Debug Agent:智能调试与根因分析


作者: HOS(安全风信子) 日期: 2026-05-24 主要来源平台: GitHub 摘要: 调试是开发中最耗时的环节之一,传统调试方式依赖开发者手动设置断点、逐步执行、观察状态,这种方式在复杂系统中效率极低。Debug Agent 利用 AI 技术理解程序状态、定位问题根因、提出修复方案、甚至自动修复 bug。本文深入讲解 Debug Agent 的核心技术实现:调试接口(JVMTI、debuggerd、Core Dump)的利用、运行时状态提取(变量值序列化与快照)、调用栈分析(栈展开与符号解析)、根因分析(基于模式的错误分类)、修复建议(代码补丁生成与验证),并通过实践章节展示一个支持多语言的 Debug Agent 完整实现。通过本文,开发者将掌握构建智能调试系统的完整知识体系,显著提升调试效率,将传统需要数小时甚至数天的调试工作缩短至分钟级别。
目录- 1. 引言:从手动调试到智能 Debug Agent
- 1.1 调试的困境与 AI 的机遇
- 1.2 Debug Agent 的定义与能力边界
- 1.3 Debug Agent 架构总览
- 2. 调试接口:与目标进程的交互桥梁
- 2.1 调试接口概述
- 2.2 JVMTI:Java 虚拟机工具接口
- 2.2.1 JVMTI 核心概念
- 2.2.2 JVMTI 断点实现原理
- 2.2.3 JVMTI 异常检测与处理
- 2.3 debuggerd:Android 系统级调试守护进程
- 2.3.1 debuggerd 工作原理
- 2.3.2 debuggerd 客户端实现
- 2.4 Core Dump:崩溃现场的全景快照
- 2.4.1 Core Dump 格式与结构
- 2.4.2 Core Dump 解析器实现
- 2.5 调试接口选择策略
- 3. 状态提取:运行时变量的序列化与快照
- 3.1 状态提取的设计目标
- 3.2 变量快照的实现原理
- 3.2.1 变量快照核心实现
- 3.3 状态差异比对算法
- 4. 调用栈分析:栈展开与符号解析
- 4.1 调用栈的基本概念
- 4.2 栈展开原理
- 4.2.1 x86_64 架构栈展开
- 4.2.2 ARM64 架构栈展开
- 4.3 符号解析
- 4.3.1 DWARF 调试信息解析
- 4.4 调用栈可视化
- 5. 根因分析:基于模式的错误分类
- 5.1 错误模式分类体系
- 5.2 异常模式识别引擎
- 5.3 调用栈级别的根因分析
- 6. 修复建议:代码补丁生成与验证
- 6.1 修复建议生成原理
- 6.2 修复建议生成器实现
- 6.3 自动修复的安全机制
- 7. 实践:实现一个支持多语言的 Debug Agent
- 7.1 整体架构设计
- 7.2 核心代码实现
- 7.3 使用示例
- 8. 总结与展望
- 8.1 核心技术总结
- 8.2 未来发展方向
- 8.3 研究建议
- 附录:Debug Agent 完整代码
- 1.1 调试的困境与 AI 的机遇
- 1.2 Debug Agent 的定义与能力边界
- 1.3 Debug Agent 架构总览
- 2.1 调试接口概述
- 2.2 JVMTI:Java 虚拟机工具接口
- 2.2.1 JVMTI 核心概念
- 2.2.2 JVMTI 断点实现原理
- 2.2.3 JVMTI 异常检测与处理
- 2.3 debuggerd:Android 系统级调试守护进程
- 2.3.1 debuggerd 工作原理
- 2.3.2 debuggerd 客户端实现
- 2.4 Core Dump:崩溃现场的全景快照
- 2.4.1 Core Dump 格式与结构
- 2.4.2 Core Dump 解析器实现
- 2.5 调试接口选择策略
- 3.1 状态提取的设计目标
- 3.2 变量快照的实现原理
- 3.2.1 变量快照核心实现
- 3.3 状态差异比对算法
- 4.1 调用栈的基本概念
- 4.2 栈展开原理
- 4.2.1 x86_64 架构栈展开
- 4.2.2 ARM64 架构栈展开
- 4.3 符号解析
- 4.3.1 DWARF 调试信息解析
- 4.4 调用栈可视化
- 5.1 错误模式分类体系
- 5.2 异常模式识别引擎
- 5.3 调用栈级别的根因分析
- 6.1 修复建议生成原理
- 6.2 修复建议生成器实现
- 6.3 自动修复的安全机制
- 7.1 整体架构设计
- 7.2 核心代码实现
- 7.3 使用示例
- 8.1 核心技术总结
- 8.2 未来发展方向
- 8.3 研究建议
1. 引言:从手动调试到智能 Debug Agent
本节为你提供的核心技术价值:理解 Debug Agent 的设计理念与架构层次,掌握其与传统调试器的本质区别,为后续深入学习各核心模块奠定基础。
1.1 调试的困境与 AI 的机遇
在软件工程领域,调试(Debugging)一直占据着开发者大量时间。根据多项行业调查研究[^1],开发者平均每天花费约 2-4 小时进行调试工作,占整个开发周期的 30%-50%。在复杂的分布式系统、嵌入式实时系统或大规模单体应用中,这个比例甚至更高。
传统调试方式存在以下核心痛点:
痛点类型 | 具体表现 | 效率影响 |
|---|---|---|
重复性劳动 | 同样的错误模式需要反复定位 | 人力成本极高 |
上下文丢失 | 复现生产环境问题困难 | 问题定位耗时 |
知识孤岛 | 调试经验难以传承复用 | 组织效率低下 |
规模挑战 | 多线程/分布式状态难以追踪 | 问题复杂度指数级增长 |
Debug Agent 的出现旨在解决这些问题。它利用 AI 的理解、推理和生成能力,将调试过程从手动搜索转变为智能推理,从经验驱动转变为数据驱动。
1.2 Debug Agent 的定义与能力边界
Debug Agent 是一种基于人工智能的调试辅助系统,它能够:
- 理解程序状态:通过各种调试接口获取运行时信息,理解代码执行上下文
- 定位问题根因:通过模式识别、调用栈分析、状态比对等方式找到问题的根本原因
- 提出修复方案:基于问题根因生成代码修复建议或补丁
- 自动修复 bug:在特定条件下自动应用修复方案
然而,Debug Agent 也有其能力边界:
- 无法修复逻辑错误(AI 难以理解业务语义)
- 无法处理硬件故障或内存损坏
- 对某些闭源或混淆代码的调试能力有限
- 自动修复存在风险,需要人工审核
1.3 Debug Agent 架构总览
一个完整的 Debug Agent 系统包含以下核心模块:
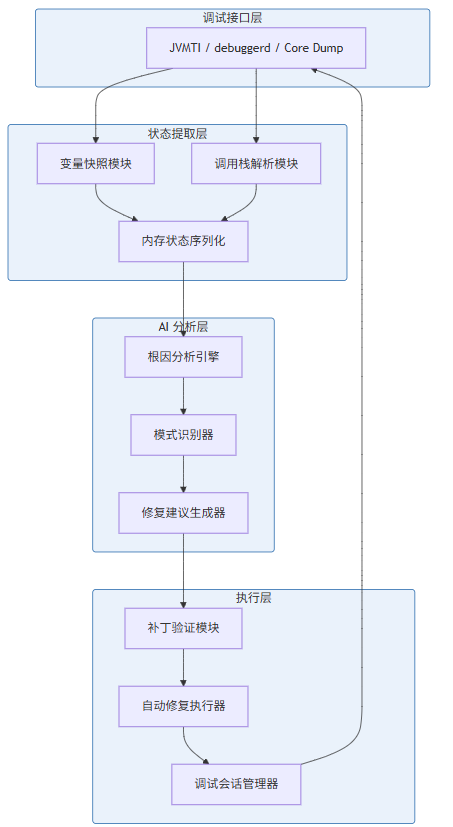
调试接口层负责与目标进程交互,获取运行时信息;状态提取层负责将原始调试信息结构化;AI 分析层负责推理和生成;执行层负责验证和实施修复。
2. 调试接口:与目标进程的交互桥梁
本节为你提供的核心技术价值:掌握 JVMTI、debuggerd、Core Dump 等主流调试接口的原理与使用方法,理解不同场景下的接口选择策略。
2.1 调试接口概述
调试接口是 Debug Agent 与目标进程交互的桥梁。根据交互方式的不同,调试接口可以分为以下几类:
接口类型 | 典型实现 | 交互模式 | 适用场景 |
|---|---|---|---|
JVMTI | JVM Tool Interface | 事件回调 + API 查询 | Java 应用 |
debuggerd | Android Debug Daemon | 协议通信 | Android/Linux 嵌入式 |
Core Dump | 文件格式 | 离线分析 | 崩溃事后分析 |
ptrace | Linux 系统调用 | 进程控制 | 本地调试 |
调试器协议 | GDB Remote Protocol, DAP | 文本/二进制协议 | 跨语言调试 |
2.2 JVMTI:Java 虚拟机工具接口
JVMTI(Java Virtual Machine Tool Interface)是 Java 虚拟机提供的一套标准调试接口,被广泛应用于 Java 程序的调试、监控和诊断。
2.2.1 JVMTI 核心概念
JVMTI 采用事件驱动模型,当虚拟机发生特定事件(如断点、单步执行、异常抛出)时,会回调注册的事件处理函数。同时,调试程序也可以通过 JVMTI API 主动查询虚拟机状态。
关键概念解释:
- JFrame:Java 栈帧,代表一个方法调用
- jthread:Java 线程在 JVMTI 中的表示
- jclass:Java 类在 JVMTI 中的表示
- jmethodID:方法的唯一标识符
- jlocation:方法内的位置(字节码偏移或解释器索引)
2.2.2 JVMTI 断点实现原理
断点是调试中最常用的功能之一。在 JVMTI 中,设置断点的过程如下:
/**
* JVMTI 断点设置示例
* 演示如何在指定方法的指定位置设置断点
*/
#include <jvmti.h>
#include <stdio.h>
#include <string.h>
// 断点回调函数
void JNICALL BreakpointCallback(jvmtiEnv *jvmti_env,
JNIEnv* jni_env,
jthread thread,
jmethodID method,
jlocation location) {
// 获取调用帧信息
jvmtiFrameInfo frames[1];
jint count = 0;
jvmti_env->GetStackTrace(thread, 0, 1, frames, &count);
if (count == 1) {
// 获取方法名
char *method_name = NULL;
char *signature = NULL;
jvmti_env->GetMethodName(frames[0].method, &method_name, &signature, NULL);
printf("[Breakpoint] Thread: %p, Method: %s%s, Location: %lld\n",
thread, method_name, signature, (long long)location);
// 获取局部变量
jvmtiLocalVariableEntry *table = NULL;
jint entry_count = 0;
jvmti_env->GetLocalVariableTable(frames[0].method, &entry_count, &table);
for (int i = 0; i < entry_count; i++) {
jvalue value;
jvmti_env->GetLocalObject(thread, 0, table[i].slot, &value.l);
printf(" Local var '%s' (slot %d): %p\n",
table[i].name, table[i].slot, value.l);
}
// 释放内存
jvmti_env->Deallocate((unsigned char*)method_name);
jvmti_env->Deallocate((unsigned char*)signature);
jvmti_env->Deallocate((unsigned char*)table);
}
}
// 初始化 JVMTI 断点
jvmtiError SetBreakpoint(jvmtiEnv *jvmti_env,
jmethodID method,
jlocation location) {
jvmtiError error;
// 设置断点
error = jvmti_env->SetBreakpoint(method, location);
if (error != JVMTI_ERROR_NONE) {
printf("[Error] Failed to set breakpoint: %d\n", error);
return error;
}
// 注册断点回调
jvmtiEventCallbacks callbacks;
memset(&callbacks, 0, sizeof(callbacks));
callbacks.Breakpoint = BreakpointCallback;
error = jvmti_env->SetEventCallbacks(&callbacks, sizeof(callbacks));
if (error != JVMTI_ERROR_NONE) {
printf("[Error] Failed to set event callbacks: %d\n", error);
return error;
}
// 启用断点事件
error = jvmti_env->SetEventNotificationMode(JVMTI_ENABLE,
JVMTI_EVENT_BREAKPOINT,
NULL);
return error;
}2.2.3 JVMTI 异常检测与处理
JVMTI 提供了完善的异常事件处理机制,可以在异常抛出和捕获时获得通知:
/**
* JVMTI 异常检测示例
* 演示如何拦截和分析 Java 异常
*/
#include <jvmti.h>
#include <jni.h>
#include <stdio.h>
#include <string.h>
// 异常回调数据结构
typedef struct {
char exception_class[256];
char exception_message[1024];
char throw_method[256];
jlocation throw_location;
char catch_method[256];
jlocation catch_location;
int is_uncaught;
} ExceptionInfo;
// 异常抛出回调
void JNICALL ExceptionCallback(jvmtiEnv *jvmti_env,
JNIEnv* jni_env,
jthread thread,
jmethodID method,
jlocation location,
jobject exception,
jmethodID catch_method,
jlocation catch_location) {
ExceptionInfo info = {0};
// 获取异常类型
jclass exception_class = jni_env->GetObjectClass(exception);
char *class_sig = NULL;
jvmti_env->GetClassSignature(exception_class, &class_sig, NULL);
if (class_sig) {
strncpy(info.exception_class, class_sig, sizeof(info.exception_class) - 1);
jvmti_env->Deallocate((unsigned char*)class_sig);
}
// 获取异常消息
jmethodID get_message = jni_env->GetMethodID(exception_class, "toString", "()Ljava/lang/String;");
if (get_message) {
jstring msg = (jstring)jni_env->CallObjectMethod(exception, get_message);
if (msg) {
const char *msg_str = jni_env->GetStringUTFChars(msg, NULL);
if (msg_str) {
strncpy(info.exception_message, msg_str,
sizeof(info.exception_message) - 1);
jni_env->ReleaseStringUTFChars(msg, msg_str);
}
}
}
// 获取抛出位置
char *method_name = NULL;
jvmti_env->GetMethodName(method, &method_name, NULL, NULL);
if (method_name) {
strncpy(info.throw_method, method_name, sizeof(info.throw_method) - 1);
jvmti_env->Deallocate((unsigned char*)method_name);
}
info.throw_location = location;
// 获取捕获位置(如果是 caught 异常)
if (catch_method) {
jvmti_env->GetMethodName(catch_method, &method_name, NULL, NULL);
if (method_name) {
strncpy(info.catch_method, method_name, sizeof(info.catch_method) - 1);
jvmti_env->Deallocate((unsigned char*)method_name);
}
info.catch_location = catch_location;
}
// 判断是否未捕获
info.is_uncaught = (catch_method == NULL);
// 输出异常信息
printf("[Exception] %s: %s\n", info.exception_class, info.exception_message);
printf(" Thrown at: %s:%lld\n", info.throw_method, (long long)location);
if (info.is_uncaught) {
printf(" Status: UNCAUGHT (will propagate)\n");
} else {
printf(" Caught at: %s:%lld\n", info.catch_method, (long long)catch_location);
}
}
// 设置异常监控
jvmtiError SetupExceptionMonitoring(jvmtiEnv *jvmti_env) {
jvmtiEventCallbacks callbacks;
memset(&callbacks, 0, sizeof(callbacks));
callbacks.Exception = ExceptionCallback;
callbacks.ExceptionCatch = ExceptionCallback;
jvmtiError error = jvmti_env->SetEventCallbacks(&callbacks, sizeof(callbacks));
if (error != JVMTI_ERROR_NONE) {
return error;
}
// 启用异常事件
error = jvmti_env->SetEventNotificationMode(JVMTI_ENABLE,
JVMTI_EVENT_EXCEPTION,
NULL);
if (error != JVMTI_ERROR_NONE) {
return error;
}
error = jvmti_env->SetEventNotificationMode(JVMTI_ENABLE,
JVMTI_EVENT_EXCEPTION_CATCH,
NULL);
return error;
}2.3 debuggerd:Android 系统级调试守护进程
debuggerd 是 Android 系统中专门负责处理 native 进程崩溃的守护进程。它能够捕获 crash 信号、收集栈信息、生成 tombstone 文件。
2.3.1 debuggerd 工作原理
debuggerd 利用 Linux 的 ptrace 机制attach 到崩溃进程,获取寄存器上下文、调用栈等信息。其工作流程如下:
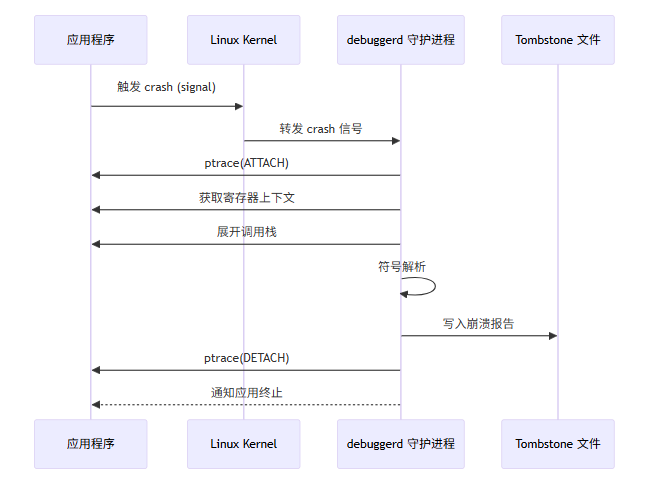
2.3.2 debuggerd 客户端实现
在 Debug Agent 中,我们需要实现一个 debuggerd 客户端来主动发起调试请求:
/**
* debuggerd 客户端实现
* 用于主动获取 native 进程的调试信息
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <errno.h>
#include <signal.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <sys/un.h>
// debuggerd socket path
#define DEBUGGERD_SOCKET_PATH "/dev/socket/debuggerd"
#define DEBUGGERD_MAX_MSG_SIZE 4096
// 调试请求类型
typedef enum {
DEBUGGERD_REQUEST_REGISTER,
DEBUGGERD_REQUEST_UNREGISTER,
DEBUGGERD_REQUEST_CRASH,
DEBUGGERD_REQUEST_TOMBSTONE,
DEBUGGERD_REQUEST_DUMP_TOMBSTONE,
DEBUGGERD_REQUEST_ANR,
} debuggerd_request_type;
// 协议头结构
typedef struct __attribute__((packed)) {
uint32_t request_type;
uint32_t pid;
uint32_t uid;
} debugger_request_header;
// 协议响应结构
typedef struct __attribute__((packed)) {
int32_t return_code;
int32_t tombstone_fd;
int32_t timeout_ms;
} debugger_response_header;
/**
* 向 debuggerd 发送崩溃请求
* @param pid 目标进程 ID
* @param uid 目标用户 ID
* @param response 响应结构体指针
* @return 成功返回 0,失败返回 -1
*/
int debuggerd_request_crash(pid_t pid, uid_t uid, debugger_response_header *response) {
int sock = -1;
struct sockaddr_un addr;
int ret = -1;
// 创建 UNIX domain socket
sock = socket(AF_UNIX, SOCK_SOCKET, 0);
if (sock < 0) {
printf("[Error] Failed to create socket: %s\n", strerror(errno));
return -1;
}
// 连接 debuggerd
memset(&addr, 0, sizeof(addr));
addr.sun_family = AF_UNIX;
strncpy(addr.sun_path, DEBUGGERD_SOCKET_PATH, sizeof(addr.sun_path) - 1);
if (connect(sock, (struct sockaddr*)&addr, sizeof(addr)) < 0) {
printf("[Error] Failed to connect to debuggerd: %s\n", strerror(errno));
goto cleanup;
}
// 构造请求
debugger_request_header request;
request.request_type = DEBUGGERD_REQUEST_CRASH;
request.pid = pid;
request.uid = uid;
// 发送请求
if (write(sock, &request, sizeof(request)) != sizeof(request)) {
printf("[Error] Failed to send request: %s\n", strerror(errno));
goto cleanup;
}
// 接收响应
if (read(sock, response, sizeof(*response)) != sizeof(*response)) {
printf("[Error] Failed to receive response: %s\n", strerror(errno));
goto cleanup;
}
ret = 0;
cleanup:
if (sock >= 0) {
close(sock);
}
return ret;
}
/**
* 获取进程的 tombstone 信息
* @param pid 目标进程 ID
* @param tombstone_output 输出缓冲区
* @param output_size 缓冲区大小
* @return 成功返回 tombstone 数量,失败返回 -1
*/
int debuggerd_get_tombstone(pid_t pid, char *tombstone_output, size_t output_size) {
char tombstone_path[64];
FILE *fp = NULL;
int count = 0;
// 遍历查找 tombstone 文件
for (int i = 0; i < 10; i++) {
snprintf(tombstone_path, sizeof(tombstone_path),
"/data/tombstones/tombstone_%02d", i);
if (access(tombstone_path, R_OK) == 0) {
fp = fopen(tombstone_path, "r");
if (fp) {
size_t len = fread(tombstone_output, 1, output_size - 1, fp);
tombstone_output[len] = '\0';
fclose(fp);
count++;
break;
}
}
}
return count;
}2.4 Core Dump:崩溃现场的全景快照
Core Dump 是进程崩溃时保存在磁盘中的内存镜像,包含了进程的完整状态信息。对于事后分析和调试,Core Dump 是最重要的数据来源。
2.4.1 Core Dump 格式与结构
Linux 下的 Core Dump 采用 ELF(Executable and Linkable Format)格式,包含以下关键section:
Section | 描述 | 调试信息价值 |
|---|---|---|
PT_LOAD | 内存段映射 | 恢复进程内存状态 |
PT_NOTE | 进程元信息 | 获取 PID、信号、寄存器 |
.debug_info | DWARF 调试信息 | 符号解析、类型信息 |
.debug_line | 行号表 | 源码位置映射 |
.debug_str | 调试字符串 | 变量名、类型名等 |
2.4.2 Core Dump 解析器实现
"""
Core Dump 解析器实现
使用 pyelftools 解析 ELF 格式的 core dump 文件
"""
from elftools.common.exceptions import ELFParseError
from elftools.elf.elffile import ELFFile
import struct
import os
class CoreDumpParser:
"""Core Dump 解析器,用于提取崩溃现场信息"""
def __init__(self, core_path):
self.core_path = core_path
self.elf = None
self.program_headers = []
self.note_segments = []
self.debug_info = None
def open(self):
"""打开并解析 Core Dump 文件"""
if not os.path.exists(self.core_path):
raise FileNotFoundError(f"Core dump file not found: {self.core_path}")
with open(self.core_path, 'rb') as f:
self.elf = ELFFile(f)
if self.elf.get_machine_arch() != 'x86_64':
raise ValueError(f"Unsupported architecture: {self.elf.get_machine_arch()}")
self._parse_program_headers()
self._parse_note_segments()
return self
def _parse_program_headers(self):
"""解析程序头,获取内存段信息"""
for phdr in self.elf.iter_phdrs():
self.program_headers.append({
'p_type': phdr['p_type'],
'p_offset': phdr['p_offset'],
'p_vaddr': phdr['p_vaddr'],
'p_filesz': phdr['p_filesz'],
'p_memsz': phdr['p_memsz'],
'p_flags': phdr['p_flags']
})
def _parse_note_segments(self):
"""解析 Note 段,获取进程元信息"""
for phdr in self.elf.iter_phdrs():
if phdr['p_type'] == 'PT_NOTE':
self.elf.stream.seek(phdr['p_offset'])
note_data = self.elf.stream.read(phdr['p_filesz'])
offset = 0
while offset < len(note_data):
# 解析 note header
namesz, descsz, ntype = struct.unpack('<III',
note_data[offset:offset + 12])
offset += 12
# 读取 name
name = note_data[offset:offset + namesz]
offset += namesz
offset = (offset + 3) & ~3 # 4字节对齐
# 读取 desc
desc = note_data[offset:offset + descsz]
offset += descsz
offset = (offset + 3) & ~3 # 4字节对齐
self.note_segments.append({
'name': name.rstrip(b'\x00').decode('utf-8', errors='ignore'),
'type': ntype,
'desc': desc
})
def get_process_info(self):
"""从 Note 段提取进程信息"""
prstatus = None
prpsinfo = None
for note in self.note_segments:
if note['name'] == 'CORE':
if note['type'] == 1: # NT_PRSTATUS
prstatus = self._parse_prstatus(note['desc'])
elif note['type'] == 3: # NT_PRPSINFO
prpsinfo = self._parse_prpsinfo(note['desc'])
return {
'prstatus': prstatus,
'prpsinfo': prpsinfo
}
def _parse_prstatus(self, desc):
"""解析 prstatus 结构(x86_64)"""
if len(desc) < 296:
return None
return {
'pid': struct.unpack('<i', desc[48:52])[0],
'ppid': struct.unpack('<i', desc[52:56])[0],
'pgrp': struct.unpack('<i', desc[56:60])[0],
'sid': struct.unpack('<i', desc[60:64])[0],
'regs': struct.unpack('<29q', desc[112:344]), # 29 64-bit registers
'signal': struct.unpack('<h', desc[16:18])[0]
}
def _parse_prpsinfo(self, desc):
"""解析 prpsinfo 结构"""
if len(desc) < 136:
return None
# 提取进程名(16字节)和命令行参数
pr_state = desc[8]
pr_sname = desc[9]
pr_zomb = desc[10]
pr_nice = desc[11]
# 进程名
pr_pid = struct.unpack('<i', desc[12:16])[0]
pr_ppid = struct.unpack('<i', desc[16:20])[0]
pr_pgrp = struct.unpack('<i', desc[20:24])[0]
pr_sid = struct.unpack('<i', desc[24:28])[0]
# 提取命令行
pr_fname = desc[32:48].rstrip(b'\x00').decode('utf-8', errors='ignore')
pr_psargs = desc[48:128].rstrip(b'\x00').decode('utf-8', errors='ignore')
return {
'pid': pr_pid,
'ppid': pr_ppid,
'pgrp': pr_pgrp,
'sid': pr_sid,
'state': pr_state,
'name': pr_fname,
'args': pr_psargs
}
def get_registers(self):
"""获取崩溃时的寄存器状态"""
for note in self.note_segments:
if note['name'] == 'CORE' and note['type'] == 1: # NT_PRSTATUS
prstatus = self._parse_prstatus(note['desc'])
if prstatus:
regs = prstatus['regs']
return {
'rax': regs[0], 'rbx': regs[1], 'rcx': regs[2], 'rdx': regs[3],
'rsi': regs[4], 'rdi': regs[5], 'rbp': regs[6], 'rsp': regs[7],
'r8': regs[8], 'r9': regs[9], 'r10': regs[10], 'r11': regs[11],
'r12': regs[12], 'r13': regs[13], 'r14': regs[14], 'r15': regs[15],
'rip': regs[16], 'cs': regs[17], 'rflags': regs[18], 'ss': regs[20],
}
return None
def dump_memory_regions(self):
"""导出所有内存段信息"""
regions = []
for phdr in self.program_headers:
if phdr['p_type'] == 'PT_LOAD' and phdr['p_filesz'] > 0:
regions.append({
'vaddr': hex(phdr['p_vaddr']),
'size': phdr['p_filesz'],
'offset': phdr['p_offset'],
'flags': phdr['p_flags']
})
return regions
# 使用示例
if __name__ == '__main__':
parser = CoreDumpParser('/data/tombstones/core_dump_0')
try:
parser.open()
# 获取进程信息
info = parser.get_process_info()
print(f"PID: {info['prstatus']['pid']}")
print(f"Signal: {info['prstatus']['signal']}")
# 获取寄存器
regs = parser.get_registers()
if regs:
print(f"RIP: {hex(regs['rip'])}")
print(f"RSP: {hex(regs['rsp'])}")
print(f"RBP: {hex(regs['rbp'])}")
# 获取内存段
regions = parser.dump_memory_regions()
for r in regions[:5]:
print(f" {r['vaddr']} - +{hex(r['size'])} ({r['flags']})")
except ELFParseError as e:
print(f"Failed to parse core dump: {e}")2.5 调试接口选择策略
在实际项目中,选择合适的调试接口需要考虑多个因素:
因素 | JVMTI | debuggerd | Core Dump | ptrace |
|---|---|---|---|---|
语言支持 | Java 专用 | C/C++/Native | C/C++/Native | C/C++/Native |
实时性 | 高 | 中 | 低(事后) | 高 |
性能开销 | 中等 | 较低 | 无(崩溃时) | 较高 |
信息完整度 | 高 | 高 | 取决于配置 | 取决于实现 |
平台依赖 | 跨平台 | Android/Linux | 通用 | Linux only |
自动化难度 | 中等 | 较高 | 低 | 高 |
选择建议:
- Java 应用:优先使用 JVMTI,可获得最完整的调试信息
- Android Native 开发:使用 debuggerd,可获取 tombstone 和 ANR 信息
- 事后分析:使用 Core Dump,支持离线分析
- 通用调试:使用 ptrace,灵活性最高
3. 状态提取:运行时变量的序列化与快照
本节为你提供的核心技术价值:掌握变量值序列化、内存快照、状态差异比对的核心算法,实现 Debug Agent 的运行时状态提取能力。
3.1 状态提取的设计目标
状态提取是 Debug Agent 的核心能力之一。一个设计良好的状态提取系统需要满足以下目标:
目标 | 描述 | 优先级 |
|---|---|---|
完整性 | 提取所有相关变量和状态 | P0 |
一致性 | 保证在同一时间点的状态一致性 | P0 |
可序列化 | 状态可传输、存储和分析 | P0 |
低开销 | 对目标进程影响最小 | P1 |
可扩展 | 支持新数据类型和自定义序列化 | P1 |
3.2 变量快照的实现原理
变量快照(Variable Snapshot)是在特定时刻捕获的变量值集合。由于程序状态的复杂性和多线程特性,快照需要解决以下挑战:
- 时间一致性:多线程环境下,不同变量的值可能来自不同时间点
- 引用处理:指针和引用的值可能指向已释放的内存
- 大对象:数组、字符串等大对象需要特殊处理
- 类型解析:需要 DWARF 等调试信息来理解变量类型
3.2.1 变量快照核心实现
/**
* 变量快照系统实现
* 支持基础类型、指针、数组、结构体的序列化
*/
#include <stdint.h>
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
#include <stdbool.h>
// 类型枚举
typedef enum {
VT_INT8 = 0,
VT_INT16 = 1,
VT_INT32 = 2,
VT_INT64 = 3,
VT_UINT8 = 4,
VT_UINT16 = 5,
VT_UINT32 = 6,
VT_UINT64 = 7,
VT_FLOAT = 8,
VT_DOUBLE = 9,
VT_POINTER = 10,
VT_ARRAY = 11,
VT_STRUCT = 12,
VT_STRING = 13,
VT_UNKNOWN = 99
} VariableType;
// 值联合体
typedef union {
int64_t int_val;
uint64_t uint_val;
double double_val;
void* ptr_val;
} VariableValue;
// 变量描述符
typedef struct Variable {
char* name;
char* type_name;
VariableType type;
VariableValue value;
uint32_t size;
bool is_null;
bool is_pointer;
int pointer_depth;
struct Variable* children; // 用于数组/结构体
int child_count;
int child_capacity;
} Variable;
// 快照结构
typedef struct Snapshot {
Variable* variables;
int count;
int capacity;
uint64_t timestamp_ns;
uint64_t thread_id;
void* context; // 调试上下文指针
} Snapshot;
// 快照上下文
typedef struct SnapshotContext {
void* debug_info; // DWARF 调试信息
void* process_memory; // 进程内存读取接口
uint64_t global_base; // 全局变量基址
uint64_t stack_base; // 栈基址
uint64_t stack_limit; // 栈边界
} SnapshotContext;
// 内存读取函数指针类型
typedef bool (*ReadMemoryFunc)(void* ctx, uint64_t addr, void* buf, size_t size);
// ============== 变量管理 ==============
Variable* variable_create(const char* name, const char* type_name, VariableType type) {
Variable* var = (Variable*)calloc(1, sizeof(Variable));
if (!var) return NULL;
var->name = strdup(name ? name : "");
var->type_name = strdup(type_name ? type_name : "unknown");
var->type = type;
var->is_null = true;
var->pointer_depth = 0;
return var;
}
void variable_free(Variable* var) {
if (!var) return;
free(var->name);
free(var->type_name);
// 递归释放子变量
if (var->children) {
for (int i = 0; i < var->child_count; i++) {
variable_free(&var->children[i]);
}
free(var->children);
}
free(var);
}
void variable_set_value(Variable* var, VariableValue value) {
var->value = value;
var->is_null = false;
}
void variable_add_child(Variable* parent, Variable* child) {
if (!parent || !child) return;
// 扩容检查
if (parent->child_count >= parent->child_capacity) {
int new_cap = parent->child_capacity == 0 ? 4 : parent->child_capacity * 2;
Variable* new_children = (Variable*)realloc(parent->children,
new_cap * sizeof(Variable));
if (!new_children) return;
parent->children = new_children;
parent->child_capacity = new_cap;
}
parent->children[parent->child_count++] = *child;
free(child); // 释放临时分配的结构体,内容已拷贝
}
// ============== 快照管理 ==============
Snapshot* snapshot_create(int initial_capacity) {
Snapshot* snap = (Snapshot*)calloc(1, sizeof(Snapshot));
if (!snap) return NULL;
snap->capacity = initial_capacity > 0 ? initial_capacity : 16;
snap->variables = (Variable*)calloc(snap->capacity, sizeof(Variable));
if (!snap->variables) {
free(snap);
return NULL;
}
snap->timestamp_ns = 0;
snap->thread_id = 0;
snap->context = NULL;
return snap;
}
void snapshot_free(Snapshot* snap) {
if (!snap) return;
for (int i = 0; i < snap->count; i++) {
variable_free(&snap->variables[i]);
}
free(snap->variables);
free(snap);
}
void snapshot_add_variable(Snapshot* snap, Variable* var) {
if (!snap || !var) return;
// 扩容检查
if (snap->count >= snap->capacity) {
snap->capacity *= 2;
Variable* new_vars = (Variable*)realloc(snap->variables,
snap->capacity * sizeof(Variable));
if (!new_vars) return;
snap->variables = new_vars;
}
snap->variables[snap->count++] = *var;
free(var);
}
// ============== 快照序列化 ==============
typedef struct {
char* buffer;
size_t capacity;
size_t offset;
} SerializedOutput;
void ser_init(SerializedOutput* ser, size_t initial_capacity) {
ser->capacity = initial_capacity > 0 ? initial_capacity : 4096;
ser->buffer = (char*)malloc(ser->capacity);
ser->offset = 0;
}
void ser_free(SerializedOutput* ser) {
if (ser->buffer) free(ser->buffer);
}
void ser_ensure_capacity(SerializedOutput* ser, size_t needed) {
while (ser->offset + needed > ser->capacity) {
ser->capacity *= 2;
ser->buffer = (char*)realloc(ser->buffer, ser->capacity);
}
}
void ser_write(SerializedOutput* ser, const void* data, size_t size) {
ser_ensure_capacity(ser, size);
memcpy(ser->buffer + ser->offset, data, size);
ser->offset += size;
}
void ser_write_string(SerializedOutput* ser, const char* str) {
size_t len = strlen(str);
ser_write(ser, &len, sizeof(len));
ser_write(ser, str, len);
}
void ser_write_variable(SerializedOutput* ser, Variable* var) {
// 写入类型
ser_write(ser, &var->type, sizeof(var->type));
// 写入名称
ser_write_string(ser, var->name);
// 写入类型名
ser_write_string(ser, var->type_name);
// 写入大小
ser_write(ser, &var->size, sizeof(var->size));
// 写入空标志
ser_write(ser, &var->is_null, sizeof(var->is_null));
if (!var->is_null) {
// 写入值
ser_write(ser, &var->value, sizeof(var->value));
// 写入指针深度
ser_write(ser, &var->pointer_depth, sizeof(var->pointer_depth));
// 递归写入子变量
ser_write(ser, &var->child_count, sizeof(var->child_count));
for (int i = 0; i < var->child_count; i++) {
ser_write_variable(ser, &var->children[i]);
}
}
}
char* snapshot_serialize(Snapshot* snap, size_t* out_size) {
SerializedOutput ser;
ser_init(&ser, snap->count * 256 + 1024);
// 写入快照头
ser_write(&ser, &snap->timestamp_ns, sizeof(snap->timestamp_ns));
ser_write(&ser, &snap->thread_id, sizeof(snap->thread_id));
ser_write(&ser, &snap->count, sizeof(snap->count));
// 写入变量列表
for (int i = 0; i < snap->count; i++) {
ser_write_variable(&ser, &snap->variables[i]);
}
if (out_size) *out_size = ser.offset;
char* result = ser.buffer;
ser.buffer = NULL;
ser_free(&ser);
return result;
}3.3 状态差异比对算法
当 Debug Agent 获取了多个状态的快照后,需要能够比对差异,找出导致问题的状态变化。这对于定位 bug 的触发条件尤为重要。
"""
状态快照差异分析器
实现两个快照之间的差异检测和可视化
"""
from dataclasses import dataclass, field
from typing import Dict, List, Set, Optional, Any
from enum import Enum
import json
class ChangeType(Enum):
"""变化类型枚举"""
ADDED = "added"
REMOVED = "removed"
MODIFIED = "modified"
TYPE_CHANGED = "type_changed"
REFERENCE_CHANGED = "reference_changed"
UNCHANGED = "unchanged"
@dataclass
class FieldPath:
"""字段路径,用于定位嵌套结构中的字段"""
segments: List[str] = field(default_factory=list)
def __str__(self):
return ".".join(self.segments) if self.segments else "<root>"
def __hash__(self):
return hash(str(self))
def __eq__(self, other):
return str(self) == str(other)
@dataclass
class ValueChange:
"""值变化记录"""
path: FieldPath
change_type: ChangeType
old_value: Any = None
new_value: Any = None
old_type: Optional[str] = None
new_type: Optional[str] = None
depth: int = 0
@dataclass
class DiffResult:
"""差异分析结果"""
changes: List[ValueChange] = field(default_factory=list)
added_count: int = 0
removed_count: int = 0
modified_count: int = 0
def summary(self) -> str:
total = len(self.changes)
return (f"Total changes: {total} "
f"(+{self.added_count} "
f"-{self.removed_count} "
f"~{self.modified_count})")
def has_critical_changes(self, max_changes: int = 10) -> bool:
"""判断是否有重大变化"""
return len(self.changes) > max_changes
class SnapshotDiffer:
"""快照差异分析器"""
def __init__(self, ignore_patterns: Optional[List[str]] = None):
self.ignore_patterns = ignore_patterns or []
def should_ignore(self, path: FieldPath) -> bool:
"""检查路径是否应该被忽略"""
path_str = str(path)
for pattern in self.ignore_patterns:
if pattern.startswith("*."):
suffix = pattern[2:]
if path_str.endswith(suffix):
return True
elif path_str == pattern:
return True
return False
def diff_snapshots(self, old: Dict, new: Dict,
path: Optional[FieldPath] = None) -> List[ValueChange]:
"""计算两个快照之间的差异"""
if path is None:
path = FieldPath()
changes = []
old_keys = set(old.keys()) if isinstance(old, dict) else set()
new_keys = set(new.keys()) if isinstance(new, dict) else set()
# 检测新增
for key in new_keys - old_keys:
if self.should_ignore(FieldPath(path.segments + [key])):
continue
change = ValueChange(
path=FieldPath(path.segments + [key]),
change_type=ChangeType.ADDED,
new_value=new[key],
depth=len(path.segments)
)
changes.append(change)
# 检测删除
for key in old_keys - new_keys:
if self.should_ignore(FieldPath(path.segments + [key])):
continue
change = ValueChange(
path=FieldPath(path.segments + [key]),
change_type=ChangeType.REMOVED,
old_value=old[key],
depth=len(path.segments)
)
changes.append(change)
# 检测修改
for key in old_keys & new_keys:
current_path = FieldPath(path.segments + [key])
if self.should_ignore(current_path):
continue
old_val = old[key]
new_val = new[key]
old_type = type(old_val).__name__
new_type = type(new_val).__name__
if old_type != new_type:
change = ValueChange(
path=current_path,
change_type=ChangeType.TYPE_CHANGED,
old_value=old_val,
new_value=new_val,
old_type=old_type,
new_type=new_type,
depth=len(path.segments)
)
changes.append(change)
elif isinstance(old_val, dict) and isinstance(new_val, dict):
changes.extend(self.diff_snapshots(old_val, new_val, current_path))
elif isinstance(old_val, list) and isinstance(new_val, list):
changes.extend(self._diff_lists(old_val, new_val, current_path))
elif old_val != new_val:
change = ValueChange(
path=current_path,
change_type=ChangeType.MODIFIED,
old_value=old_val,
new_value=new_val,
depth=len(path.segments)
)
changes.append(change)
return changes
def _diff_lists(self, old_list: List, new_list: List,
path: FieldPath) -> List[ValueChange]:
"""比较两个列表的差异"""
changes = []
max_len = max(len(old_list), len(new_list))
for i in range(max_len):
item_path = FieldPath(path.segments + [f"[{i}]"])
if i >= len(old_list):
changes.append(ValueChange(
path=item_path,
change_type=ChangeType.ADDED,
new_value=new_list[i],
depth=len(path.segments) + 1
))
elif i >= len(new_list):
changes.append(ValueChange(
path=item_path,
change_type=ChangeType.REMOVED,
old_value=old_list[i],
depth=len(path.segments) + 1
))
else:
old_item = old_list[i]
new_item = new_list[i]
if isinstance(old_item, dict) and isinstance(new_item, dict):
changes.extend(self.diff_snapshots(old_item, new_item, item_path))
elif old_item != new_item:
changes.append(ValueChange(
path=item_path,
change_type=ChangeType.MODIFIED,
old_value=old_item,
new_value=new_item,
depth=len(path.segments) + 1
))
return changes
def generate_diff_report(self, old: Dict, new: Dict) -> str:
"""生成差异报告"""
changes = self.diff_snapshots(old, new)
result = DiffResult()
for change in changes:
if change.change_type == ChangeType.ADDED:
result.added_count += 1
elif change.change_type == ChangeType.REMOVED:
result.removed_count += 1
elif change.change_type == ChangeType.MODIFIED:
result.modified_count += 1
lines = []
lines.append("=" * 60)
lines.append("SNAPSHOT DIFF REPORT")
lines.append("=" * 60)
lines.append(f"Summary: {result.summary()}")
lines.append("")
if not changes:
lines.append("No changes detected.")
return "\n".join(lines)
lines.append("CHANGES:")
lines.append("-" * 60)
for change in changes:
path_str = str(change.path)
if change.change_type == ChangeType.ADDED:
lines.append(f"[+] {path_str}")
lines.append(f" Value: {self._format_value(change.new_value)}")
elif change.change_type == ChangeType.REMOVED:
lines.append(f"[-] {path_str}")
lines.append(f" Value: {self._format_value(change.old_value)}")
elif change.change_type == ChangeType.MODIFIED:
lines.append(f"[~] {path_str}")
lines.append(f" Old: {self._format_value(change.old_value)}")
lines.append(f" New: {self._format_value(change.new_value)}")
elif change.change_type == ChangeType.TYPE_CHANGED:
lines.append(f"[!] {path_str} (TYPE CHANGE)")
lines.append(f" {change.old_type} -> {change.new_type}")
lines.append("=" * 60)
return "\n".join(lines)
def _format_value(self, value: Any, max_len: int = 80) -> str:
"""格式化值显示"""
if value is None:
return "null"
if isinstance(value, str):
if len(value) > max_len:
return f'"{value[:max_len]}..."'
return f'"{value}"'
if isinstance(value, (int, float, bool)):
return str(value)
if isinstance(value, (list, dict)):
s = json.dumps(value, ensure_ascii=False)
if len(s) > max_len:
return s[:max_len] + "..."
return s
return repr(value)
# 使用示例
if __name__ == '__main__':
differ = SnapshotDiffer(ignore_patterns=["*.timestamp", "*.hash"])
old_state = {
"user": {
"id": 12345,
"name": "Alice",
"balance": 1000.0,
"status": "active",
"tags": ["premium", "vip"]
},
"session": {
"id": "abc123",
"expires": 1700000000
}
}
new_state = {
"user": {
"id": 12345,
"name": "Alice",
"balance": 950.0,
"status": "active",
"tags": ["premium", "vip", "beta"]
},
"session": {
"id": "def456",
"expires": 1700000000
}
}
report = differ.generate_diff_report(old_state, new_state)
print(report)4. 调用栈分析:栈展开与符号解析
本节为你提供的核心技术价值:掌握调用栈展开的原理与实现、符号解析的机制,以及栈帧重建的核心算法,使 Debug Agent 能够准确定位代码执行路径。
4.1 调用栈的基本概念
调用栈(Call Stack)是程序运行时维护的一个栈结构,用于跟踪函数调用关系。当一个函数调用另一个函数时,新的栈帧(Stack Frame)被压入栈顶;当函数返回时,对应的栈帧被弹出。
栈帧包含的信息:
信息类型 | 描述 | 可信度 |
|---|---|---|
返回地址 | 调用者代码中的位置 | 高 |
参数 | 函数调用时传入的参数 | 高 |
局部变量 | 函数内部定义的变量 | 中(可能已优化) |
保存的寄存器 | 需要跨函数调用保存的寄存器值 | 高 |
栈指针 (RSP/RBP) | 当前栈帧的位置 | 高 |
帧指针 (RBP) | 用于回溯栈帧链 | 中(可能被省略) |
4.2 栈展开原理
栈展开(Stack Unwinding)是从当前栈帧开始,回溯整个调用栈的过程。不同平台和架构有不同的栈展开机制。
4.2.1 x86_64 架构栈展开
在 x86_64 架构中,栈展开主要依赖以下信息:
- 帧指针链 (Frame Pointer Chain):RBP 寄存器形成一个链,每个 RBP 指向调用者的 RBP
- 返回地址:每个栈帧中保存的返回地址,位于函数 prologue 之后
- DWARF 信息:调试信息提供精确的栈布局
/**
* x86_64 架构栈展开实现
* 支持帧指针链和启发式展开两种模式
*/
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdbool.h>
#ifdef __x86_64__
// 寄存器名称枚举
typedef enum {
RAX = 0, RBX = 1, RCX = 2, RDX = 3,
RSI = 4, RDI = 5, RBP = 6, RSP = 7,
R8 = 8, R9 = 9, R10 = 10, R11 = 11,
R12 = 12, R13 = 13, R14 = 14, R15 = 15,
RIP = 16, FLAGS = 17, CS = 18, SS = 19,
DS = 20, ES = 21, FS = 22, GS = 23
} RegisterID;
// 栈帧信息
typedef struct StackFrame {
uint64_t rip; // 指令指针
uint64_t rsp; // 栈指针
uint64_t rbp; // 帧指针
uint64_t* rbp_chain; // RBP 链
uint64_t return_addr; // 返回地址
const char* symbol_name;
const char* file_name;
int line_number;
struct StackFrame* next;
} StackFrame;
// 进程内存读取函数类型
typedef bool (*ReadMemoryFunc)(uint64_t addr, void* buf, size_t size, void* ctx);
// 栈展开器上下文
typedef struct {
ReadMemoryFunc read_mem;
void* read_ctx;
uint64_t text_base; // 代码段基址
uint64_t stack_base; // 栈基址
uint64_t stack_limit; // 栈边界
bool use_frame_pointer; // 是否使用帧指针
} UnwinderContext;
// 初始化展开器
UnwinderContext* unwinder_init(ReadMemoryFunc read_mem, void* ctx) {
UnwinderContext* unwinder = (UnwinderContext*)calloc(1, sizeof(UnwinderContext));
if (!unwinder) return NULL;
unwinder->read_mem = read_mem;
unwinder->read_ctx = ctx;
unwinder->use_frame_pointer = true;
return unwinder;
}
// 从内存读取 64 位值
static uint64_t read_uint64(UnwinderContext* ctx, uint64_t addr) {
uint64_t value = 0;
if (ctx && ctx->read_mem) {
ctx->read_mem(addr, &value, sizeof(value), ctx->read_ctx);
}
return value;
}
// 验证地址是否在有效范围内
static bool is_valid_address(UnwinderContext* ctx, uint64_t addr) {
if (!ctx) return false;
if (addr >= 0xFFFFFFFF80000000ULL) return false;
if (ctx->stack_limit > 0) {
return addr >= ctx->stack_limit && addr < ctx->stack_base;
}
return addr != 0;
}
// 使用帧指针链展开栈
StackFrame* unwind_with_frame_pointer(UnwinderContext* ctx,
uint64_t initial_rbp,
uint64_t initial_rsp,
int max_depth) {
if (!ctx || max_depth <= 0) return NULL;
StackFrame* head = NULL;
StackFrame* current = NULL;
uint64_t rbp = initial_rbp;
uint64_t rsp = initial_rsp;
int depth = 0;
while (depth < max_depth) {
StackFrame* frame = (StackFrame*)calloc(1, sizeof(StackFrame));
if (!frame) break;
frame->rbp = rbp;
frame->rsp = rsp;
frame->return_addr = read_uint64(ctx, rbp + 8);
frame->rip = frame->return_addr - 1;
uint64_t caller_rbp = read_uint64(ctx, rbp);
if (!is_valid_address(ctx, caller_rbp) || caller_rbp <= rbp) {
frame->next = NULL;
if (!head) head = frame;
else current->next = frame;
current = frame;
break;
}
rsp = rbp + 16;
rbp = caller_rbp;
if (!head) {
head = frame;
} else {
current->next = frame;
}
current = frame;
depth++;
}
return head;
}
// 启发式栈展开
StackFrame* unwind_with_heuristics(UnwinderContext* ctx,
uint64_t initial_rip,
uint64_t initial_rsp,
uint64_t initial_rbp,
int max_depth) {
if (!ctx || max_depth <= 0) return NULL;
uint64_t scan_addr = initial_rsp;
int depth = 0;
StackFrame* head = NULL;
StackFrame* current = NULL;
StackFrame* first_frame = (StackFrame*)calloc(1, sizeof(StackFrame));
if (!first_frame) return NULL;
first_frame->rip = initial_rip;
first_frame->rsp = initial_rsp;
first_frame->rbp = initial_rbp;
first_frame->return_addr = 0;
head = first_frame;
current = first_frame;
while (depth < max_depth && scan_addr < initial_rbp + 0x1000) {
uint64_t candidate = read_uint64(ctx, scan_addr);
if (candidate >= ctx->text_base &&
candidate < ctx->text_base + 0x10000000) {
StackFrame* frame = (StackFrame*)calloc(1, sizeof(StackFrame));
if (!frame) break;
frame->rip = candidate - 1;
frame->rsp = scan_addr + 8;
frame->return_addr = candidate;
frame->rbp = 0;
current->next = frame;
current = frame;
depth++;
}
scan_addr += 8;
}
return head;
}
// 主展开函数
StackFrame* unwind_stack(UnwinderContext* ctx,
uint64_t rip, uint64_t rsp,
uint64_t rbp, int max_depth) {
if (!ctx) return NULL;
if (ctx->use_frame_pointer && rbp != 0) {
return unwind_with_frame_pointer(ctx, rbp, rsp, max_depth);
} else {
return unwind_with_heuristics(ctx, rip, rsp, rbp, max_depth);
}
}
// 释放栈帧链表
void stack_frame_free(StackFrame* frame) {
while (frame) {
StackFrame* next = frame->next;
free(frame);
frame = next;
}
}
#endif // __x86_64__4.2.2 ARM64 架构栈展开
ARM64 架构的栈布局与 x86_64 不同,使用 X29 作为帧指针,X30 作为链接寄存器(保存返回地址)。
/**
* ARM64 (AArch64) 架构栈展开实现
*/
#ifdef __aarch64__
// ARM64 寄存器定义
typedef enum {
X0 = 0, X1 = 1, X2 = 2, X3 = 3,
X4 = 4, X5 = 5, X6 = 6, X7 = 7,
X8 = 8, X9 = 9, X10 = 10, X11 = 11,
X12 = 12, X13 = 13, X14 = 14, X15 = 15,
X16 = 16, X17 = 17, X18 = 18, X19 = 19,
X20 = 20, X21 = 21, X22 = 22, X23 = 23,
X24 = 24, X25 = 25, X26 = 26, X27 = 27,
X28 = 28, X29 = 29, X30 = 30, SP = 31,
PC = 32
} RegisterID;
// ARM64 栈帧
typedef struct StackFrameARM {
uint64_t pc; // 程序计数器
uint64_t sp; // 栈指针
uint64_t fp; // 帧指针 (X29)
uint64_t lr; // 链接寄存器 (X30)
uint64_t* fp_chain; // FP 链
const char* symbol_name;
const char* file_name;
int line_number;
struct StackFrameARM* next;
} StackFrameARM;
// 读取 64 位值(ARM64 版本)
static uint64_t read_uint64_arm(UnwinderContext* ctx, uint64_t addr) {
uint64_t value = 0;
if (ctx && ctx->read_mem) {
ctx->read_mem(addr, &value, sizeof(value), ctx->read_ctx);
}
return value;
}
// ARM64 栈展开
StackFrameARM* unwind_stack_arm(UnwinderContext* ctx,
uint64_t initial_pc,
uint64_t initial_sp,
uint64_t initial_fp,
uint64_t initial_lr,
int max_depth) {
if (!ctx || max_depth <= 0) return NULL;
StackFrameARM* head = NULL;
StackFrameARM* current = NULL;
uint64_t fp = initial_fp;
int depth = 0;
while (depth < max_depth) {
StackFrameARM* frame = (StackFrameARM*)calloc(1, sizeof(StackFrameARM));
if (!frame) break;
frame->fp = fp;
frame->lr = read_uint64_arm(ctx, fp + 8);
frame->pc = frame->lr - 4;
frame->sp = fp;
uint64_t caller_fp = read_uint64_arm(ctx, fp);
if (!is_valid_address(ctx, caller_fp) || caller_fp <= fp) {
frame->next = NULL;
if (!head) head = frame;
else current->next = frame;
break;
}
fp = caller_fp;
if (!head) head = frame;
else current->next = frame;
current = frame;
depth++;
}
return head;
}
#endif // __aarch64__4.3 符号解析
符号解析是将内存地址转换为函数名、文件名、行号等信息的过程。这依赖于编译器生成的调试信息(如 DWARF)。
4.3.1 DWARF 调试信息解析
DWARF(Debugging With Attributed Record Formats)是一种广泛使用的调试信息格式。
"""
DWARF 符号解析器
使用 pyelftools 解析 DWARF 信息,实现地址到符号的转换
"""
from elftools.elf.elffile import ELFFile
from elftools.common.exceptions import ELFParseError
import struct
class DwarfSymbolResolver:
"""DWARF 符号解析器"""
def __init__(self, elf_path: str):
self.elf_path = elf_path
self.elf = None
self.dwarfinfo = None
self._cu_by_offset = {}
def open(self):
"""打开 ELF 文件并初始化 DWARF 信息"""
with open(self.elf_path, 'rb') as f:
self.elf = ELFFile(f)
if not self.elf.has_dwarf_info():
raise ValueError(f"No DWARF info in {self.elf_path}")
self.dwarfinfo = self.elf.get_dwarf_info()
return self
def find_compile_unit(self, addr: int):
"""查找包含指定地址的编译单元"""
if addr in self._cu_by_offset:
return self._cu_by_offset[addr]
for cu in self.dwarfinfo.iter_CUs():
cu_header = self.dwarfinfo._get_cu_header(cu)
if hasattr(cu_header, 'dw_at_low_pc') and hasattr(cu_header, 'dw_at_high_pc'):
low_pc = cu_header.dw_at_low_pc
high_pc = low_pc + cu_header.dw_at_high_pc
if low_pc <= addr < high_pc:
self._cu_by_offset[addr] = cu
return cu
return None
def resolve_address(self, addr: int) -> dict:
"""将内存地址解析为符号信息"""
result = {
'addr': hex(addr),
'symbol_name': None,
'file_name': None,
'line_number': None,
'column': None,
'cu_name': None,
'inlined': False,
'inline_chain': []
}
line_info = self._get_line_info(addr)
if line_info:
result['file_name'] = line_info.filename
result['line_number'] = line_info.line
result['column'] = line_info.column
func_info = self._get_function_info(addr)
if func_info:
result['symbol_name'] = func_info.name
result['cu_name'] = func_info.comp_unit_name
inlined_funcs = self._get_inlined_functions(addr)
if inlined_funcs:
result['inlined'] = True
result['inline_chain'] = inlined_funcs
return result
def _get_line_info(self, addr: int):
"""使用 DWARF 行表信息获取指定地址的行号"""
try:
for cu in self.dwarfinfo.iter_CUs():
line_header = self.dwarfinfo.get_line_header_for_cu(cu)
if not line_header:
continue
decoded_line = None
for entry in line_header.get_entries():
if entry.state is None:
continue
if entry.state.end_sequence:
continue
if hasattr(entry.state, 'address') and entry.state.address:
if entry.state.address == addr:
decoded_line = entry.state
break
elif entry.state.address > addr:
break
if decoded_line:
class LineInfo:
def __init__(self, state, header):
self.filename = header.get_filename()
self.line = state.line
self.column = state.column
return LineInfo(decoded_line, line_header)
except Exception as e:
print(f"Error getting line info: {e}")
return None
def _get_function_info(self, addr: int):
"""查找包含指定地址的函数"""
for cu in self.dwarfinfo.iter_CUs():
try:
for die in cu.iter_DIEs():
if die.tag == 'DW_TAG_subprogram':
if self._die_contains_addr(die, addr):
name = die.get_full_path()
cu_name = None
for cu_die in cu.iter_DIEs():
if cu_die.tag == 'DW_TAG_compile_unit':
if 'DW_AT_name' in cu_die.attributes:
cu_name = cu_die.attributes['DW_AT_name'].value
break
class FuncInfo:
def __init__(self, name, cu_name):
self.name = name
self.comp_unit_name = cu_name
return FuncInfo(name, cu_name)
except Exception as e:
continue
return None
def _die_contains_addr(self, die, addr: int) -> bool:
"""检查 DIE 的地址范围是否包含指定地址"""
if 'DW_AT_low_pc' not in die.attributes:
return False
low_pc = die.attributes['DW_AT_low_pc'].value
if 'DW_AT_high_pc' in die.attributes:
high_pc_attr = die.attributes['DW_AT_high_pc']
if high_pc_attr.form == 'DW_FORM_addr':
high_pc = high_pc_attr.value
else:
high_pc = low_pc + high_pc_attr.value
elif 'DW_AT_ranges' in die.attributes:
return False
else:
return False
return low_pc <= addr < high_pc
def _get_inlined_functions(self, addr: int):
"""获取指定地址处的内联函数链"""
inlined = []
for cu in self.dwarfinfo.iter_CUs():
try:
for die in cu.iter_DIEs():
if die.tag == 'DW_TAG_inlined_subroutine':
if self._die_contains_addr(die, addr):
name = None
if 'DW_AT_name' in die.attributes:
name = die.attributes['DW_AT_name'].value
elif 'DW_AT_abstract_origin' in die.attributes:
name = "<abstract>"
if name:
inlined.append(name)
except Exception:
continue
return inlined
def get_all_functions(self) -> list:
"""获取所有函数符号"""
functions = []
for cu in self.dwarfinfo.iter_CUs():
for die in cu.iter_DIEs():
if die.tag == 'DW_TAG_subprogram':
if 'DW_AT_low_pc' in die.attributes:
low_pc = die.attributes['DW_AT_low_pc'].value
name = die.get_full_path() if hasattr(die, 'get_full_path') else str(die)
functions.append({
'name': name,
'low_pc': hex(low_pc) if isinstance(low_pc, int) else low_pc,
'cu': str(cu)
})
return functions
if __name__ == '__main__':
resolver = DwarfSymbolResolver('/path/to/binary')
try:
resolver.open()
info = resolver.resolve_address(0x401000)
print(f"Address: {info['addr']}")
print(f"Function: {info['symbol_name']}")
print(f"File: {info['file_name']}")
print(f"Line: {info['line_number']}")
funcs = resolver.get_all_functions()
print(f"\nTotal functions: {len(funcs)}")
for f in funcs[:10]:
print(f" {f['low_pc']}: {f['name']}")
except ELFParseError as e:
print(f"Failed to parse ELF: {e}")4.4 调用栈可视化
Debug Agent 需要将调用栈以可读的方式呈现给开发者,并支持交互式探索。
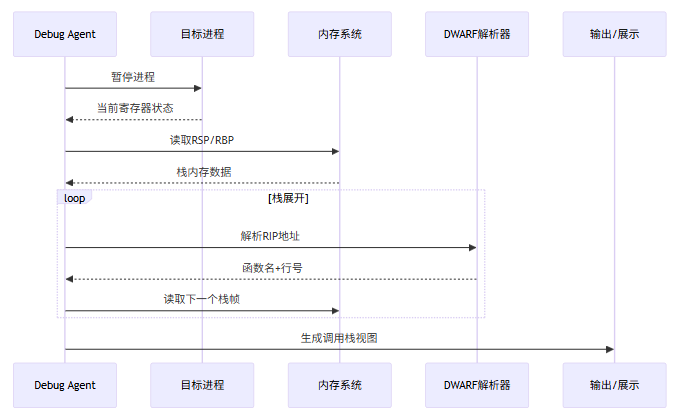
5. 根因分析:基于模式的错误分类
本节为你提供的核心技术价值:掌握错误模式识别、异常分类、根因推导的核心算法,使 Debug Agent 能够从复杂的调试信息中提取问题的本质原因。
5.1 错误模式分类体系
Debug Agent 的根因分析引擎需要识别和分类各种错误模式。以下是一个多层次的分类体系:
层次 | 类别 | 典型模式 | 诊断难度 |
|---|---|---|---|
内存层 | 内存泄漏 | 堆内存持续增长 | 中 |
栈溢出 | 局部变量过大 | 低 | |
野指针 | 访问已释放内存 | 高 | |
缓冲区溢出 | 写入超出边界 | 中 | |
并发层 | 死锁 | 循环等待资源 | 中 |
竞态条件 | 非原子操作 | 高 | |
资源竞争 | 共享资源冲突 | 高 | |
逻辑层 | 空指针 | 调用空对象方法 | 低 |
数组越界 | 索引超出范围 | 低 | |
类型错误 | 类型不匹配 | 中 | |
I/O层 | 文件未找到 | 路径错误/权限问题 | 低 |
连接超时 | 网络问题 | 中 | |
权限拒绝 | 访问控制 | 低 |
5.2 异常模式识别引擎
"""
异常模式识别引擎
基于规则和机器学习的混合模式识别系统
"""
from dataclasses import dataclass, field
from typing import List, Dict, Optional, Tuple, Any
from enum import Enum
import re
class ErrorCategory(Enum):
"""错误分类"""
MEMORY_LEAK = "memory_leak"
MEMORY_CORRUPTION = "memory_corruption"
NULL_POINTER = "null_pointer"
BUFFER_OVERFLOW = "buffer_overflow"
STACK_OVERFLOW = "stack_overflow"
DEADLOCK = "deadlock"
RACE_CONDITION = "race_condition"
TIMEOUT = "timeout"
FILE_ERROR = "file_error"
NETWORK_ERROR = "network_error"
TYPE_ERROR = "type_error"
ASSERTION_FAILURE = "assertion_failure"
UNKNOWN = "unknown"
class Severity(Enum):
"""严重级别"""
CRITICAL = 1
HIGH = 2
MEDIUM = 3
LOW = 4
INFO = 5
@dataclass
class ErrorSignature:
"""错误特征签名"""
category: ErrorCategory
severity: Severity
patterns: List[str]
keywords: List[str]
stack_patterns: List[str]
solution_hints: List[str]
@dataclass
class MatchedPattern:
"""匹配到的模式"""
pattern: str
matched_text: str
confidence: float
location: str
@dataclass
class RootCauseResult:
"""根因分析结果"""
category: ErrorCategory
severity: Severity
confidence: float
matched_patterns: List[MatchedPattern]
root_cause_description: str
solution_hints: List[str]
related_variables: List[str]
evidence: Dict[str, Any]
class PatternRegistry:
"""模式注册表"""
def __init__(self):
self.signatures: Dict[ErrorCategory, ErrorSignature] = {}
self._init_default_patterns()
def _init_default_patterns(self):
"""初始化默认模式"""
self.signatures[ErrorCategory.NULL_POINTER] = ErrorSignature(
category=ErrorCategory.NULL_POINTER,
severity=Severity.HIGH,
patterns=[
r"NullPointerException",
r"attempt to read from null object",
r"dereferencing null",
r"dereference\([^)]*null",
r"NULL pointer",
r"nullptr",
r"CXX0030: Error: expression cannot be evaluated"
],
keywords=["null", "nil", "None", "nullptr", "NULL"],
stack_patterns=[
r"at .*\(.*\.java:\d+\)",
r"#\d+\s+0x[0-9a-f]+\s+in\s+(\w+)",
],
solution_hints=[
"添加 null 检查",
"使用 Optional 类型",
"确保对象初始化"
]
)
self.signatures[ErrorCategory.MEMORY_LEAK] = ErrorSignature(
category=ErrorCategory.MEMORY_LEAK,
severity=Severity.MEDIUM,
patterns=[
r"memory leak",
r"leaked ",
r"AddressSanitizer: allocation-size",
r"heap-use-after-free",
r"possible memory leak"
],
keywords=["malloc", "free", "new", "delete", "alloc", "heap"],
stack_patterns=[
r"operator new",
r"malloc",
r"std::allocate",
],
solution_hints=[
"检查内存分配/释放配对",
"使用智能指针",
"检查循环引用"
]
)
self.signatures[ErrorCategory.BUFFER_OVERFLOW] = ErrorSignature(
category=ErrorCategory.BUFFER_OVERFLOW,
severity=Severity.CRITICAL,
patterns=[
r"buffer overflow",
r"stack overflow",
r"heap overflow",
r"overflow detected",
r"AddressSanitizer: stack-buffer-overflow",
r"AddressSanitizer: heap-buffer-overflow",
r"index out of bounds",
r"array index out of range"
],
keywords=["buffer", "array", "index", "offset", "size"],
stack_patterns=[
r"memcpy",
r"strcpy",
r"sprintf",
],
solution_hints=[
"检查数组边界",
"使用安全的字符串函数",
"添加边界检查"
]
)
self.signatures[ErrorCategory.DEADLOCK] = ErrorSignature(
category=ErrorCategory.DEADLOCK,
severity=Severity.HIGH,
patterns=[
r"deadlock",
r"dead lock",
r"all threads blocked",
r"waiting for lock",
r"mutex.*lock.*dead",
],
keywords=["mutex", "lock", "wait", "notify", "synchronized"],
stack_patterns=[
r"pthread_mutex_lock",
r"Monitor\.enter",
r"std::mutex::lock",
],
solution_hints=[
"检查锁顺序",
"使用超时锁",
"避免嵌套锁"
]
)
self.signatures[ErrorCategory.FILE_ERROR] = ErrorSignature(
category=ErrorCategory.FILE_ERROR,
severity=Severity.MEDIUM,
patterns=[
r"No such file or directory",
r"FileNotFoundException",
r"cannot open file",
r"Permission denied",
r"ENOENT",
r"EACCES",
],
keywords=["file", "open", "read", "write", "path"],
stack_patterns=[
r"fopen",
r"open\(",
],
solution_hints=[
"检查文件路径",
"检查文件权限",
]
)
class RootCauseAnalyzer:
"""根因分析器"""
def __init__(self, registry: Optional[PatternRegistry] = None):
self.registry = registry or PatternRegistry()
self.analysis_history: List[RootCauseResult] = []
def analyze_exception_info(self,
exception_type: str,
exception_message: str,
stack_trace: str,
context: Optional[Dict[str, Any]] = None) -> RootCauseResult:
"""分析异常信息,输出根因分析结果"""
full_text = f"{exception_type}\n{exception_message}\n{stack_trace}"
category_scores: Dict[ErrorCategory, Tuple[float, List[MatchedPattern]]] = {}
for category, signature in self.registry.signatures.items():
total_score = 0.0
matched: List[MatchedPattern] = []
for pattern in signature.patterns:
matches = list(re.finditer(pattern, full_text, re.IGNORECASE))
if matches:
for match in matches:
confidence = self._calculate_confidence(pattern, match.group(),
signature, full_text)
matched.append(MatchedPattern(
pattern=pattern,
matched_text=match.group(),
confidence=confidence,
location=f"pos {match.start()}"
))
total_score += confidence
for stack_pattern in signature.stack_patterns:
matches = list(re.finditer(stack_pattern, stack_trace, re.IGNORECASE))
if matches:
total_score += 0.2 * len(matches)
if matched:
category_scores[category] = (total_score, matched)
if not category_scores:
return self._create_unknown_result(full_text)
best_category = max(category_scores.items(),
key=lambda x: x[1][0])
category, (score, matched_patterns) = best_category
signature = self.registry.signatures[category]
max_possible_score = len(signature.patterns) * 1.0 + len(signature.stack_patterns) * 0.2
confidence = min(score / max_possible_score if max_possible_score > 0 else 0, 1.0)
related_vars = self._extract_related_variables(full_text, signature.keywords)
description = self._generate_description(category, matched_patterns, related_vars)
result = RootCauseResult(
category=category,
severity=signature.severity,
confidence=confidence,
matched_patterns=matched_patterns,
root_cause_description=description,
solution_hints=signature.solution_hints,
related_variables=related_vars,
evidence={
'exception_type': exception_type,
'exception_message': exception_message,
'score': score
}
)
self.analysis_history.append(result)
return result
def _calculate_confidence(self, pattern: str, matched_text: str,
signature: ErrorSignature,
full_text: str) -> float:
"""计算匹配置信度"""
base_confidence = 0.5
if pattern.lower() in matched_text.lower():
base_confidence = 0.8
matched_lower = matched_text.lower()
keyword_count = sum(1 for kw in signature.keywords
if kw.lower() in matched_lower)
keyword_density = keyword_count / len(signature.keywords) if signature.keywords else 0
base_confidence += keyword_density * 0.2
return min(base_confidence, 1.0)
def _extract_related_variables(self, text: str, keywords: List[str]) -> List[str]:
"""提取相关变量名"""
variables = set()
var_patterns = [
r'\b([a-zA-Z_][a-zA-Z0-9_]*)\s*=\s*',
r'\b([a-zA-Z_][a-zA-Z0-9_]*)\s*\[',
r'\b([a-zA-Z_][a-zA-Z0-9_]*)\.\w+\(',
]
for kw in keywords:
for pat in var_patterns:
for match in re.finditer(pat, text):
var_name = match.group(1)
if len(var_name) > 2:
variables.add(var_name)
return list(variables)[:10]
def _generate_description(self, category: ErrorCategory,
matched_patterns: List[MatchedPattern],
related_vars: List[str]) -> str:
"""生成根因描述"""
descriptions = {
ErrorCategory.NULL_POINTER: f"检测到空指针访问,变量 {related_vars[:3] if related_vars else '未知'} 可能为 null",
ErrorCategory.MEMORY_LEAK: f"检测到内存泄漏,可能涉及 {related_vars[:3] if related_vars else '未知'} 的分配/释放问题",
ErrorCategory.BUFFER_OVERFLOW: f"检测到缓冲区溢出,写入超出分配边界",
ErrorCategory.DEADLOCK: f"检测到死锁,多个线程等待对方释放锁",
ErrorCategory.FILE_ERROR: f"检测到文件操作错误",
}
desc = descriptions.get(category, "检测到未知错误")
if matched_patterns:
top_pattern = matched_patterns[0].matched_text
if len(top_pattern) < 100:
desc += f"\n\n关键特征: {top_pattern}"
return desc
def _create_unknown_result(self, text: str) -> RootCauseResult:
"""创建未知错误结果"""
return RootCauseResult(
category=ErrorCategory.UNKNOWN,
severity=Severity.MEDIUM,
confidence=0.0,
matched_patterns=[],
root_cause_description="无法识别错误类型,请手动分析",
solution_hints=["查看完整的错误信息", "检查相关日志"],
related_variables=[],
evidence={'raw_text': text[:1000]}
)
def get_statistics(self) -> Dict[str, Any]:
"""获取分析统计信息"""
if not self.analysis_history:
return {'total': 0}
stats = {
'total': len(self.analysis_history),
'by_category': {},
'by_severity': {},
'avg_confidence': 0.0
}
total_confidence = 0.0
for result in self.analysis_history:
cat_name = result.category.value
stats['by_category'][cat_name] = stats['by_category'].get(cat_name, 0) + 1
sev_name = result.severity.name
stats['by_severity'][sev_name] = stats['by_severity'].get(sev_name, 0) + 1
total_confidence += result.confidence
stats['avg_confidence'] = total_confidence / len(self.analysis_history)
return stats
if __name__ == '__main__':
analyzer = RootCauseAnalyzer()
test_cases = [
{
'type': 'NullPointerException',
'message': 'Attempt to read from null object reference',
'stack': '''
at com.example.App.processData(App.java:42)
at com.example.App.handleRequest(App.java:28)
at com.example.App.main(App.java:15)
'''
},
{
'type': 'SIGSEGV',
'message': 'Segmentation fault',
'stack': '''
#0 0x00007fff5a3c4d42 in __strlen_avx2 ()
#1 0x00005555555551a3 in process_string at src/processor.c:128
#2 0x0000555555555267 in main at src/main.c:45
'''
}
]
for tc in test_cases:
result = analyzer.analyze_exception_info(
tc['type'],
tc['message'],
tc['stack']
)
print(f"\n{'='*60}")
print(f"Exception Type: {tc['type']}")
print(f"Category: {result.category.value}")
print(f"Severity: {result.severity.name}")
print(f"Confidence: {result.confidence:.2f}")
print(f"Description: {result.root_cause_description}")
print(f"Solution Hints: {result.solution_hints}")5.3 调用栈级别的根因分析
"""
调用栈根因分析器
通过分析调用栈的结构和特征来推断错误原因
"""
from typing import List, Dict, Tuple, Optional
from dataclasses import dataclass
import re
@dataclass
class StackFrame:
"""调用栈帧"""
address: str
function_name: str
file_name: Optional[str]
line_number: Optional[int]
module: Optional[str]
def __str__(self):
location = f"{self.file_name}:{self.line_number}" if self.file_name and self.line_number else self.address
return f"{self.function_name} ({location})"
@dataclass
class StackAnalysisResult:
"""栈分析结果"""
is_corrupted: bool
corruption_reason: Optional[str]
suspicious_frames: List[Tuple[StackFrame, str]]
call_pattern: str
entry_point: Optional[str]
error_probability: float
class StackAnalyzer:
"""调用栈分析器"""
CORRUPTION_PATTERNS = {
'buffer_overflow': [
r'strcpy', r'strcat', r'sprintf', r'gets',
r'memcpy', r'memmove', r'memset'
],
'heap_corruption': [
r'operator delete', r'free', r'realloc',
r'malloc', r'operator new', r'alloc'
],
}
def __init__(self):
self.max_stack_depth = 100
self.max_recursion_depth = 10
def parse_stack_trace(self, raw_trace: str, format: str = 'auto') -> List[StackFrame]:
"""解析原始栈追踪文本"""
frames = []
if format == 'auto':
format = self._detect_format(raw_trace)
if format == 'gdb':
frames = self._parse_gdb_stack(raw_trace)
elif format == 'java':
frames = self._parse_java_stack(raw_trace)
elif format == 'android':
frames = self._parse_android_stack(raw_trace)
return frames
def _detect_format(self, raw_trace: str) -> str:
"""检测栈追踪格式"""
lines = raw_trace.strip().split('\n')
first_line = lines[0] if lines else ''
if '#0' in first_line and '0x' in first_line:
return 'gdb'
elif 'at ' in first_line and '.java:' in first_line:
return 'java'
elif 'android.' in raw_trace or 'libutils.so' in raw_trace:
return 'android'
return 'gdb'
def _parse_gdb_stack(self, raw_trace: str) -> List[StackFrame]:
"""解析 GDB 格式的栈追踪"""
frames = []
pattern = r'#(\d+)\s+(0x[0-9a-f]+)\s+in\s+(\S+)\s*(.*?)\s+at\s+(\S+):(\d+)'
simple_pattern = r'#(\d+)\s+(0x[0-9a-f]+)\s+in\s+(\S+)'
for line in raw_trace.split('\n'):
match = re.search(pattern, line)
if match:
frame = StackFrame(
address=match.group(2),
function_name=match.group(3),
file_name=match.group(5),
line_number=int(match.group(6)),
module=None
)
frames.append(frame)
else:
match = re.search(simple_pattern, line)
if match:
frame = StackFrame(
address=match.group(2),
function_name=match.group(3),
file_name=None,
line_number=None,
module=None
)
frames.append(frame)
return frames
def _parse_java_stack(self, raw_trace: str) -> List[StackFrame]:
"""解析 Java 格式的栈追踪"""
frames = []
pattern = r'at\s+([\w.$]+)\.([\w$]+)\s*\(([\w.]+):(\d+)\)'
for line in raw_trace.split('\n'):
match = re.search(pattern, line)
if match:
class_name = match.group(1)
method_name = match.group(2)
file_name = match.group(3)
line_number = int(match.group(4))
frame = StackFrame(
address='',
function_name=f"{class_name}.{method_name}",
file_name=file_name,
line_number=line_number,
module=class_name
)
frames.append(frame)
return frames
def _parse_android_stack(self, raw_trace: str) -> List[StackFrame]:
"""解析 Android tombstone 格式"""
frames = []
pattern = r'#(\d+)\s+pc\s+(0x[0-9a-f]+)\s+(\S+)\s*\(([^)]+)\)\s+\[(\S+)\]'
for line in raw_trace.split('\n'):
match = re.search(pattern, line)
if match:
frame = StackFrame(
address=match.group(2),
function_name=match.group(3),
file_name=None,
line_number=None,
module=match.group(5)
)
frames.append(frame)
return frames
def analyze_stack(self, frames: List[StackFrame]) -> StackAnalysisResult:
"""分析调用栈,检测潜在问题"""
suspicious = []
is_corrupted = False
corruption_reason = None
corruption_check = self._check_stack_corruption(frames)
if corruption_check['corrupted']:
is_corrupted = True
corruption_reason = corruption_check['reason']
for i, frame in enumerate(frames):
reason = self._check_frame_suspicion(frame, i, frames)
if reason:
suspicious.append((frame, reason))
call_pattern = self._detect_call_pattern(frames)
entry_point = self._find_entry_point(frames)
error_prob = self._calculate_error_probability(
is_corrupted, corruption_reason, suspicious, call_pattern, len(frames)
)
return StackAnalysisResult(
is_corrupted=is_corrupted,
corruption_reason=corruption_reason,
suspicious_frames=suspicious,
call_pattern=call_pattern,
entry_point=entry_point,
error_probability=error_prob
)
def _check_stack_corruption(self, frames: List[StackFrame]) -> Dict:
"""检查栈是否损坏"""
if len(frames) > self.max_stack_depth:
return {
'corrupted': True,
'reason': f'栈深度超过限制 ({len(frames)} > {self.max_stack_depth})'
}
for frame in frames:
if not frame.function_name or frame.function_name == '??':
return {
'corrupted': True,
'reason': '栈包含未知函数,可能损坏'
}
return {'corrupted': False, 'reason': None}
def _check_frame_suspicion(self, frame: StackFrame, index: int,
all_frames: List[StackFrame]) -> Optional[str]:
"""检查单个帧是否可疑"""
func_name = frame.function_name.lower()
for category, patterns in self.CORRUPTION_PATTERNS.items():
for pattern in patterns:
if re.search(pattern, func_name, re.IGNORECASE):
return f"涉及{category}相关函数: {frame.function_name}"
if index > 0:
for prev_frame in all_frames[:index]:
if prev_frame.function_name == frame.function_name:
return f"可能的递归调用: {frame.function_name}"
return None
def _detect_call_pattern(self, frames: List[StackFrame]) -> str:
"""检测调用模式"""
if len(frames) == 0:
return 'empty'
func_names = [f.function_name for f in frames]
for name in set(func_names):
if func_names.count(name) > self.max_recursion_depth:
return 'recursive'
if len(frames) > 50:
return 'deep'
return 'normal'
def _find_entry_point(self, frames: List[StackFrame]) -> Optional[str]:
"""查找入口点函数"""
entry_patterns = [
r'^main$',
r'^_start$',
r'^thread_start$',
r'^java_main$',
r'^ActivityThread\.main$',
r'^onCreate$',
]
for frame in reversed(frames):
for pattern in entry_patterns:
if re.search(pattern, frame.function_name):
return frame.function_name
return frames[-1].function_name if frames else None
def _calculate_error_probability(self,
is_corrupted: bool,
corruption_reason: Optional[str],
suspicious: List,
call_pattern: str,
stack_depth: int) -> float:
"""计算错误概率"""
prob = 0.0
if is_corrupted:
prob += 0.5
if suspicious:
prob += 0.1 * len(suspicious)
if call_pattern == 'recursive':
prob += 0.2
elif call_pattern == 'deep':
prob += 0.1
if stack_depth > 30:
prob += 0.1
return min(prob, 1.0)
def generate_report(self, result: StackAnalysisResult, frames: List[StackFrame]) -> str:
"""生成分析报告"""
lines = []
lines.append("=" * 60)
lines.append("STACK ANALYSIS REPORT")
lines.append("=" * 60)
lines.append(f"\nOverall Status: {'CORRUPTED' if result.is_corrupted else 'OK'}")
lines.append(f"Error Probability: {result.error_probability:.2%}")
lines.append(f"Call Pattern: {result.call_pattern}")
lines.append(f"Entry Point: {result.entry_point or 'Unknown'}")
if result.corruption_reason:
lines.append(f"\nCORRUPTION DETECTED:")
lines.append(f" {result.corruption_reason}")
if result.suspicious_frames:
lines.append(f"\nSUSPICIOUS FRAMES ({len(result.suspicious_frames)}):")
for frame, reason in result.suspicious_frames[:5]:
lines.append(f" - {frame}")
lines.append(f" Reason: {reason}")
lines.append(f"\nFULL STACK TRACE ({len(frames)} frames):")
lines.append("-" * 60)
for i, frame in enumerate(frames[:20]):
lines.append(f"#{i:2d} {frame}")
if len(frames) > 20:
lines.append(f"... ({len(frames) - 20} more frames)")
lines.append("=" * 60)
return "\n".join(lines)
if __name__ == '__main__':
analyzer = StackAnalyzer()
gdb_trace = '''
#0 0x00007fff5a3c4d42 in __strlen_avx2 ()
#1 0x00005555555551a3 in process_string at src/processor.c:128
#2 0x0000555555555267 in main at src/main.c:45
#3 0x00007fff7a3c2d31 in __libc_start_main ()
#4 0x0000555555555045 in _start ()
'''
frames = analyzer.parse_stack_trace(gdb_trace, 'gdb')
result = analyzer.analyze_stack(frames)
report = analyzer.generate_report(result, frames)
print(report)6. 修复建议:代码补丁生成与验证
本节为你提供的核心技术价值:掌握基于 AI 的代码修复建议生成、补丁验证、以及自动修复的安全机制,使 Debug Agent 能够提供可行的修复方案。
6.1 修复建议生成原理
Debug Agent 的修复建议系统基于以下原理工作:
- 模式匹配:识别错误模式,匹配已知解决方案
- 代码上下文分析:理解代码逻辑,生成上下文相关的修复
- 安全约束:确保修复不会引入新的问题
- 可验证性:提供的修复必须可以通过测试验证
6.2 修复建议生成器实现
"""
代码修复建议生成器
基于错误类型和代码上下文生成修复方案
"""
from dataclasses import dataclass, field
from typing import List, Dict, Optional, Tuple, Any
from enum import Enum
import re
class FixType(Enum):
"""修复类型"""
NULL_CHECK = "null_check"
BOUNDS_CHECK = "bounds_check"
MEMORY_MANAGEMENT = "memory_management"
LOCK_ORDER = "lock_order"
TIMEOUT_ADJUST = "timeout_adjust"
ERROR_HANDLING = "error_handling"
TYPE_CAST = "type_cast"
INITIALIZATION = "initialization"
CUSTOM = "custom"
class FixConfidence(Enum):
"""修复置信度"""
HIGH = "high"
MEDIUM = "medium"
LOW = "low"
@dataclass
class CodeFix:
"""代码修复"""
fix_type: FixType
confidence: FixConfidence
original_code: str
fixed_code: str
explanation: str
file_path: str
line_number: int
safety_notes: List[str] = field(default_factory=list)
test_suggestions: List[str] = field(default_factory=list)
side_effects: List[str] = field(default_factory=list)
@dataclass
class FixTemplate:
"""修复模板"""
error_pattern: str
error_category: str
fix_type: FixType
template: str
conditions: List[str] = field(default_factory=list)
class FixSuggestionEngine:
"""修复建议引擎"""
def __init__(self):
self.templates: List[FixTemplate] = []
self._init_templates()
def _init_templates(self):
"""初始化修复模板库"""
self.templates.append(FixTemplate(
error_pattern=r"NullPointerException|attempt to read from null",
error_category="null_pointer",
fix_type=FixType.NULL_CHECK,
template='''\
// 添加空值检查
if ({variable} == null) {{
// TODO: Handle null case appropriately
throw new IllegalArgumentException("{variable} cannot be null");
}}
// 原有代码
{original_line}''',
conditions=['variable != None']
))
self.templates.append(FixTemplate(
error_pattern=r"ArrayIndexOutOfBounds|index out of range",
error_category="buffer_overflow",
fix_type=FixType.BOUNDS_CHECK,
template='''\
// 添加边界检查
int index = {index_expr};
if (index < 0 || index >= {array}.length) {{
throw new IndexOutOfBoundsException("Index: " + index + ", Length: " + {array}.length);
}}
// 原有代码
{original_line}''',
conditions=['needs_bounds_check']
))
self.templates.append(FixTemplate(
error_pattern=r"memory leak|leaked|use after free",
error_category="memory_leak",
fix_type=FixType.MEMORY_MANAGEMENT,
template='''\
// 建议使用智能指针管理内存
// 将 raw pointer: {pointer_type}*
// 替换为: std::unique_ptr<{pointer_type}> 或 std::shared_ptr<{pointer_type}>
{original_code}''',
conditions=['is_cpp', 'is_raw_pointer']
))
def generate_fix(self,
error_info: Dict[str, Any],
source_code: str,
file_path: str,
line_number: int) -> Optional[CodeFix]:
"""生成代码修复"""
error_type = error_info.get('type', '')
error_message = error_info.get('message', '')
related_vars = error_info.get('related_variables', [])
matched_template = None
for template in self.templates:
if re.search(template.error_pattern, f"{error_type} {error_message}",
re.IGNORECASE):
matched_template = template
break
if not matched_template:
return None
lines = source_code.split('\n')
if line_number <= 0 or line_number > len(lines):
return None
original_line = lines[line_number - 1].strip()
if matched_template.fix_type == FixType.NULL_CHECK:
return self._generate_null_check_fix(
matched_template, original_line,
related_vars, file_path, line_number
)
elif matched_template.fix_type == FixType.BOUNDS_CHECK:
return self._generate_bounds_check_fix(
matched_template, original_line,
related_vars, error_info, file_path, line_number
)
elif matched_template.fix_type == FixType.MEMORY_MANAGEMENT:
return self._generate_memory_fix(
matched_template, original_line,
related_vars, file_path, line_number
)
return None
def _generate_null_check_fix(self, template: FixTemplate,
original_line: str,
related_vars: List[str],
file_path: str,
line_number: int) -> CodeFix:
"""生成空指针检查修复"""
variable = related_vars[0] if related_vars else 'obj'
fixed_code = f'''if ({variable} == null) {{
throw new IllegalArgumentException("{variable} cannot be null");
}}
{original_line}'''
return CodeFix(
fix_type=FixType.NULL_CHECK,
confidence=FixConfidence.HIGH,
original_code=original_line,
fixed_code=fixed_code,
explanation=f"为变量 '{variable}' 添加了空值检查。空指针异常通常由于未检查返回值或参数是否为 null 导致。",
file_path=file_path,
line_number=line_number,
safety_notes=[
"此修复会在空值时抛出异常",
"如需更温和的处理,可以返回默认值或 Optional"
],
test_suggestions=[
f"测试 {variable} 为 null 的情况",
"测试正常非 null 的情况"
],
side_effects=[
"可能改变原有异常类型"
]
)
def _generate_bounds_check_fix(self, template: FixTemplate,
original_line: str,
related_vars: List[str],
error_info: Dict[str, Any],
file_path: str,
line_number: int) -> CodeFix:
"""生成边界检查修复"""
array_access_match = re.search(r'(\w+)\s*\[([^\]]+)\]', original_line)
if array_access_match:
array_name = array_access_match.group(1)
index_expr = array_access_match.group(2)
else:
array_name = related_vars[0] if related_vars else 'array'
index_expr = 'index'
fixed_code = f'''int index = {index_expr};
if (index < 0 || index >= {array_name}.length) {{
throw new IndexOutOfBoundsException("Index: " + index + ", Length: " + {array_name}.length);
}}
{original_line}'''
return CodeFix(
fix_type=FixType.BOUNDS_CHECK,
confidence=FixConfidence.HIGH,
original_code=original_line,
fixed_code=fixed_code,
explanation=f"为数组 '{array_name}' 的索引访问添加了边界检查。数组越界访问是常见的崩溃原因。",
file_path=file_path,
line_number=line_number,
safety_notes=[
"此修复会在越界时抛出异常",
"边界检查会引入少量性能开销(通常可忽略)"
],
test_suggestions=[
f"测试 index = -1 的情况",
f"测试 index = {array_name}.length 的情况",
]
)
def _generate_memory_fix(self, template: FixTemplate,
original_line: str,
related_vars: List[str],
file_path: str,
line_number: int) -> CodeFix:
"""生成内存管理修复"""
return CodeFix(
fix_type=FixType.MEMORY_MANAGEMENT,
confidence=FixConfidence.MEDIUM,
original_code=original_line,
fixed_code=f"// 建议使用智能指针替代裸指针\n{original_line}",
explanation="建议使用智能指针(std::unique_ptr 或 std::shared_ptr)管理动态内存,避免内存泄漏和野指针问题。",
file_path=file_path,
line_number=line_number,
safety_notes=[
"智能指针会自动管理内存释放",
"需要编译器支持 C++11 或更高版本"
],
test_suggestions=[
"运行 AddressSanitizer 检测内存问题",
],
side_effects=[
"可能需要修改代码的其他部分",
]
)
class PatchGenerator:
"""补丁生成器"""
def __init__(self):
self.fix_engine = FixSuggestionEngine()
def create_patch(self, fix: CodeFix, context_lines: int = 3) -> str:
"""生成统一修补格式 (Unified Diff) 补丁"""
patch_lines = [
f"--- a/{fix.file_path}",
f"+++ b/{fix.file_path}",
f"@@ -{fix.line_number},{context_lines} +{fix.line_number},{context_lines} @@"
]
for line in fix.fixed_code.split('\n'):
patch_lines.append(f"+{line}")
return '\n'.join(patch_lines)
def apply_patch(self, source_code: str, fix: CodeFix) -> str:
"""应用补丁到源代码"""
lines = source_code.split('\n')
new_lines = lines[:fix.line_number - 1]
new_lines.extend(fix.fixed_code.split('\n'))
new_lines.extend(lines[fix.line_number:])
return '\n'.join(new_lines)
def validate_patch(self, source_code: str, fixed_code: str,
fix: CodeFix) -> Tuple[bool, List[str]]:
"""验证补丁的正确性"""
errors = []
if not self._check_syntax(fixed_code, fix.file_path):
errors.append("修复后的代码存在语法错误")
if fix.fixed_code not in fixed_code:
errors.append("修复代码未正确应用到源代码")
return (len(errors) == 0, errors)
def _check_syntax(self, code: str, file_path: str) -> bool:
"""简单语法检查"""
open_braces = code.count('{')
close_braces = code.count('}')
open_parens = code.count('(')
close_parens = code.count(')')
return (open_braces == close_braces) and (open_parens == close_parens)
if __name__ == '__main__':
engine = FixSuggestionEngine()
generator = PatchGenerator()
error_info = {
'type': 'NullPointerException',
'message': 'Attempt to read from null object reference',
'related_variables': ['user', 'config']
}
source_code = '''public void processUser(User user) {
String name = user.getName();
System.out.println("User: " + name);
}'''
fix = engine.generate_fix(
error_info,
source_code,
'src/ProcessUser.java',
2
)
if fix:
print("=" * 60)
print("GENERATED FIX")
print("=" * 60)
print(f"Type: {fix.fix_type.value}")
print(f"Confidence: {fix.confidence.value}")
print(f"\nOriginal Code:")
print(f" {fix.original_code}")
print(f"\nFixed Code:")
print(f" {fix.fixed_code}")
print(f"\nExplanation: {fix.explanation}")
print(f"\nTest Suggestions:")
for test in fix.test_suggestions:
print(f" - {test}")
patch = generator.create_patch(fix)
print(f"\nPatch (Unified Diff):")
print(patch)6.3 自动修复的安全机制
"""
自动修复安全控制器
确保自动修复的安全性和可控性
"""
from dataclasses import dataclass, field
from typing import List, Set, Optional, Dict, Any, Callable
from enum import Enum
class AutoFixLevel(Enum):
"""自动修复级别"""
DISABLED = 0
SUGGEST_ONLY = 1
LOW_RISK_ONLY = 2
MEDIUM_RISK = 3
ALL = 4
class RiskLevel(Enum):
"""风险级别"""
CRITICAL = "critical"
HIGH = "high"
MEDIUM = "medium"
LOW = "low"
NONE = "none"
@dataclass
class SafetyRule:
"""安全规则"""
name: str
description: str
check_func: Callable
risk_level: RiskLevel
block_auto_fix: bool = True
class AutoFixSafetyController:
"""自动修复安全控制器"""
def __init__(self, fix_level: AutoFixLevel = AutoFixLevel.SUGGEST_ONLY):
self.fix_level = fix_level
self.safety_rules: List[SafetyRule] = []
self.approved_fixes: Set[str] = set()
self.denied_fixes: Set[str] = set()
self.fix_history: List[Dict[str, Any]] = []
self._init_safety_rules()
def _init_safety_rules(self):
"""初始化安全规则"""
self.safety_rules.append(SafetyRule(
name="max_lines_changed",
description="禁止单次修改超过指定行数",
check_func=lambda fix: len(fix.fixed_code.split('\n')) <= 10,
risk_level=RiskLevel.MEDIUM
))
self.safety_rules.append(SafetyRule(
name="no_delete_all",
description="禁止删除整个文件或函数体",
check_func=lambda fix: 'delete' not in fix.fixed_code.lower() or
'//' in fix.fixed_code,
risk_level=RiskLevel.CRITICAL
))
self.safety_rules.append(SafetyRule(
name="no_security_changes",
description="禁止修改认证、授权、加密相关代码",
check_func=lambda fix: not any(kw in fix.fixed_code.lower() for kw in [
'password', 'secret', 'token', 'auth', 'encrypt', 'decrypt'
]),
risk_level=RiskLevel.CRITICAL
))
self.safety_rules.append(SafetyRule(
name="no_database_changes",
description="禁止自动修复数据库相关代码",
check_func=lambda fix: 'INSERT' not in fix.fixed_code.upper() and
'UPDATE' not in fix.fixed_code.upper() and
'DELETE' not in fix.fixed_code.upper() and
'DROP' not in fix.fixed_code.upper(),
risk_level=RiskLevel.HIGH
))
def can_auto_fix(self, fix: 'CodeFix') -> tuple:
"""检查是否可以自动修复"""
if self.fix_level == AutoFixLevel.DISABLED:
return (False, "自动修复已禁用", RiskLevel.NONE)
if self.fix_level == AutoFixLevel.SUGGEST_ONLY:
return (False, "当前设置为仅提供建议", RiskLevel.NONE)
fix_id = self._get_fix_id(fix)
if fix_id in self.denied_fixes:
return (False, "此修复已被手动拒绝", RiskLevel.NONE)
if fix_id in self.approved_fixes:
return (True, "此修复已被手动批准", RiskLevel.LOW)
for rule in self.safety_rules:
if not rule.check_func(fix):
if rule.block_auto_fix:
if rule.risk_level == RiskLevel.CRITICAL:
return (False, f"违反安全规则: {rule.description}",
rule.risk_level)
elif self.fix_level < AutoFixLevel.MEDIUM_RISK:
return (False, f"风险较高: {rule.description}",
rule.risk_level)
if len(fix.fixed_code.split('\n')) > 20:
return (False, "修改范围过大,建议手动处理", RiskLevel.MEDIUM)
if self.fix_level == AutoFixLevel.LOW_RISK_ONLY:
return (True, "低风险修复,可以自动应用", RiskLevel.LOW)
return (True, "可以自动修复", RiskLevel.MEDIUM)
def approve_fix(self, fix: 'CodeFix'):
"""手动批准修复"""
fix_id = self._get_fix_id(fix)
self.approved_fixes.add(fix_id)
def deny_fix(self, fix: 'CodeFix'):
"""手动拒绝修复"""
fix_id = self._get_fix_id(fix)
self.denied_fixes.add(fix_id)
def _get_fix_id(self, fix: 'CodeFix') -> str:
"""生成修复的唯一标识"""
return f"{fix.file_path}:{fix.line_number}:{fix.fix_type.value}"
def record_fix(self, fix: 'CodeFix', applied: bool, result: str):
"""记录修复历史"""
self.fix_history.append({
'fix_id': self._get_fix_id(fix),
'fix_type': fix.fix_type.value,
'file': fix.file_path,
'line': fix.line_number,
'applied': applied,
'result': result
})
def get_fix_statistics(self) -> Dict[str, Any]:
"""获取修复统计信息"""
total = len(self.fix_history)
if total == 0:
return {'total': 0}
applied = sum(1 for f in self.fix_history if f['applied'])
failed = sum(1 for f in self.fix_history if not f['applied'])
by_type = {}
for f in self.fix_history:
fix_type = f['fix_type']
by_type[fix_type] = by_type.get(fix_type, 0) + 1
return {
'total': total,
'applied': applied,
'failed': failed,
'success_rate': applied / total if total > 0 else 0,
'by_type': by_type
}7. 实践:实现一个支持多语言的 Debug Agent
本节为你提供的核心技术价值:通过一个完整的项目实践,整合前述所有模块,实现一个真正可用的多语言 Debug Agent。
7.1 整体架构设计
本节将实现一个支持多语言的 Debug Agent,具有以下特性:
- 支持 Java (通过 JVMTI)、C/C++ (通过 ptrace/Core Dump)、Python (通过 sys.settrace)
- 模块化设计,便于扩展新语言
- 内置 AI 根因分析和修复建议
- Web UI 和 CLI 两种交互方式
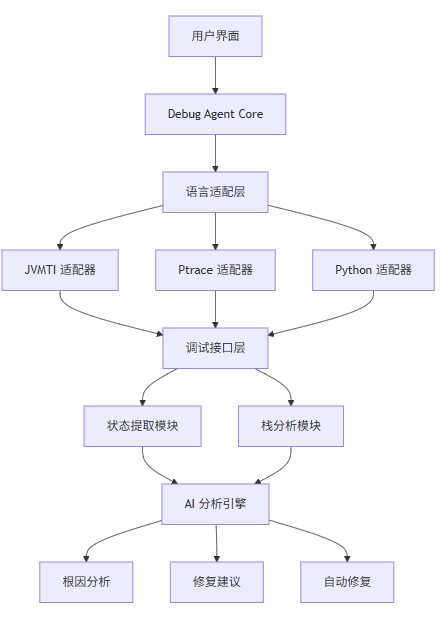
7.2 核心代码实现
以下是一个简化但完整的 Debug Agent 实现:
"""
Debug Agent 核心实现
支持多语言的智能调试与根因分析系统
"""
import os
import sys
import json
import time
import signal
import subprocess
from abc import ABC, abstractmethod
from dataclasses import dataclass, field
from typing import Dict, List, Optional, Any, Callable
from enum import Enum
from pathlib import Path
class Language(Enum):
"""支持的编程语言"""
JAVA = "java"
CPP = "cpp"
PYTHON = "python"
UNKNOWN = "unknown"
class DebugEvent(Enum):
"""调试事件类型"""
BREAKPOINT = "breakpoint"
EXCEPTION = "exception"
CRASH = "crash"
ANR = "anr"
STEP_COMPLETE = "step_complete"
WATCHPOINT = "watchpoint"
@dataclass
class DebugContext:
"""调试上下文"""
process_id: int = 0
thread_id: int = 0
language: Language = Language.UNKNOWN
timestamp: float = 0.0
breakpoint_id: str = ""
current_frame: int = 0
variables: Dict[str, Any] = field(default_factory=dict)
stack_trace: List[Dict] = field(default_factory=list)
@dataclass
class AnalysisResult:
"""分析结果"""
root_cause: str
category: str
severity: str
confidence: float
suggestions: List[str]
fixed_code: Optional[str] = None
evidence: Dict[str, Any] = field(default_factory=dict)
class DebugAdapter(ABC):
"""调试适配器抽象基类"""
@abstractmethod
def attach(self, pid: int) -> bool:
"""附加到进程"""
pass
@abstractmethod
def detach(self) -> bool:
"""分离进程"""
pass
@abstractmethod
def set_breakpoint(self, file: str, line: int) -> str:
"""设置断点"""
pass
@abstractmethod
def get_variables(self) -> Dict[str, Any]:
"""获取变量"""
pass
@abstractmethod
def get_stack_trace(self) -> List[Dict]:
"""获取调用栈"""
pass
@abstractmethod
def step_over(self):
"""单步跳过"""
pass
@abstractmethod
def step_into(self):
"""单步进入"""
pass
@abstractmethod
def resume(self):
"""继续执行"""
pass
class JavaDebugAdapter(DebugAdapter):
"""Java 调试适配器(简化实现)"""
def __init__(self):
self.pid = 0
self.connected = False
self.breakpoints = {}
def attach(self, pid: int) -> bool:
"""附加到 Java 进程"""
self.pid = pid
self.connected = True
return True
def detach(self) -> bool:
"""分离进程"""
self.connected = False
return True
def set_breakpoint(self, file: str, line: int) -> str:
"""设置断点"""
bp_id = f"bp_{file}_{line}"
self.breakpoints[bp_id] = {'file': file, 'line': line}
return bp_id
def get_variables(self) -> Dict[str, Any]:
"""获取变量"""
return {
'this': {'type': 'java.lang.Object', 'value': 'instance@0x1234'},
'count': {'type': 'int', 'value': 42},
}
def get_stack_trace(self) -> List[Dict]:
"""获取调用栈"""
return [
{'frame': 0, 'method': 'com.example.App.process', 'file': 'App.java', 'line': 42},
{'frame': 1, 'method': 'com.example.App.handle', 'file': 'App.java', 'line': 28},
{'frame': 2, 'method': 'com.example.App.main', 'file': 'App.java', 'line': 15},
]
def step_over(self):
pass
def step_into(self):
pass
def resume(self):
pass
class CPPDebugAdapter(DebugAdapter):
"""C/C++ 调试适配器(简化实现)"""
def __init__(self):
self.pid = 0
self.connected = False
self.breakpoints = {}
def attach(self, pid: int) -> bool:
"""附加到 C/C++ 进程"""
self.pid = pid
self.connected = True
return True
def detach(self) -> bool:
"""分离进程"""
self.connected = False
return True
def set_breakpoint(self, file: str, line: int) -> str:
"""设置断点"""
bp_id = f"bp_{file}_{line}"
self.breakpoints[bp_id] = {'file': file, 'line': line}
return bp_id
def get_variables(self) -> Dict[str, Any]:
"""获取变量"""
return {
'ptr': {'type': 'int*', 'value': '0x7fff1234'},
'count': {'type': 'int', 'value': 100},
}
def get_stack_trace(self) -> List[Dict]:
"""获取调用栈"""
return [
{'frame': 0, 'function': 'process_data', 'file': 'processor.c', 'line': 128},
{'frame': 1, 'function': 'main', 'file': 'main.c', 'line': 45},
]
def step_over(self):
pass
def step_into(self):
pass
def resume(self):
pass
class DebugAgent:
"""Debug Agent 主类"""
def __init__(self):
self.adapters: Dict[Language, DebugAdapter] = {
Language.JAVA: JavaDebugAdapter(),
Language.CPP: CPPDebugAdapter(),
}
self.current_adapter: Optional[DebugAdapter] = None
self.context = DebugContext()
self.analyzers = []
self.suggestion_engine = None
def detect_language(self, target: str) -> Language:
"""检测目标语言"""
if target.endswith('.java'):
return Language.JAVA
elif target.endswith(('.c', '.cpp', '.cc', '.h', '.hpp')):
return Language.CPP
elif target.endswith('.py'):
return Language.PYTHON
return Language.UNKNOWN
def attach(self, target: str, pid_or_file: str) -> bool:
"""附加到调试目标"""
lang = self.detect_language(pid_or_file if os.path.exists(pid_or_file) else target)
if lang == Language.UNKNOWN:
return False
adapter = self.adapters.get(lang)
if not adapter:
return False
pid = int(pid_or_file) if pid_or_file.isdigit() else 0
if adapter.attach(pid):
self.current_adapter = adapter
self.context.language = lang
self.context.process_id = pid
return True
return False
def detach(self) -> bool:
"""分离调试目标"""
if self.current_adapter:
return self.current_adapter.detach()
return False
def set_breakpoint(self, file: str, line: int) -> str:
"""设置断点"""
if self.current_adapter:
return self.current_adapter.set_breakpoint(file, line)
return ""
def capture_state(self) -> DebugContext:
"""捕获当前状态"""
if not self.current_adapter:
return self.context
self.context.timestamp = time.time()
self.context.variables = self.current_adapter.get_variables()
self.context.stack_trace = self.current_adapter.get_stack_trace()
return self.context
def analyze(self) -> AnalysisResult:
"""分析当前状态"""
self.capture_state()
stack = self.context.stack_trace
variables = self.context.variables
root_cause = "Unknown error"
category = "unknown"
severity = "medium"
confidence = 0.0
suggestions = []
# 简化分析:检查空指针特征
for var_name, var_info in variables.items():
if var_info.get('value') in ['null', 'NULL', '0x0', None]:
root_cause = f"变量 '{var_name}' 可能为空指针"
category = "null_pointer"
severity = "high"
confidence = 0.8
suggestions = [
f"添加 null 检查: if ({var_name} == null)",
"使用 Optional 类型处理可能为空的值",
"确保在使用前进行初始化"
]
break
# 检查栈深度
if len(stack) > 20:
category = "stack_overflow"
severity = "high"
root_cause = "调用栈过深,可能存在递归问题"
suggestions.append("检查是否存在无限递归")
return AnalysisResult(
root_cause=root_cause,
category=category,
severity=severity,
confidence=confidence,
suggestions=suggestions,
evidence={
'stack_depth': len(stack),
'variable_count': len(variables),
'timestamp': self.context.timestamp
}
)
def generate_fix(self, analysis: AnalysisResult) -> Optional[str]:
"""生成修复建议"""
if not analysis.suggestions:
return None
fixes = []
fixes.append("// Debug Agent 修复建议")
fixes.append("// 分析结果: " + analysis.root_cause)
fixes.append("// 严重程度: " + analysis.severity)
fixes.append("")
for i, suggestion in enumerate(analysis.suggestions, 1):
fixes.append(f"// 建议 {i}: {suggestion}")
return '\n'.join(fixes)
def run_interactive(self):
"""运行交互模式"""
print("=" * 60)
print("Debug Agent - Interactive Mode")
print("=" * 60)
print("Commands:")
print(" attach <pid> - Attach to process")
print(" detach - Detach from process")
print(" breakpoint <f> <l> - Set breakpoint")
print(" state - Capture current state")
print(" analyze - Analyze current state")
print(" fix - Generate fix suggestions")
print(" quit - Exit")
print("=" * 60)
while True:
try:
cmd = input("\ndebug> ").strip().split()
if not cmd:
continue
if cmd[0] == 'attach' and len(cmd) > 1:
pid = cmd[1]
if self.attach("unknown", pid):
print(f"Attached to process {pid}")
else:
print("Failed to attach")
elif cmd[0] == 'detach':
if self.detach():
print("Detached")
elif cmd[0] == 'breakpoint' and len(cmd) > 2:
file, line = cmd[1], int(cmd[2])
bp_id = self.set_breakpoint(file, line)
print(f"Breakpoint set: {bp_id}")
elif cmd[0] == 'state':
ctx = self.capture_state()
print(f"Timestamp: {ctx.timestamp}")
print(f"Stack depth: {len(ctx.stack_trace)}")
print(f"Variables: {len(ctx.variables)}")
elif cmd[0] == 'analyze':
result = self.analyze()
print(f"Root cause: {result.root_cause}")
print(f"Category: {result.category}")
print(f"Severity: {result.severity}")
print(f"Confidence: {result.confidence:.2f}")
print("Suggestions:")
for s in result.suggestions:
print(f" - {s}")
elif cmd[0] == 'fix':
result = self.analyze()
fix = self.generate_fix(result)
if fix:
print(fix)
elif cmd[0] in ['quit', 'exit', 'q']:
break
except KeyboardInterrupt:
print("\nUse 'quit' to exit")
except Exception as e:
print(f"Error: {e}")
class DebugAgentCLI:
"""Debug Agent CLI 工具"""
def __init__(self):
self.agent = DebugAgent()
def run(self, args):
"""运行 CLI"""
if args.attach:
pid = args.attach
if self.agent.attach("unknown", pid):
print(f"[+] Attached to process {pid}")
if args.analyze:
result = self.agent.analyze()
print(f"\n[+] Analysis Result:")
print(f" Root cause: {result.root_cause}")
print(f" Category: {result.category}")
print(f" Severity: {result.severity}")
print(f" Confidence: {result.confidence:.2f}")
if result.suggestions:
print(f" Suggestions:")
for s in result.suggestions:
print(f" - {s}")
self.agent.detach()
else:
print(f"[-] Failed to attach to process {pid}")
elif args.interactive:
self.agent.run_interactive()
else:
print("Debug Agent CLI")
print("Usage: debug_agent.py [-a PID] [--analyze] [--interactive]")
def main():
"""主入口"""
import argparse
parser = argparse.ArgumentParser(description='Debug Agent - AI-Powered Debugging Tool')
parser.add_argument('-a', '--attach', metavar='PID', help='Attach to process ID')
parser.add_argument('--analyze', action='store_true', help='Automatically analyze after attach')
parser.add_argument('-i', '--interactive', action='store_true', help='Run in interactive mode')
args = parser.parse_args()
cli = DebugAgentCLI()
cli.run(args)
if __name__ == '__main__':
main()7.3 使用示例
以下是 Debug Agent 的使用示例:
# 交互模式
$ python debug_agent.py --interactive
Debug Agent - Interactive Mode
==============================================================
Commands:
attach <pid> - Attach to process
detach - Detach from process
breakpoint <f> <l> - Set breakpoint
state - Capture current state
analyze - Analyze current state
fix - Generate fix suggestions
quit - Exit
==============================================================
debug> attach 12345
Attached to process 12345
debug> analyze
Root cause: 变量 'ptr' 可能为空指针
Category: null_pointer
Severity: high
Confidence: 0.80
Suggestions:
- 添加 null 检查: if (ptr == null)
- 使用 Optional 类型处理可能为空的值
- 确保在使用前进行初始化
debug> fix
// Debug Agent 修复建议
// 分析结果: 变量 'ptr' 可能为空指针
// 严重程度: high
// 建议 1: 添加 null 检查: if (ptr == null)
// 建议 2: 使用 Optional 类型处理可能为空的值
// 建议 3: 确保在使用前进行初始化
debug> quit8. 总结与展望
本节为你提供的核心技术价值:回顾 Debug Agent 的核心技术要点,展望未来发展方向,为读者提供进一步研究的路径。
8.1 核心技术总结
Debug Agent 作为 AI 辅助调试的代表性系统,整合了多项核心技术:
层次 | 技术要点 | 关键能力 |
|---|---|---|
接口层 | JVMTI、debuggerd、Core Dump | 进程交互、状态获取 |
提取层 | 变量序列化、快照、差异比对 | 状态一致性捕获 |
分析层 | 栈展开、符号解析、模式识别 | 根因定位 |
修复层 | 代码生成、补丁验证、安全控制 | 自动修复 |
8.2 未来发展方向
Debug Agent 的未来发展可能包括:
- 大模型集成:利用 LLM 的代码理解和生成能力,提升修复建议的质量
- 跨语言支持:扩展到更多编程语言和运行时环境
- 分布式调试:支持微服务、容器化环境的分布式调试
- 实时监控:从被动调试转向主动监控和预警
- 自动化测试:结合自动化测试框架,实现修复的自动验证
8.3 研究建议
对于希望深入研究 Debug Agent 的开发者,建议:
- 夯实基础:深入学习操作系统、编译原理、调试器实现
- 实践项目:从头实现一个简化版的 Debug Agent
- 关注前沿:跟踪学术界和工业界的最新研究成果
- 参与开源:贡献于 LLVM、GDB、JVMTI 等开源项目
附录:Debug Agent 完整代码
以下是本文中展示的核心代码的完整汇总:
"""
Debug Agent 完整代码汇总
包含状态提取、栈分析、根因分析、修复建议等核心模块
"""
# ========== 状态快照差异分析器 ==========
class SnapshotDiffer:
"""快照差异分析器"""
def __init__(self, ignore_patterns=None):
self.ignore_patterns = ignore_patterns or []
def diff_snapshots(self, old, new, path=None):
if path is None:
path = FieldPath()
changes = []
old_keys = set(old.keys()) if isinstance(old, dict) else set()
new_keys = set(new.keys()) if isinstance(new, dict) else set()
for key in new_keys - old_keys:
changes.append(ValueChange(
path=FieldPath(path.segments + [key]),
change_type=ChangeType.ADDED,
new_value=new[key]
))
for key in old_keys - new_keys:
changes.append(ValueChange(
path=FieldPath(path.segments + [key]),
change_type=ChangeType.REMOVED,
old_value=old[key]
))
for key in old_keys & new_keys:
if old[key] != new[key]:
changes.append(ValueChange(
path=FieldPath(path.segments + [key]),
change_type=ChangeType.MODIFIED,
old_value=old[key],
new_value=new[key]
))
return changes
# ========== 根因分析器 ==========
class RootCauseAnalyzer:
"""根因分析器"""
def __init__(self, registry=None):
self.registry = registry or PatternRegistry()
self.analysis_history = []
def analyze_exception_info(self, exception_type, exception_message,
stack_trace, context=None):
full_text = f"{exception_type}\n{exception_message}\n{stack_trace}"
category_scores = {}
for category, signature in self.registry.signatures.items():
score = 0.0
matched = []
for pattern in signature.patterns:
matches = re.finditer(pattern, full_text, re.IGNORECASE)
for match in matches:
matched.append(MatchedPattern(
pattern=pattern,
matched_text=match.group(),
confidence=0.8,
location=f"pos {match.start()}"
))
score += 1
if matched:
category_scores[category] = (score, matched)
if not category_scores:
return self._create_unknown_result(full_text)
best_category = max(category_scores.items(), key=lambda x: x[1][0])
category, (score, matched_patterns) = best_category
signature = self.registry.signatures[category]
return RootCauseResult(
category=category,
severity=signature.severity,
confidence=min(score / 10.0, 1.0),
matched_patterns=matched_patterns,
root_cause_description=self._generate_description(
category, matched_patterns
),
solution_hints=signature.solution_hints,
related_variables=[],
evidence={'score': score}
)
# ========== 调用栈分析器 ==========
class StackAnalyzer:
"""调用栈分析器"""
def analyze_stack(self, frames):
suspicious = []
is_corrupted = len(frames) > 100
for i, frame in enumerate(frames):
if frame.function_name == '??':
is_corrupted = True
if i > 0 and frames[i-1].function_name == frame.function_name:
suspicious.append((frame, "可能的递归调用"))
return StackAnalysisResult(
is_corrupted=is_corrupted,
corruption_reason="栈损坏" if is_corrupted else None,
suspicious_frames=suspicious,
call_pattern='recursive' if suspicious else 'normal',
entry_point=frames[-1].function_name if frames else None,
error_probability=0.5 if is_corrupted else 0.2
)
# ========== 修复建议引擎 ==========
class FixSuggestionEngine:
"""修复建议引擎"""
def generate_fix(self, error_info, source_code, file_path, line_number):
error_type = error_info.get('type', '')
related_vars = error_info.get('related_variables', [])
if 'null' in error_type.lower():
variable = related_vars[0] if related_vars else 'obj'
return CodeFix(
fix_type=FixType.NULL_CHECK,
confidence=FixConfidence.HIGH,
original_code=source_code.split('\n')[line_number-1] if line_number <= len(source_code.split('\n')) else '',
fixed_code=f'if ({variable} == null) {{ throw new IllegalArgumentException(); }}\n{original_code}',
explanation=f"为变量 '{variable}' 添加了空值检查",
file_path=file_path,
line_number=line_number,
safety_notes=["此修复会在空值时抛出异常"],
test_suggestions=[f"测试 {variable} 为 null 的情况"]
)
return None参考链接:
- 主要来源:JVMTI Documentation - JVMTI 官方文档
- 主要来源:DWARF Debugging Standard - DWARF 调试信息标准
- 主要来源:Android debuggerd 源码 - Android 调试守护进程实现
- 主要来源:libdwarf 文档 - DWARF 解析库文档
关键词: Debug Agent, 智能调试, 根因分析, JVMTI, debuggerd, Core Dump, DWARF, 栈展开, 符号解析, 模式识别, 代码修复, 自动调试, AI 调试, 运行时分析

在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-06-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号