,兼顾效率与成本。
典型场景:授权范围内的资产摸底、单点漏洞验证、红队辅助侦察、DevSecOps 在 CI 旁路触发检查。社区反馈显示,用户无需死记硬背大量 CLI 参数,即可在较短时间内完成从环境搭建到首轮测试的主链路。
治理一致:低门槛不等于「无痕快捷」。自然语言触发的任务同样落入会话档案与工具级记录,高风险动作仍经 HITL 与 OPSEC 约束——降低的是操作门槛,不是审计要求。
2. 标准化:角色化测试保证结果质量
痛点:渗透质量高度依赖个人经验——有人只做端口扫描,有人漏测业务逻辑与 API;交接项目时,下一位测试员往往要从零读聊天记录,覆盖是否完整难以审计。
做法:通过角色化测试体系把方法论写进系统,而非写进某个人脑子里。每个预置角色绑定专属系统提示词、工具权限与测试边界,并遵循 OWASP Top 10、MITRE ATT&CK 等行业框架,力求覆盖全面、路径一致。
示例:选择「API 安全测试」角色时,系统会按既定剧本推进接口发现、参数遍历、认证绕过、注入测试等环节,降低「想到哪测到哪」的遗漏;专业场景还可启用对应 Skills,在多代理会话中按需拉取完整技能说明。测试范围、项目统计、事实黑板待补全项等在 Web 控制台统一呈现,便于负责人做质量把关。
组织侧价值:
- 可复现:同类目标、同类角色,多次测试结果更可对比,利于基线检查与回归。
- 可交接:项目与事实黑板沉淀目标与环境认知,新人接手无需依赖口头交接。
- 可审计:工具级调用记录与攻击链步骤回放,可还原「谁在何时对何目标执行了何工具、得到何结果」;HITL 保留审批链,便于回答「为何放行高危操作」;会话历史支持重放,覆盖是否完整有据可查;平台操作审计则覆盖管理员登录、配置变更等侧,满足测试平台自身的内控要求。
本质是把资深测试员的判断框架产品化,并把过程证据一并固化,缓解「人走经验散、结论无法复核」的问题。
3. 自动化:从发现到利用的全流程闭环
痛点:多数 AI 渗透工具停在漏洞扫描——报告列出 CVE 或高危项后即结束,无法连贯完成利用验证、影响面评估与整改推动;企业得到的往往是「问题清单」,而不是「可行动的测试结论」。
做法:在书面授权、目标白名单与 HITL 边界内,CyberStrikeAI 串联「资产探测 → 漏洞识别 → 利用验证 → 权限提升 → 横向移动 → 报告生成」,并能根据中间结果调整策略——例如发现 SQL 注入线索后,编排调用 Sqlmap 等工具做验证,再在审批通过后进入后渗透与横向验证;C2、WebShell 与审批、留痕同属一套治理平面。
三条闭环的落点:
- 执行闭环:多工具自动编排与大结果治理,解决「扫得出但串不起来」。
- 认知闭环:事实黑板跨会话保留目标、认证、POC 片段,解决「测到一半失忆、重复劳动」。
- 修复闭环:漏洞写入台账并分级流转、导出与复测,解决「测完无人跟、整改无依据」。
交付物:除漏洞列表外,还包括攻击链图与步骤回放、漏洞详情与修复建议、可导出的台账数据,便于开发修复、管理层知情与蓝队复盘。
全生命周期运营:批量任务队列对多目标提供待执行、执行中、完成、失败等状态跟踪,每个任务独立会话、可查执行历史;漏洞在台账内经历待确认、已确认、已修复等流转;长周期项目依托事实黑板持续更新认知——自动化输出的不是一次性对话,而是可跟踪、可续测、可导出的测试资产。
平台在强调自动化的同时,将 OPSEC、审批策略与分层留痕绑定在同一产品面,面向授权场景验证真实攻击路径与影响。
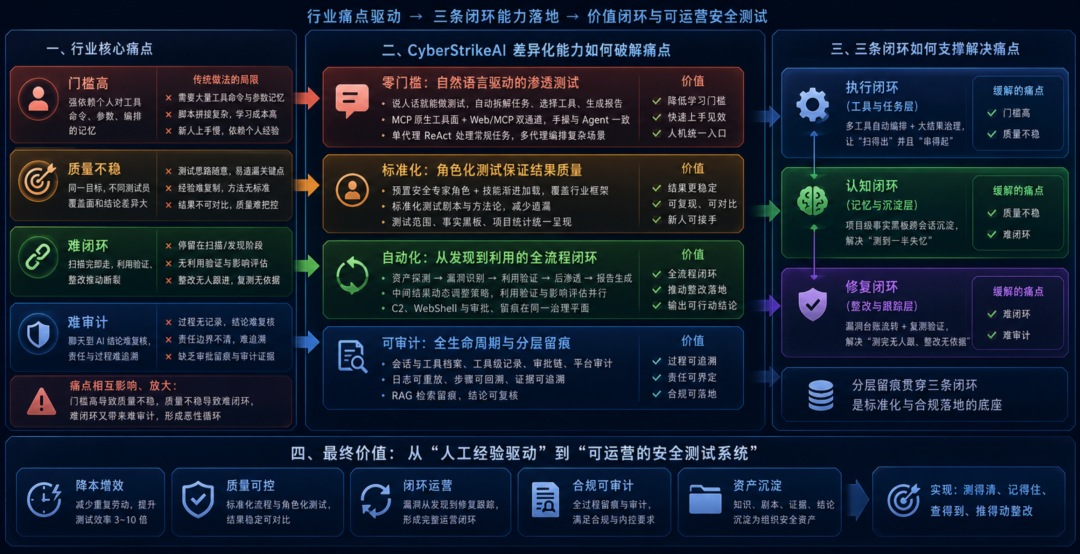
图7:行业痛点与闭环关系示意
三、国内外社区与行业评价:创新与争议并存
自 2025 年 12 月开源以来,CyberStrikeAI 在 GitHub 获 4000+ Star、680+ Fork。据仓库 Traffic 数据(近 14 天),页面访问 1.6 万+(独立访客 3600+),实际拉代码的独立来源 1700+,反映从关注到反复了解、再到试用/部署的转化较为明显;FOFA 网络空间测绘截至 2026 年 6 月显示公网可探测实例 260+,从另一侧面印证已有相当规模的实际落地。项目已加入 https://github.com/knownsec/404StarLink 星链计划,并获评 TCH Top-Ranked Intelligent Pentest Project,同时引发全球安全社区广泛讨论——技术认可与滥用争议并存。
2026 年 4 月,四川大学等机构在 arXiv 论文 Hackers or Hallucinators?(https://arxiv.org/abs/2604.05719)中,对 13 款代表性开源 LLM 自动渗透框架开展统一基准测评(消耗 10 亿+ token),CyberStrikeAI 为评测对象之一;论文将其归入实际单代理 ReAct 架构,在 Easy/Medium 任务上与多款多智能体框架表现相当(综合得分 S=55,位列开源框架前列),并以其为案例讨论工具池规模与渗透效果的关系。
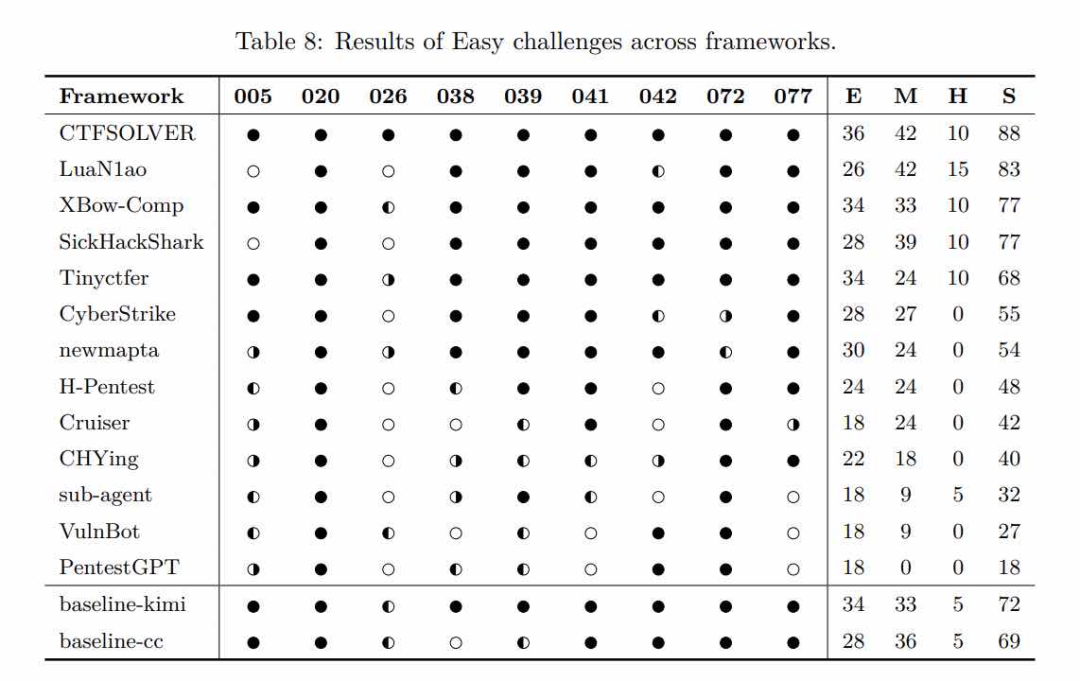
图8:《Hackers or Hallucinators?》统一基准下各框架 Easy 挑战表现
1. 正面评价:技术先进性获得行业认可
- 国内开发者社区:常见评价是较完整可用的开源 AI 安全测试平台之一;MCP 原生集成与 Web 运营面常被点名为亮点。部分团队在授权范围内的扫描、基线检查上反馈人效有可观提升。
- 国外安全从业者:有观点认为更接近人类渗透员的任务拆解与工具编排;多智能体与 C2/攻击链一体化亦被与商业产品对比,同时强调部署与滥用风险须同步评估。
- 技术对比优势:相对学术原型,具备 Web UI、漏洞台账、项目黑板与企业治理钩子;相对通用 Agent(如 OpenHands),在安全场景下路径更短、边界更清晰。
2. 争议与待优化方向:被滥用的风险与技术短板
- 被威胁行为者滥用的担忧:这是 CyberStrikeAI 面临的最大争议。国际网络安全公司 Team Cymru 和 BleepingComputer 先后报道,有威胁 actor 已经在实际攻击中使用了 CyberStrikeAI,特别是针对 Fortinet FortiGate 防火墙的大规模入侵活动。Team Cymru 高级威胁情报顾问 Will Thomas 警告:“CyberStrikeAI 的普及正在加速,这标志着 AI 增强型进攻工具扩散趋势的危险升级,新手也能通过简单操作发动复杂攻击。”
- 技术待优化点:多智能体偶发跑偏;文档与部署仍有门槛;国产大模型与大规模并发稳定性待更多验证。
- 合规性问题:由于内置 C2 功能,CyberStrikeAI 的使用存在法律风险。项目虽然在 README 中明确声明 “仅用于教育和授权测试目的”,但无法完全防止被用于非法活动。
四、未来展望:AI 渗透测试的发展方向
CyberStrikeAI 的成功证明了 AI 技术在渗透测试领域的巨大潜力,但它仍然处于发展的早期阶段。未来,AI 渗透测试平台需要在以下几个方向持续突破:
1. 小样本学习能力:提升对零日漏洞和小众自研组件漏洞的识别能力,减少对训练数据的依赖
2. 可解释性:让 AI 的决策过程可追溯、可解释,帮助安全人员理解攻击逻辑
3. 防御对抗能力:能够绕过 WAF、IDS 等防御设备,模拟真实攻击者的规避技巧
4. 合规性增强:提供更严格的权限控制和审计机制,确保工具仅用于合法用途
五、结语
CyberStrikeAI 不仅是一个优秀的开源项目,更是 AI 与网络安全融合的一个里程碑。它展示了 AI 技术如何重构渗透测试的工作流程,让安全测试从 “依赖个人经验” 走向 “标准化、自动化、规模化”。腾讯云智能渗透黑客松正是为这样的创新提供了展示和交流的平台,通过汇聚全球安全开发者的智慧,推动 AI 安全技术的进步与落地。未来,我们期待看到更多这样的创新成果涌现,共同构建更安全的数字世界。
图片
END
更多精彩内容点击下方扫码关注哦~
关注云鼎实验室,获取更多安全情报
图片
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号