PDF预览分片


PDF.js 是一个非常强大的 JavaScript 库,用于在网页中渲染 PDF 文档。它的分片加载(或称为流式加载)是其性能优化的一部分,允许在需要时按需加载 PDF 的不同部分。这种机制使得大文件的加载过程更加高效,用户体验也得到了提升。
分片加载的原理:
- PDF文档结构:PDF文件由多个部分(页面、对象、字体等)组成,每个页面的内容通常可以单独访问,因此不需要一次性加载整个文档。
- 按需加载:默认情况下,PDF.js会根据用户的操作(如翻页)动态加载所需的页面,当用户请求某一特定页面时,PDF.js会从PDF文件中提取该页面的数据,而不是提前加载所有页面。
- 流式读取:PDF.js使用流式读取的方式处理PDF文件,它会在需要时从服务器获取页面数据,而不是一次性加载整个文件。这个方式通过 HTTP Range 请求来实现,只请求文件的特定字节范围,从而减少带宽的使用。
- 缓存机制:为了提高性能,PDF.js会缓存已经加载的页面数据,这样当用户再次请求已经加载过的页面时,可以直接从缓存中获取,而不是重新加载。
- 异步加载:在加载PDF的过程中,用户界面仍可以响应用户的操作,这样确保了用户体验不会因为加载过程收到影响。
优势
- 提高加载速度:通过只加载用户当前需要的页面,减少了初次加载的时间
- 节省带宽:不必下载整个PDF文件,只需下载用户所需的部分
- 更好的用户体验:用户可以更快看到他们想要查看的内容,不必等待整个文件加载完成
Canvas渲染代码
const loadingTask = pdfjsLib.getDocument({
url: 'path/to/document.pdf',
rangeChunkSize: 65536, // 64 * 1024,每次请求的字节数
disableAutoFetch: true, // 禁用 PDF 文档中附加页面的自动获取
disableStream: false // 开启 PDF 文档的流式加载
});
loadingTask.promise.then(pdf => {
console.log('PDF 加载完成');
// 加载特定页面
pdf.getPage(1).then(page => {
console.log('页面加载完成');
const scale = 1.5;
const viewport = page.getViewport({ scale: scale });
// 准备画布以显示页面
const canvas = document.getElementById('the-canvas');
const context = canvas.getContext('2d');
canvas.height = viewport.height;
canvas.width = viewport.width;
// 渲染页面到画布
const renderContext = {
canvasContext: context,
viewport: viewport
};
page.render(renderContext);
});
}).catch(error => {
console.error('加载 PDF 时出错: ', error);
});Dom渲染代码
let pdfViewer = null
const eventBus = new pdfjsViewer.EventBus()
// 获取挂载点
const container = document.querySelector('#pageContainer')
// 实例化pdf视图
pdfViewer = new pdfjsViewer.PDFViewer({
container: container,
eventBus: eventBus
})
const loadingTask = pdfjsLib.getDocument({
url: pdfUrl,
cMapUrl: PdfCMapUrl, // 字体库地址
cMapPacked: true, // 字体打包
rangeChunkSize: 32_768, // 每次请求的字节范围大小,默认值为 32768 字节(32KB)
disableAutoFetch: true, // 禁用自动获取整个文件
disableStream: false // 启用流式加载
})
loadingTask.promise.then((pdf) => {
pdfViewer.setDocument(pdf)
})
eventBus.on('pagerendered', (event) => {
const page = event.pageNumber
console.log(`Page ${page} rendered`)
})官方示例
mozilla.github.io/pdf.js/web/…
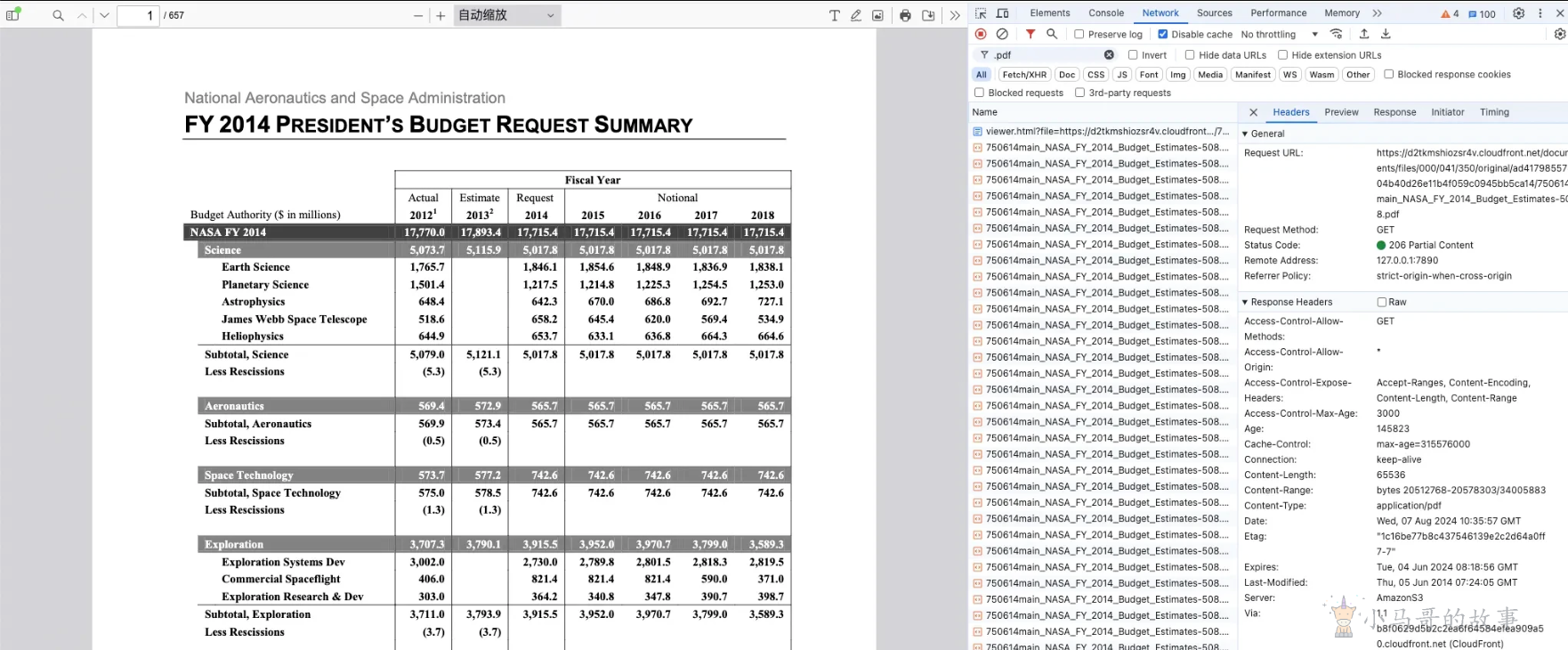
image-20260603091557102
服务端响应头
# makefile
Access-control-expose-headers: Accept-Ranges, Content-Encoding, Content-Length, Content-Range下面是对阿里云上传文件的响应头配置,配合PDF.js即可生效
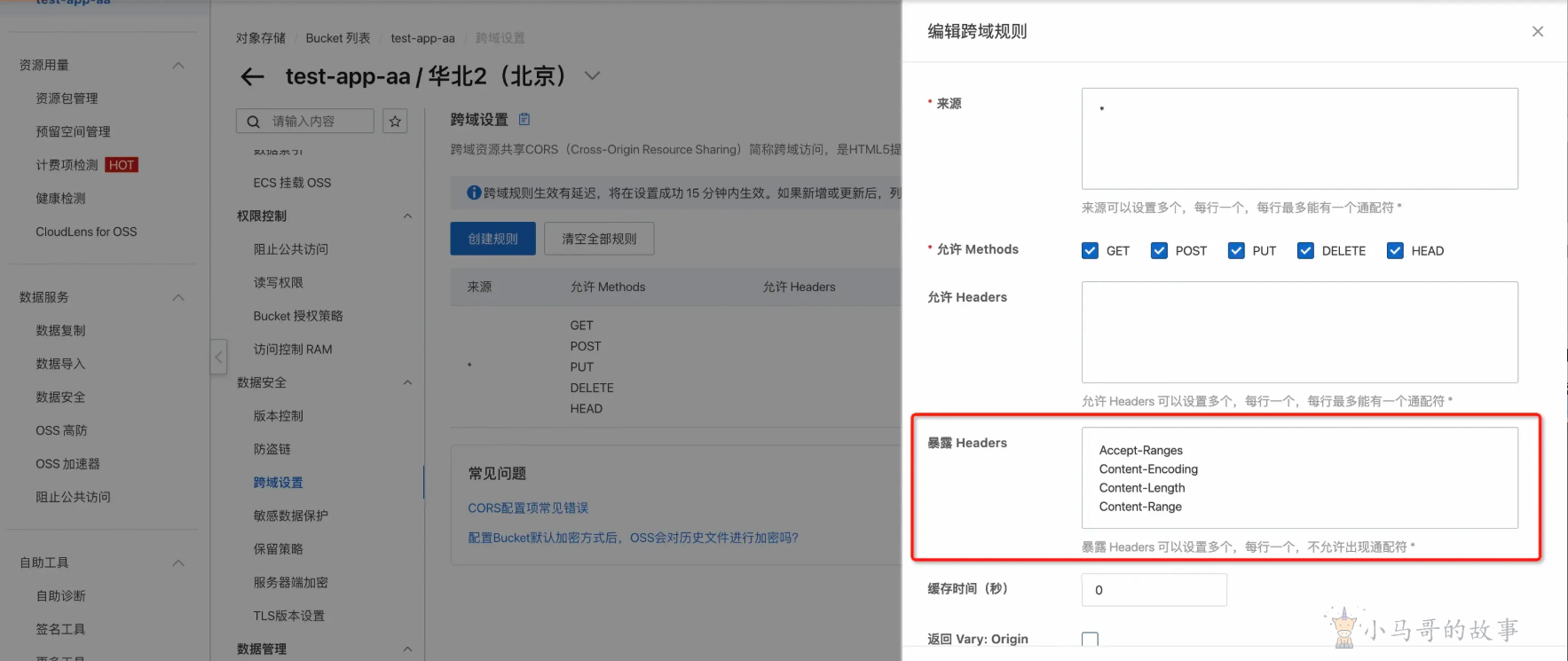
image-20260603091615406
# 后端设置响应头代码
ObjectMetadata metadata = new ObjectMetadata();
String bs64 = BinaryUtil.toBase64String("Accept-Ranges, Content-Encoding, Content-Length, Content-Range".getBytes(StandardCharsets.UTF_8));
metadata.setHeader("x-oss-persistent-headers","Access-Control-Expose-Headers: " + bs64);
client.putObject(ossTokenDTO.getBucketName(), infoDTO.getKey(), file, metadata);参考文档
本文由 小马哥 创作,采用 知识共享署名4.0 国际许可协议进行许可 本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名 最后编辑时间为: 2026/06/03 01:19
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-06-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号