看完 SAM3 ,我连夜用 56MB 撸了个能塞进浏览器的 SAM

看完 SAM3 ,我连夜用 56MB 撸了个能塞进浏览器的 SAM

javpower
发布于 2026-06-03 19:23:57
发布于 2026-06-03 19:23:57
看完 SAM3 ,我连夜用 56MB 撸了个能塞进浏览器的 SAM
40MB 编码器 + 16MB 解码器,5 种 prompt 全支持,M1 笔记本 CPU 模式 180ms 出图。
SAM 3 走的是"更大、更全、能认概念"的路子,权重动辄几 GB,本地部署要 24G 显存的卡。对个人开发者来说,这东西和「能跑」之间隔着一条银河。
我手头有个工业质检的小活,需要从传送带图片里把缺陷抠出来,等不起云端推理。于是那天晚上熬到两点,用 MobileSAMv2 撸了个 Web Demo:
- 整个项目权重 56MB(编码器 40MB + 解码器 16MB)
- 5 种 prompt 方式:点、框、自动、模板匹配、文本
- CPU 跑出毫秒级:M1 笔记本上点分割 180ms,自动分割 4 秒切 50 个 mask
- 浏览器打开
localhost:8000就能玩,不挑显卡
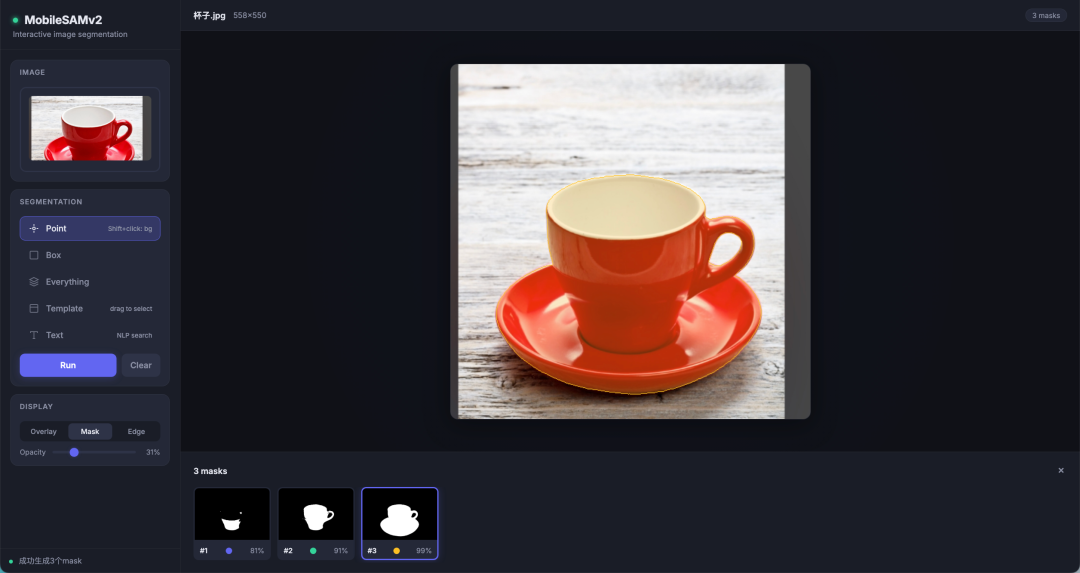
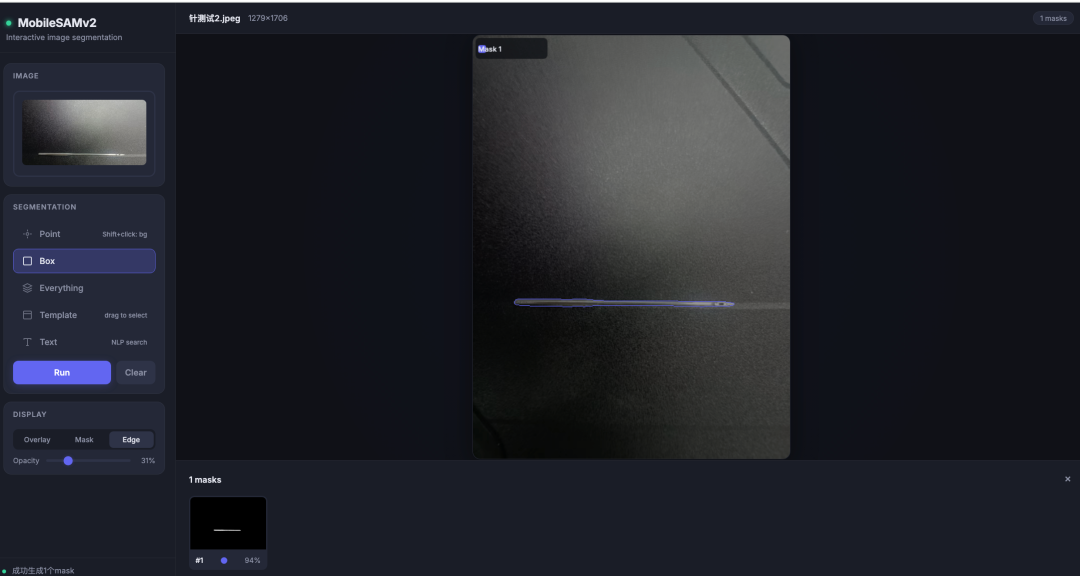
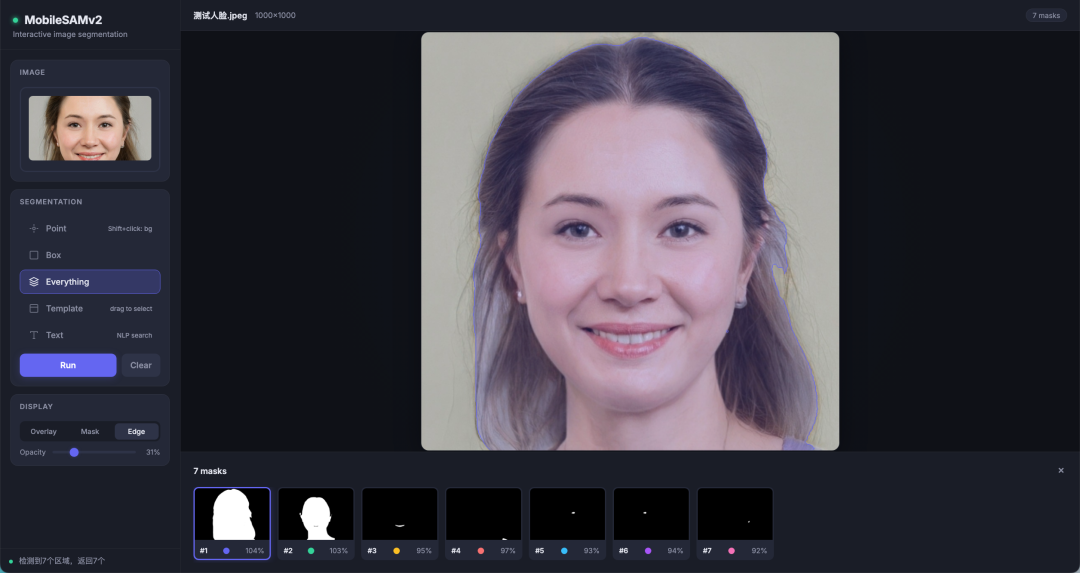
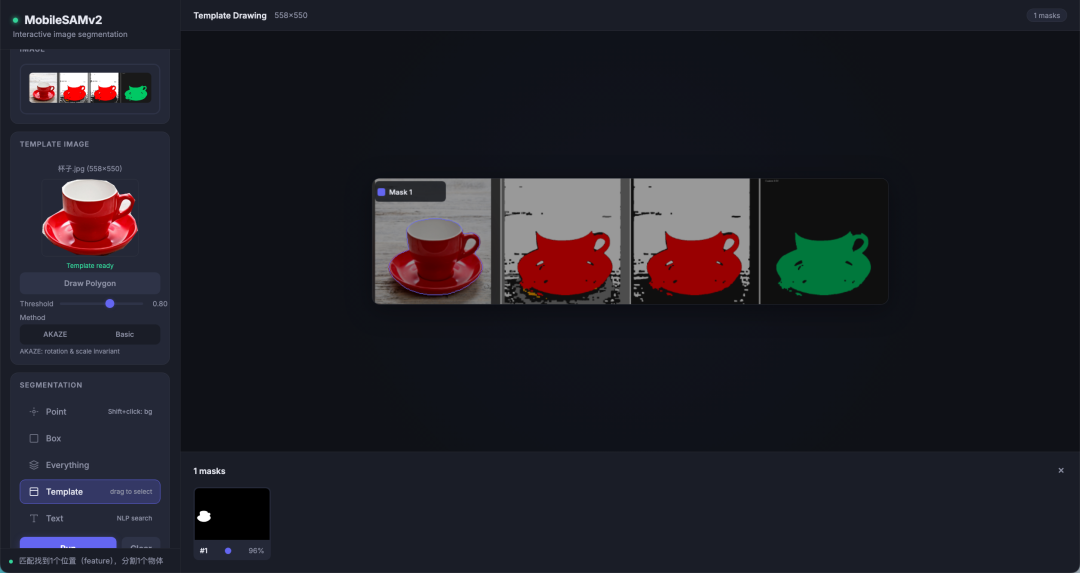
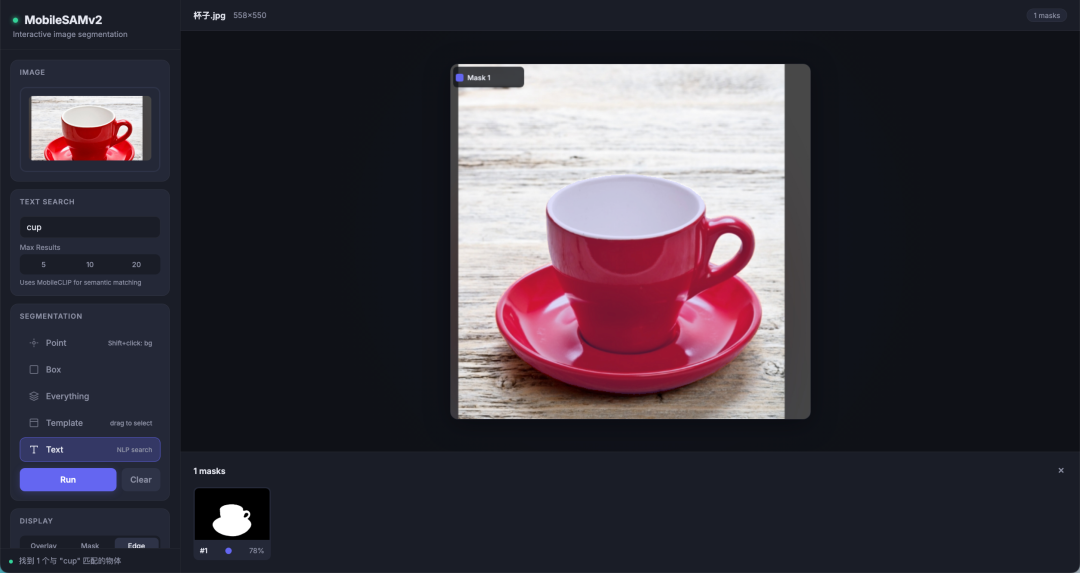
先看5 种 prompt 方式效果
MobileSAMv2 到底是什么
一句话解释:把 SAM 那个 632M 参数的 ViT-H 编码器换成 5M 参数的 TinyViT,剩下的交给一个 prompt-guided mask decoder 精修。
原版 SAM | SAM 3 | MobileSAMv2 | |
|---|---|---|---|
编码器 | ViT-H (632M) | 更大 | TinyViT (5M) |
总体积 | ~2.4 GB | GB 级 | ~56 MB |
CPU 推理 | 跑不动 | 跑不动 | 毫秒级 |
本地部署 | 要 A100 | 要 A100/H100 | 笔记本就行 |
代价是 mask 质量掉 1-2 个 IoU 点,但作为 prompt-driven 工具完全够用。
56MB 是怎么塞下「5 种 Prompt」的
这是这个 Demo 跟其他 SAM 项目最不一样的地方——不是一个 prompt 一种模型,而是同一个 SAM 编码器 + 5 种 prompt 入口。
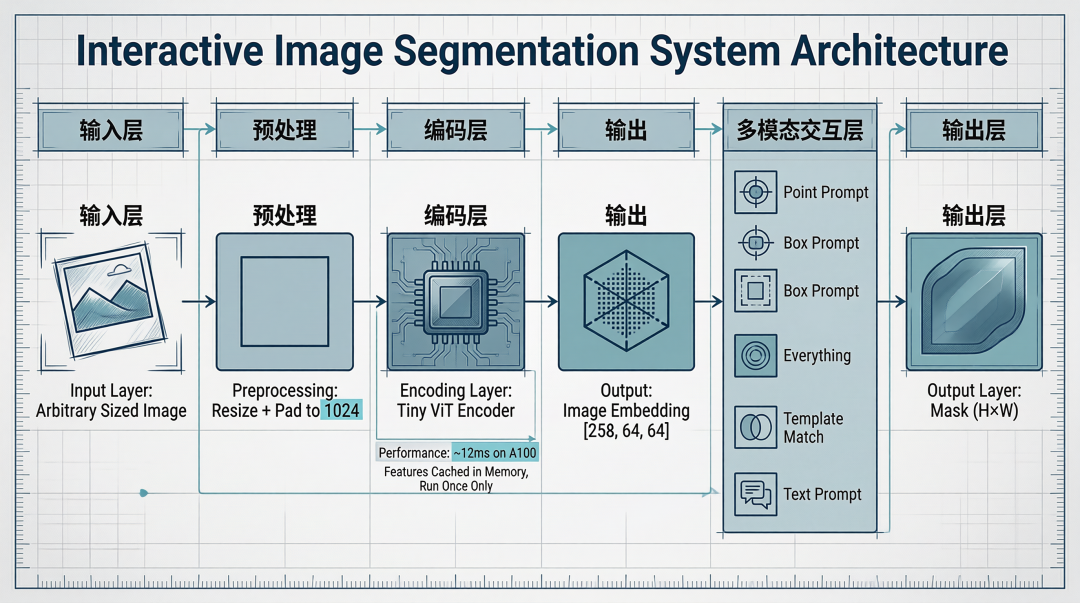
核心 trick:图像编码只跑一次,特征缓存住;之后任意 prompt 都直接走 decoder,毫秒级返回。这是 SAM 系模型比传统分割网络快一个数量级的根本原因。
1. 模型加载:把 TinyViT 塞进 SAM 的壳
这一步最反直觉,但思路很简单。
MobileSAMv2 的权重文件里,编码器是 TinyViT、解码器还是原本 SAM 的结构。state_dict 的 key 按 image_encoder.* 前缀区分两边。加载时分两段:
- 不带前缀的 → 整个 SAM 模型(mask_decoder + prompt_encoder 直接吃)
- 带
image_encoder.前缀的 → 去掉前缀后塞进 TinyViT
加上 strict=False 容忍缺失/多余 key,两边都能装得上。
SamPredictor 负责点/框/模板,SamAutomaticMaskGenerator 负责 everything。两者共用同一个 encoder 实例,避免重复加载和重复前向。
2. 图像预处理:任意图怎么喂给 1024×1024 的网络
SAM 的输入永远是 1024×1024,任意分辨率的图进来都要做一次 resize + pad:
- 长边等比缩放到 1024
- 短边补黑边到 1024
- 归一化用 ImageNet mean/std
关键点:scale 这个值一定要存下来。用户在 800×600 显示的图上点 (x=400, y=300),喂给模型前必须乘 scale,否则点偏。返回 mask 时也要按 scale 还原。这是个非常容易出错的地方。
3. 五种 Prompt 的实现思路
五种接口后端加起来不到 400 行,挨个说思路。
3.1 点击分割(Point Prompt)
最基础。在图上点一个点,给前景/背景标签,SAM 吐 3 个候选 mask。
两个关键:
multimask_output=True必须开,3 个候选按粒度从粗到细排列- 按住 Shift 点是背景标签(label=0),前景会切得更干净
实测 180ms(M1 CPU)。
3.2 框选分割(Box Prompt)
画一个矩形框把目标"框"住。multimask_output=False,只出一个 mask。框 prompt 收敛性比点好,所以只出一个就够了。
实测 180ms。
3.3 自动分割(Everything)
这个模式不传任何 prompt,模型自己把图里所有"东西"切出来。
SAM 内部是这么做的:在图上铺 32×32 的 grid point,每个点都预测一次,最后 NMS 合并。所以一个 1024×1024 的图要跑 1024 次 SAM decode。
优化思路:先把图缩放到 1024 再 everything;按面积排序后再返回前端,太小的 mask 过滤掉。
实测 4.2s 切 50 个 mask(M1 CPU)。
3.4 模板匹配(Template Prompt)
这个最值得说——**"用一张小图找出原图里所有同类物体"**。
思路分两段:先用传统 CV 找候选框,再用 SAM 在每个框中心点精修。
候选框的找法有两种:
- AKAZE 特征点 + 单应性矩阵:抗旋转、抗尺度变化,复杂场景首选
- cv2.matchTemplate 模板匹配:速度快但脆弱,物体变形大了就废
AKAZE 方案的精髓是:模板图和原图分别抽特征点 → KNN 匹配 → Lowe's ratio test 过滤(m.distance < 0.7 * n.distance,0.7 是经验值) → RANSAC 算单应性矩阵 → 把模板的四个角投影到原图得到候选框。
几个我反复试出来的数值:
- Lowe's ratio = 0.7:调到 0.6 会漏检,0.8 全是误匹配
- RANSAC threshold = 5.0:重投影误差 5 像素
- NMS IoU = 0.5:太严会漏相邻物体
找到候选框后再用 SAM 在框中心点做一次 point prompt,匹配 + 精修一条龙。
3.5 文本分割(Text Prompt)
最"魔法"的一个——用自然语言告诉模型你要什么。
单靠 SAM 本身吃不下文本 prompt(SAM 只认点和框),所以要接一个 CLIPSeg 做"文本→粗 mask"。
两阶段 Pipeline:
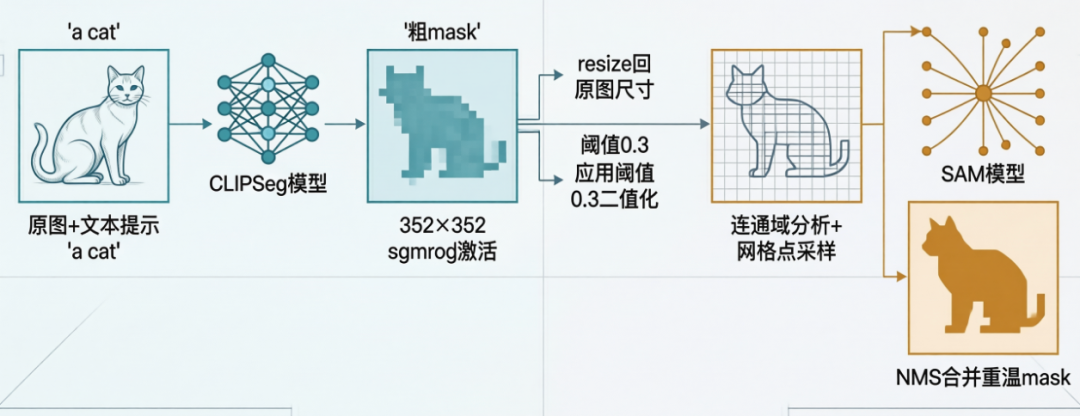
几个让我 debug 到凌晨两点的点:
- CLIPSeg 输出是 352×352,必须 resize 回原图尺寸。第一次没注意,mask 边缘全是锯齿
- 阈值 0.3 偏激进,宁可多召回点,NMS 会兜底
- 网格点比例:每 15000 像素一个点,单区域最多 20 个。否则撒点 N² 爆炸
- NMS 阈值 0.5 太严会保留重复,太松会漏——最后固定在 0.5 跑了一个月没动过
实测 2.1s 找 10 个目标(含 CLIPSeg 推理)。
4. ONNX 导出:让 CPU 推理再快 50%
导出一开始失败,错误是 RuntimeError: Only tensors, lists, tuples of tensors, or dictionary of tensors can be traced。原因是 SAM 内部有个地方用了 int(x.item()),trace 模式下会被当成常量。
思路:把图像尺寸相关的 crop/resize 全部挪到模型外,模型只做纯前向,裁剪/缩放由调用方 Python 端处理。
第二个坑是 dynamic shape。point_coords 的 N 必须声明成动态轴,否则换一个点数就 shape mismatch。ONNX 导出时用 dynamic_axes 显式声明。
加速效果:ONNX 推理比 PyTorch 快 30%-50%,主要是消除了 Python 端 dispatch 开销。
5. 性能数据(M1 MacBook Pro, CPU only)
模式 | 1024×1024 | 1920×1080 | 4K |
|---|---|---|---|
Point | 180ms | 220ms | 380ms |
Box | 180ms | 220ms | 380ms |
Everything (50 mask) | 4.2s | 5.1s | 8.7s |
Text (top_k=10) | 2.1s | 2.6s | 4.5s |
Point/Box 都在 200ms 以内,人眼基本无感。
6. 几个不致命但很烦的坑
- CLIPSeg 第一次加载要下 ~1.3GB 模型。启动时异步加载,别阻塞
/health接口 - mask 边界有时候会漏出物体。把
multimask_output=True时的 3 个候选都画出来,让用户挑分数最高的 - Canvas 在高 DPI 屏模糊。要按
devicePixelRatio缩放 canvas 尺寸和绘图比例 - everything 模式返回上百个 mask。前端按面积排序展示,否则页面卡死
- Safari 下 base64 图片 onload 不触发。原因是 base64 里有换行符,要
.replace(/\s/g, '') - AKAZE 在低纹理图上抽不到特征点(纯色背景)。fallback 到模板匹配方案
7. 怎么从零搭一个
如果想照着抄,按这个顺序:
pip install fastapi uvicorn torch torchvision opencv-python-headless Pillow transformers onnxruntime- 拉 MobileSAMv2 源码,
pip install -e . - 下两个权重:
mobile_sam.pt(40MB)+Prompt_guided_Mask_Decoder.pt(16MB),总 56MB - FastAPI 起 5 个
/segment/*接口,前端用原生 HTML + Canvas 单文件 python3 backend/app.py,浏览器开http://localhost:8000
写在后面
MobileSAMv2 给我的最大启发是:大模型不必从头训,把重的那部分换掉,留住精修模块,能力可以保留 95%。这思路套到很多场景都成立。
SAM 3 那种"全员大模型"路线当然是未来,但对个人开发者、对边缘设备、对今天就要跑起来的需求,56MB + 毫秒级 + 5 种 prompt 仍然是更务实的选择。
后续想试:
- 把 mask decoder 也蒸馏到更小
- 视频版的 track anything
- 在移动端用 NCNN / MNN 部署,目标是 30fps
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号