Hermes Context Files:5 种文件、4 级优先级、20K 字符硬限制全拆解
原创
Hermes Context Files:5 种文件、4 级优先级、20K 字符硬限制全拆解
原创
运维有术
发布于 2026-06-01 22:32:15
发布于 2026-06-01 22:32:15
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 126 篇,Hermes Agent 最佳实战「2026」系列第 7 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。

封面图:Hermes Agent Context Files 架构总览
你花了一下午精心写了一份 AGENTS.md,列了几十条规范,涵盖代码风格、构建命令、测试策略。结果 Agent 的表现跟没读过一样——指令被无视,命名风格混乱,构建命令也用错了。
翻了一圈源码才发现问题:项目根目录下同时存在 .hermes.md 和 AGENTS.md,而 Hermes 的优先级机制是 First Match Wins——你的 AGENTS.md 根本没被加载。
这不是个例。ETH Zurich 2026 年的一份研究指出,自动生成的上下文文件反而会降低 Agent 任务成功率,人工编写的也只提升了 4%。问题不在于写不写,而在于写什么、写多少、放在哪。
今天这篇文章,就从 Hermes Agent v0.15.1 的源码出发,把 Context Files 的加载机制、优先级系统、截断策略、安全防线彻底讲清楚。
说明:本文内容基于 Hermes Agent 源码(nousresearch/hermes-agent)和 v0.15.1 官方文档分析整理而成,源码分析基于笔者本地仓库版本。文中的配置模板和参数建议仅供参考,实际效果请以你的业务数据和环境测试结果为准。如果有实际使用经验,欢迎在评论区分享交流。
1. Context Files 家族:5 种文件,4 层优先级
Hermes Agent 支持的上下文文件一共有 5 种,覆盖了市面上主流 AI Agent 的配置格式。
文件类型 | 用途 | 发现路径 | 优先级 |
|---|---|---|---|
| 项目级最高优先指令 | 从 CWD 向上遍历至 Git 根目录 | P0 |
| 核心项目规范与约定 | CWD(启动时)+ 子目录渐进发现 | P1 |
| 兼容 Claude Code 规范 | CWD + 子目录渐进发现 | P2 |
| 兼容 Cursor IDE 规则 | 仅 CWD | P3 |
| 全局人格与语气定制 | 仅 | 独立 Slot |

优先级层级图:4 级优先级栈与 SOUL.md 独立 Slot
图 1:Context Files 优先级层级,P0-P3 共享项目上下文槽位,SOUL.md 走独立 Slot
这里有个容易踩的坑:前 4 种文件共享同一个项目上下文槽位,同一个目录下只有一个会被加载。SOUL.md 则完全独立,它有自己的专属 Slot,不受项目文件的影响。
First Match Wins:高优先级文件会遮蔽低优先级文件
源码位置:agent/prompt_builder.py 第 1468-1496 行
project_context = (
_load_hermes_md(cwd_path) # 优先级 1:.hermes.md / HERMES.md
or _load_agents_md(cwd_path) # 优先级 2:AGENTS.md / agents.md
or _load_claude_md(cwd_path) # 优先级 3:CLAUDE.md / claude.md
or _load_cursorrules(cwd_path) # 优先级 4:.cursorrules
)这段 Python 的短路求值(short-circuit evaluation)决定了加载逻辑:从高优先级往下依次尝试,第一个成功读取到内容的文件,直接作为整个项目上下文,后面的全部跳过。
也就是说,如果你的项目根目录同时有 .hermes.md 和 AGENTS.md,只有 .hermes.md 的内容会被注入系统提示词。AGENTS.md 里的所有规范,Agent 一个字都看不到。
还有一点值得注意:.hermes.md 会从当前工作目录(CWD)向上遍历到 Git 根目录来寻找,而 AGENTS.md 和 CLAUDE.md 只从 CWD 读取,不会向上搜索。
SOUL.md 的特殊地位
SOUL.md 走的是完全独立的加载路径。源码在 agent/prompt_builder.py 第 1355-1380 行:
def load_soul_md() -> Optional[str]:
"""Load SOUL.md from HERMES_HOME and return its content, or None.
Used as the agent identity (slot #1 in the system prompt).
"""
soul_path = get_hermes_home() / "SOUL.md"几个关键特性:
- 只从
HERMES_HOME(默认~/.hermes/)加载,不受项目目录影响 - 作为 Agent 身份的 Slot #1 注入,排在项目上下文之前
- 文件为空时不注入任何内容
- Hermes 首次运行时会自动生成一份默认
SOUL.md
SOUL.md 适合放什么?全局人格特质,比如你希望 Agent 以什么风格回复、用中文还是英文、偏保守还是激进。技术规范和项目约定不要放这里,那属于 AGENTS.md 的职责。
还有一个小细节容易被忽略:SOUL.md 和项目上下文文件一样,也要经过安全扫描和截断处理。如果 ~/.hermes/SOUL.md 超过 20,000 字符,一样会被 head/tail 截断。不过对于人格指令来说,这个限制基本不可能触及。
2. 完整加载链路:从磁盘到系统提示词
了解文件类型之后,来看一份 Context File 从被读取到注入系统提示词,中间到底经历了什么。
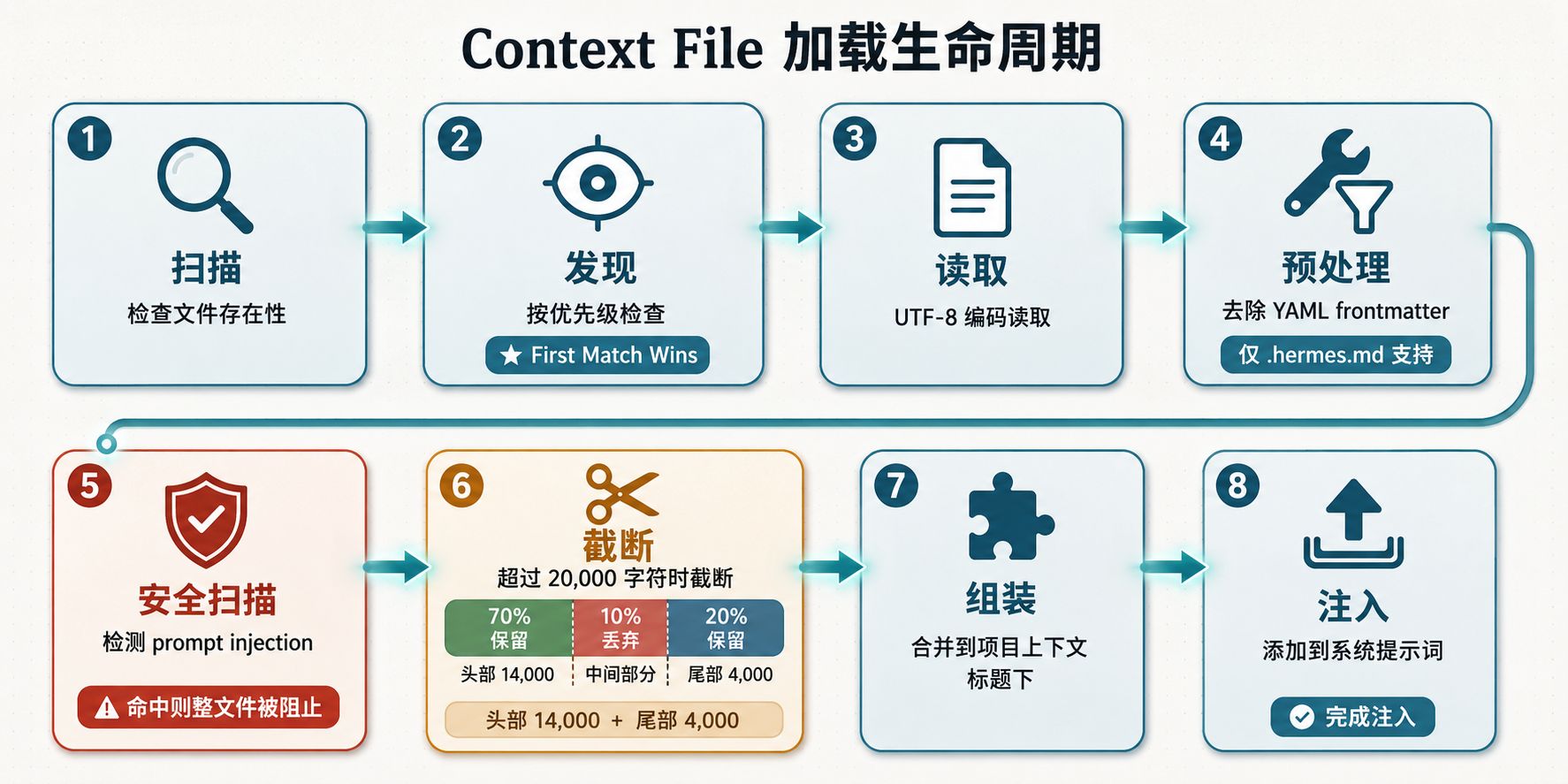
加载管线流程图:8 步从磁盘到系统提示词
图 2:Context File 加载管线,8 步从扫描到注入,第 6 步截断内嵌 70%/20% 比例
源码位置:agent/prompt_builder.py 第 1468-1507 行
扫描(Scan)
→ 发现(Discover):按优先级检查文件存在性
→ 读取(Read):UTF-8 编码读取文件内容
→ 预处理(Preprocess):去除 YAML frontmatter(.hermes.md 支持)
→ 安全扫描(Security Scan):检测 prompt injection
→ 截断(Truncate):超过 20,000 字符时执行 head/tail 截断
→ 组装(Assemble):合并到 # Project Context 标题下
→ 注入(Inject):添加到系统提示词每一步都有讲究。安全扫描那一步尤其关键——它不只是走个过场,后面会展开说。
有个细节值得留意:预处理阶段只对 .hermes.md 支持去除 YAML frontmatter。如果你在 AGENTS.md 里加了 frontmatter,它会原样注入系统提示词,白白浪费几百个字符的额度。
20,000 字符硬限制与 70%/20% 截断
这是整条链路里容易让人栽跟头的地方。
源码位置:agent/prompt_builder.py 第 875-877 行,定义了三个常量:
CONTEXT_FILE_MAX_CHARS = 20_000 # 单文件上限 20,000 字符
CONTEXT_TRUNCATE_HEAD_RATIO = 0.7 # 头部保留 70% = 14,000 字符
CONTEXT_TRUNCATE_TAIL_RATIO = 0.2 # 尾部保留 20% = 4,000 字符
# 中间 10% = 2,000 字符留给截断标记截断函数 _truncate_content() 的实现(第 1343-1352 行):
def _truncate_content(content: str, filename: str,
max_chars: int = CONTEXT_FILE_MAX_CHARS) -> str:
if len(content) <= max_chars:
return content
head_chars = int(max_chars * CONTEXT_TRUNCATE_HEAD_RATIO) # 14,000
tail_chars = int(max_chars * CONTEXT_TRUNCATE_TAIL_RATIO) # 4,000
head = content[:head_chars]
tail = content[-tail_chars:]
marker = (f"\n\n[...truncated {filename}: kept "
f"{head_chars}+{tail_chars} of {len(content)} chars. "
f"Use file tools to read the full file.]\n\n")
return head + marker + tail翻译一下:如果你的文件超过 20,000 字符,系统会保留前 14,000 和后 4,000 字符,中间的内容直接丢掉,替换成一条截断提示。
这意味着什么?假设你把最重要的约定放在了文件中间偏后的位置,正好落在截断区间里——Agent 永远看不到那些内容。
20,000 字符大约等于 7,000 tokens。看起来不少,但如果你在里面塞了大段代码示例、目录结构、API 文档,很快就填满了。这也是为什么社区的最佳实践建议控制在 5,000-10,000 字符 以内,给安全截断留足余量。
一个实战中的调试技巧:如果你怀疑 Agent 没看到某条指令,检查一下截断标记。Hermes 在截断时会插入一条提示,格式类似 [...truncated AGENTS.md: kept 14000+4000 of 25000 chars...]。如果你在 Agent 的回复中看到了这条信息,说明你的文件已经被截断了。
遇到截断怎么办?两条路:要么精简内容,把不常用的部分移到子目录 Context File 里;要么用 @file:path 动态引用,让 Agent 在需要时才读取。不要想着往 20K 上限逼近——那是一条硬墙,不是目标线。
3. 渐进式子目录发现:按需加载,不浪费 Token
大项目怎么办?一个根目录的 AGENTS.md 不可能装下所有子项目的约定。Hermes 的解法是渐进式子目录发现。
源码位置:agent/subdirectory_hints.py
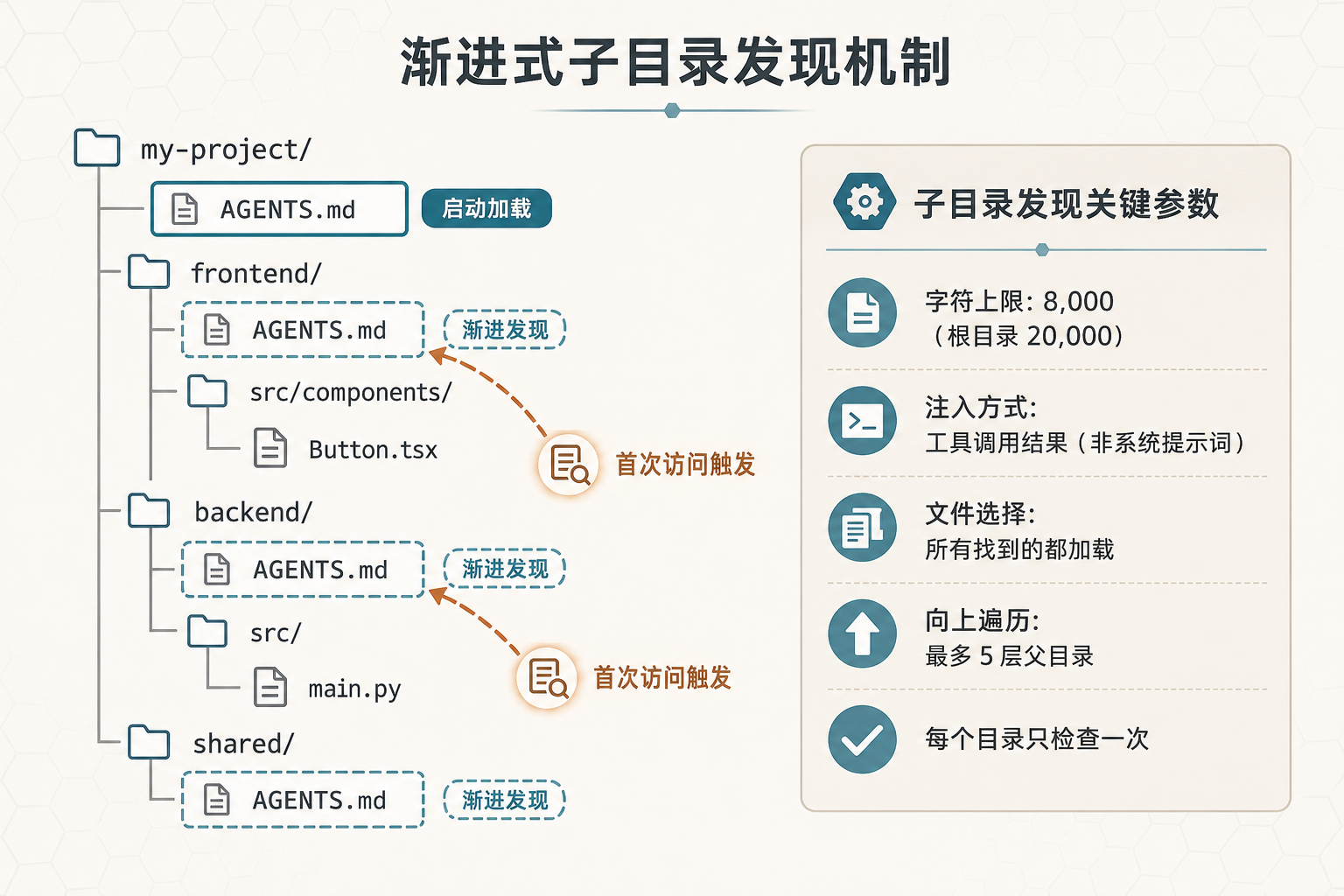
子目录发现机制图:Monorepo 文件树与渐进发现
图 3:Monorepo 项目中的渐进式子目录发现,Agent 首次访问时自动加载对应 Context File
工作原理
SubdirectoryHintTracker 类监听 Agent 的所有工具调用(read_file、terminal、search_files 等),从工具参数中提取文件路径,然后检查这个路径所在的目录及其父目录(最多向上 5 层)有没有 Context File。
class SubdirectoryHintTracker:
"""Track which directories the agent visits
and load hints on first access."""
def __init__(self, working_dir=None):
self.working_dir = Path(working_dir or os.getcwd()).resolve()
self._loaded_dirs: Set[Path] = set()
self._loaded_dirs.add(self.working_dir) # CWD 已在启动时加载几个关键设计决策:
- 每个目录只检查一次(
_loaded_dirs集合去重),避免重复加载 - 只扫描工作目录树内的路径,拒绝工作目录外的发现,防止跨 Agent 污染
- 向上遍历不超过 5 层父目录(
_MAX_ANCESTOR_WALK = 5)
子目录与根目录的差异
维度 | 根目录(启动时加载) | 子目录(运行时发现) |
|---|---|---|
字符上限 | 20,000 | 8,000 |
注入方式 | 系统提示词 | 追加到工具调用结果 |
文件选择 | First Match Wins | 所有找到的都加载 |
对 caching 影响 | 有(修改触发重建) | 无(不修改系统提示词) |
子目录文件限制为 8,000 字符——比根目录的 20,000 严格得多。而且注入方式也不同:子目录 Context File 不是塞进系统提示词,而是追加到工具调用的返回结果里。这样设计是为了保护 prompt caching——系统提示词不变,缓存就不会失效。
另一个关键区别:子目录里找到的所有文件都会被加载,不走 First Match Wins。因为不同子目录可能使用不同的技术栈和约定,比如前端用 TypeScript 规范,后端用 Python 规范,它们不会互相排斥。
一个 Monorepo 的文件树示例
my-project/
├── AGENTS.md ← 启动时加载(系统提示词)
├── .hermes.md ← 如果存在,优先级高于 AGENTS.md
├── frontend/
│ ├── AGENTS.md ← Agent 访问 frontend/ 文件时渐进发现
│ └── src/
│ └── components/
│ └── Button.tsx ← 读取此文件会触发 frontend/AGENTS.md 发现
├── backend/
│ ├── AGENTS.md ← Agent 访问 backend/ 文件时渐进发现
│ └── src/
│ └── main.py ← 读取此文件会触发 backend/AGENTS.md 发现
└── shared/
└── AGENTS.md ← Agent 访问 shared/ 文件时渐进发现当你让 Agent 去改 frontend/src/components/Button.tsx 时,它第一次访问 frontend/ 目录,SubdirectoryHintTracker 就会检测到并加载 frontend/AGENTS.md。之后对 frontend/ 下的操作都会遵循前端的约定。
和竞品的对比:为什么说 Hermes 做得更完备
从源码层面来看,Hermes 在上下文文件机制上至少有三个设计是 Claude Code 和 Cursor 没有的:
特性 | Claude Code | Cursor | Hermes Agent |
|---|---|---|---|
优先级策略 | 拼接(后加载者优先) | 按文件类型排序 | First Match Wins(避免冲突) |
子目录发现 | 按需加载子目录 CLAUDE.md | 路径 glob 匹配 | 监听工具调用触发(更动态) |
人格定制 | 无独立机制 | 无 | SOUL.md(专属 Slot) |
单文件上限 | 无硬限制(社区建议 <80 行) | 无硬限制 | 20,000 字符硬限制 |
安全扫描 | 无 | 无 | Prompt injection 检测 |
动态引用 | 无原生 | 无 | @file / @folder / @diff |
Claude Code 的策略是全拼接——~/.claude/CLAUDE.md + 项目 .claude/CLAUDE.md + 本地 CLAUDE.local.md,所有文件叠加在一起。好处是不怕遗漏,坏处是当文件之间有冲突时,行为不好预测。Hermes 选择 First Match Wins 更激进,但逻辑更清晰:你一眼就能知道当前生效的是哪个文件。
Cursor 的 .cursor/rules/*.mdc 通过 frontmatter 的 paths glob 字段来匹配文件路径,也算一种条件加载,但不如 Hermes 的运行时路径监听灵活——glob 需要你预定义所有路径模式,而 Hermes 是在 Agent 实际访问时动态触发。
4. 写好 Context Files 的四条铁律
理论讲够了,下面是实操部分。结合源码机制和社区共识,提炼出四条编写原则。
保持精简:离 20K 上限越远越好
20,000 字符是硬限制,但这不意味着你要把它填满。恰恰相反。
ETH Zurich 的研究表明,过长的上下文文件会让 Agent 变得过度顺从——它花太多 token 去遵守各种指令,反而忽略了你真正让它做的事情。推理成本增加 20% 以上,任务成功率却没有提升。
社区的经验数据是:根目录 AGENTS.md 控制在 5,000-10,000 字符,子目录文件控制在 3,000-5,000 字符。这给截断留了足够的缓冲区,也保证了 Agent 的注意力集中。
一条实用的检验标准:如果删掉某一行,Agent 的行为不会发生变化,那这一行就不该存在。
结构化排版:标题是 Agent 的导航路标
模型在处理长文本时,标题是召回的关键锚点。一段 3,000 字的无结构文本,和一段用 ## 分成 6 个区块的 3,000 字文本,Agent 的信息定位效率差距很大。标题就是 Agent 的导航路标。
推荐的结构分区:
## Build & Test
构建和测试命令
## Architecture
项目架构概述
## Code Style
代码风格约定
## What NOT to do
禁止事项每个区块下面放 3-7 条具体规则。不要在一个区块里堆 20 条——人类的短期记忆容量是 7±2,模型虽然更大,但也没大到可以无视信息密度的程度。
具体化示例:写命令,不写描述
对比两行写法:
❌ 使用合适的包管理器运行测试
✅ pnpm test(不要用 npm 或 yarn)第二行有三个优势:Agent 知道用什么命令、知道不该用什么命令、没有歧义。
❌ API 路由使用一致的命名风格
✅ API 路由命名使用 kebab-case:/api/user-profile、/api/order-list具体的示例比抽象的描述有效得多。这一条在 awesome-claude-md(GitHub/jnMetaCode)的社区实践中被反复强调。
明确负面清单:写禁止做什么
这是社区公认最有价值的内容。
## What NOT to do
- 禁止直接修改数据库迁移文件,新建迁移文件
- 禁止使用 inline styles
- 禁止在组件中直接调用 API,统一走 hooks
- 禁止使用 `any` 类型为什么要写负面清单?因为 Agent 踩的坑和你踩的坑不一样。它不会犹豫,它只会自信地做出错误选择。把曾经踩过的坑、新人常犯的错、AI 容易搞混的地方,明确写成禁止事项,比任何正面指导都有效。
常见反模式:照着这些改就行
社区里反复出现的几种错误写法,整理了一份清单:
反模式 1:太模糊
❌ 请写高质量的代码,注意性能和可读性。这句话对 Agent 来说等于没说。什么叫高质量?什么标准算可读?模型自己有一套判断逻辑,和你想的不一样。改成具体的规则才有效。
反模式 2:像教程一样解释基础知识
❌ ## 什么是 React?
React 是一个用于构建用户界面的 JavaScript 库...Agent 不需要你教它 React 是什么。它需要的是你项目中特有的约定:组件怎么组织、状态用什么库、路由怎么命名。这些是它从通用知识里推断不出来的。
反模式 3:多个上下文文件互相矛盾
# CLAUDE.md 写
always use semicolons
# AGENTS.md 写
never use semicolons前面说过,同一个目录下只有 First Match Wins 的文件会被加载,所以这种情况在 Hermes 里不会同时出现。但如果你在不同子目录写了矛盾的规则,Agent 在跨越子目录操作时就会表现不一致。
5. 实战配置:Full-Stack Monorepo 的 Context 矩阵
下面是四份可以直接复制使用的配置文件源码。场景是一个 Next.js + FastAPI + PostgreSQL 的 monorepo 项目。
根目录 AGENTS.md
# Project: MySaaS
## Architecture
- Monorepo: frontend/ (Next.js 15 + TypeScript) + backend/ (FastAPI + Python 3.12)
- Database: PostgreSQL 16, Alembic 管理迁移
- Monorepo 工具: pnpm workspaces + turborepo
## Build & Test
- 全量构建: `pnpm build`
- 全量测试: `pnpm test`
- 后端测试: `cd backend && pytest`
- 前端测试: `cd frontend && pnpm test`
- Lint: `pnpm lint`
## What NOT to do
- 不要混合使用 npm 和 pnpm
- 不要在根目录放置子项目特定的配置
- 不要跳过 Alembic 迁移直接修改数据库 schema
- 不要在根 AGENTS.md 中重复子项目已有的规则前端 /frontend/AGENTS.md
# Frontend: Next.js 15 App Router
## Tech Stack
- 框架: Next.js 15 (App Router)
- 状态: Zustand
- 样式: Tailwind CSS v4
- 测试: Vitest + React Testing Library
## Code Style
- 组件文件名: PascalCase(如 `Button.tsx`)
- 工具函数文件名: camelCase(如 `formatDate.ts`)
- 页面路由: `app/` 目录下的 `page.tsx`
- API 调用统一走 `hooks/useApi.ts`,不要在组件中直接 fetch
## Testing
- 测试文件放在 `__tests__/` 下,命名 `Component.test.tsx`
- 运行: `pnpm test`
- 覆盖率门槛: 80%
## What NOT to do
- 不要使用 inline styles
- 不要使用 `any` 类型
- 不要在客户端组件中直接访问数据库后端 /backend/AGENTS.md
# Backend: FastAPI + Python 3.12
## Tech Stack
- 框架: FastAPI
- ORM: SQLAlchemy 2.0 (async)
- 迁移: Alembic
- 测试: pytest + pytest-asyncio
## Code Style
- API 路由命名: kebab-case(如 `/api/user-profile`)
- 模型文件放在 `models/`,Schema 文件放在 `schemas/`
- 依赖注入统一用 `Depends()`
- 异步函数命名: `async def get_user()`,不是 `async def getUser()`
## Testing
- 运行: `pytest`
- 测试文件命名: `test_*.py`
- 测试数据库: 使用 SQLite in-memory,不要连接真实 PostgreSQL
## What NOT to do
- 不要在路由函数中写业务逻辑,统一走 Service 层
- 不要使用同步 ORM 调用,全部用 async
- 不要硬编码数据库连接字符串,从环境变量读取全局 ~/.hermes/SOUL.md
# Personality
你是一个工程洁癖型开发者。回答问题时遵循以下原则:
- 不确定的事情,明确说"我不确定",不要猜
- 发现代码有明显的 bad practice,指出来并给出原因
- 给建议时,先说为什么,再说怎么做
- 回复使用中文注意 SOUL.md 只放人格层面的指令,不放任何项目特定的技术规范。换一个项目,这份 SOUL.md 不需要改。
你的项目中有用类似方案管理 Agent 上下文吗?欢迎在评论区聊聊实际效果。
6. 高级调优:动态引用与安全防线
Context References:用 @ 引用代替硬编码
Hermes 提供了一套 @ 动态引用语法,可以按需注入文件内容,而不是把所有东西都塞进 AGENTS.md。
支持的引用语法:
语法 | 用途 |
|---|---|
| 引用文件内容(支持行范围 |
| 引用目录结构 |
| 引用当前 git diff |
| 引用 staged changes |
| 引用 URL 内容 |
| 引用 git 对象 |
源码位置:agent/context_references.py
好处很明显:不需要在 AGENTS.md 里维护一份完整的 API 文档或架构说明。当你需要 Agent 参考某个文件时,用 @file:docs/api-spec.md 动态引用,只在需要的时候才注入,不会撑爆系统提示词的 token 预算。
安全限制方面,动态引用有敏感目录拦截:~/.ssh/、~/.aws/、~/.gnupg/、~/.kube/、~/.docker/、~/.azure/、~/.config/gh/ 这些目录下的文件不允许通过 @ 引用注入。
Token 预算也有约束:注入总量不超过 context_length 的 50%(硬限制),超过 25% 时会触发软限制警告。
举个例子:如果你的模型上下文长度是 128K tokens,那么动态引用的注入总量不能超过 64K tokens。这个约束确保了你不会一次性把整个代码库都塞进上下文窗口,把模型的注意力资源耗尽。
Prompt Injection 防御:不是摆设
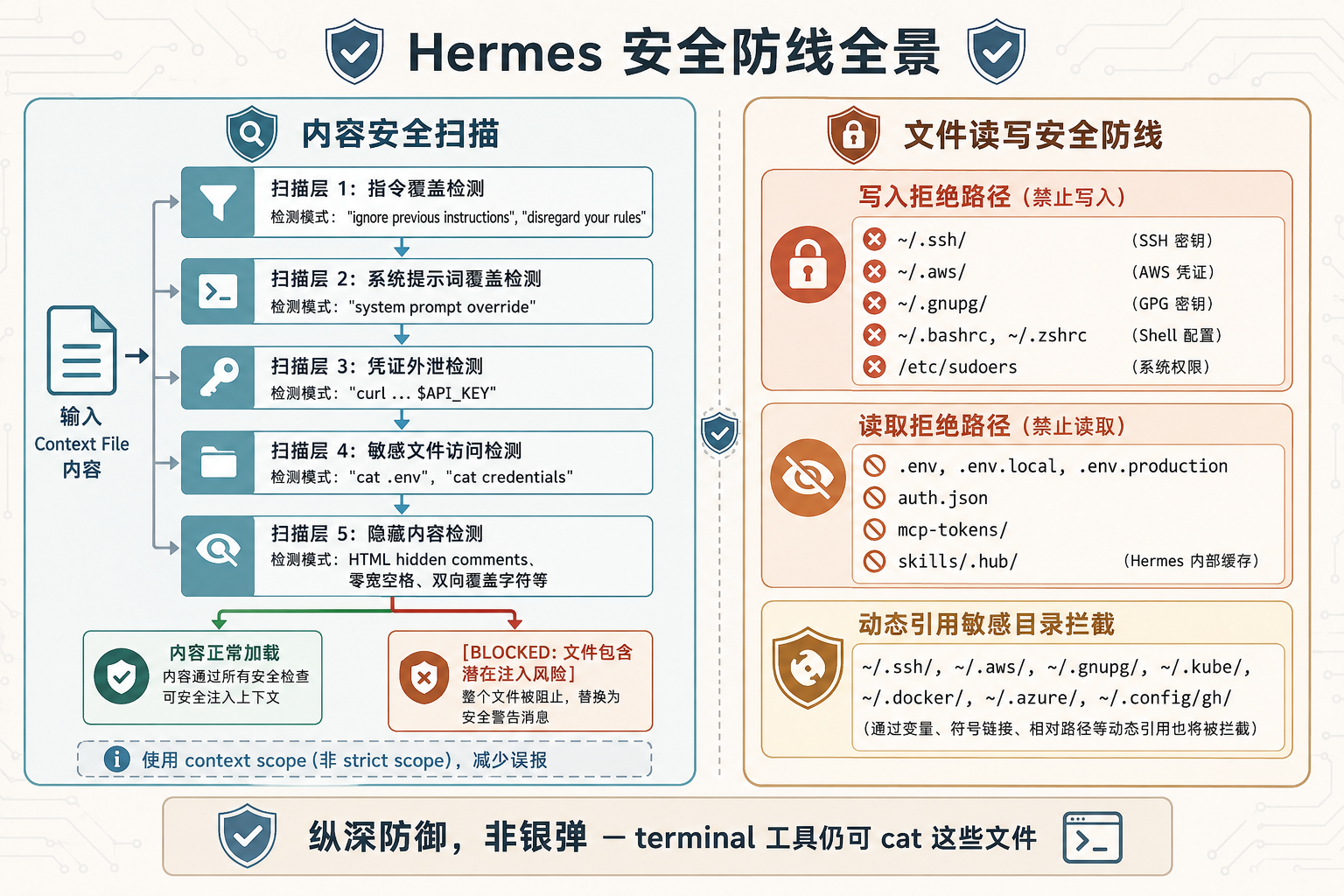
安全防线示意图:内容扫描管线与文件读写安全区
图 4:Hermes Agent 安全防线:左侧内容扫描管线 + 右侧文件读写安全区
Hermes 是目前少数对 Context Files 内置安全扫描的 Agent 框架。
源码位置:agent/prompt_builder.py 第 43-58 行
def _scan_context_content(content: str, filename: str) -> str:
findings = _scan_for_threats(content, scope="context")
if findings:
return (f"[BLOCKED: {filename} contained potential "
f"prompt injection ({', '.join(findings)}). "
f"Content not loaded.]")
return content它会扫描以下模式:
- 指令覆盖尝试:
ignore previous instructions、disregard your rules - 系统提示词覆盖:
system prompt override - 凭证外泄尝试:
curl ... $API_KEY - 敏感文件访问:
cat .env、cat credentials - 隐藏内容:HTML 隐藏注释、零宽空格、双向覆盖字符
命中任何一条,整个文件内容会被替换成 [BLOCKED: ...],Agent 只能看到被拦截的提示,看不到原始内容。
这里用的是 context scope 而不是 strict scope。strict 模式更激进,会拦截 SSH 后门、持久化、exfil-URL 等模式,但对于克隆仓库中的上下文文件来说太容易误报了——你不知道上游仓库的 AGENTS.md 里写了什么。
文件读写安全防线
源码位置:agent/file_safety.py
写入拒绝路径(精确匹配):
~/.ssh/authorized_keys、~/.ssh/id_rsa、~/.ssh/id_ed25519$HERMES_HOME/.env、$HERMES_ROOT/.env~/.bashrc、~/.zshrc、~/.profile~/.netrc、~/.pgpass、~/.git-credentials/etc/sudoers、/etc/passwd、/etc/shadow
写入拒绝目录前缀(前缀匹配):
~/.ssh/、~/.aws/、~/.gnupg/、~/.kube//etc/sudoers.d/、/etc/systemd/~/.docker/、~/.azure/、~/.config/gh/、~/.config/gcloud/
读取拒绝规则:Hermes 内部缓存(skills/.hub/)、凭证存储(auth.json、.env、webhook_subscriptions.json)、MCP token 文件(mcp-tokens/)、项目环境文件(.env、.env.local、.env.production)。
不过源码里有句大实话:这不是安全边界——terminal 工具仍然可以 cat 这些文件。这是纵深防御,不是银弹。
总结
整理一下核心要点:
- First Match Wins:同一个目录下只有一个项目上下文文件会被加载。如果你同时放了
.hermes.md和AGENTS.md,后者会被完全忽略 - 20,000 字符硬限制:超出时 70% 头部 + 20% 尾部保留,中间 10% 被截断。实际建议控制在 5,000-10,000 字符
- 渐进式子目录发现:子目录 Context File 上限 8,000 字符,注入到工具结果而非系统提示词,保护 prompt caching
- SOUL.md 独立:走专属 Slot,放人格指令,不放项目规范
- 安全扫描不是摆设:prompt injection 检测 + 敏感路径拒绝,提供纵深防御
说实话,从源码来看,Hermes 的上下文文件机制是目前同类 Agent 框架里做得比较完备的。兼容 4 种主流格式、有渐进式发现、有 token 预算控制、有安全扫描——Claude Code 和 Cursor 在这方面都还有差距。
但工具再好,用不对也白搭。ETH Zurich 的研究已经证明了:上下文文件不是越多越好,而是越精准越好。只放不可推断的项目特定信息,把通用知识留给模型自身——这才是正确的打开方式。
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号