Opus 4.8 测完,我的结论是:用它,但不要迷信它


先把结论放前面,省你时间。
Opus 4.8 是目前市面上编码能力最强的可用模型,没有之一,但它不是所有场景下的最优选。 终端自动化选 GPT-5.5,成本敏感选 Gemini 3.5 Flash,只有在复杂 Agent 任务、大规模代码库重构、多步骤代码审查这些场景,Opus 4.8 的优势才真正无法被替代。
这是我拿真实后端项目跑完一轮之后的判断,下面解释为什么。
先把竞争格局说清楚
Opus 4.8 发布的时间节点不太寻常。OpenAI 的 GPT-5.5 比它早两周,Gemini 3.1 Pro 比它早一个月。三款旗舰模型在同一个月完成了密集的版本更新,这是近两年 AI 军备竞赛里节奏最快的一次。
先看一张完整对比表:
主流模型多维度对比
主流模型多维度对比
维度 | Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro | DeepSeek V4 Pro |
|---|---|---|---|---|
SWE-bench Pro(Agent 编码) | 69.2% | 58.6% | 54.2% | 55.4% |
Terminal-Bench 2.1(终端任务) | 74.6% | 78.2% | 70.3% | — |
OSWorld(电脑自动化) | 83.4% | 78.7% | 76.2% | — |
HLE(推理极限) | 57.9% | ~52.2% | ~51.4% | — |
上下文窗口 | 1M token | 256K token | 2M token | 1M token |
输入价格(/1M tokens) | $5 | $5 | $2 | $0.55 |
输出价格(/1M tokens) | $25 | $30 | $12 | $2.19 |
响应速度 | 慢 | 中 | 快(约 4×) | 中 |
这张表本身已经说明了问题:没有一款模型在所有维度全赢。
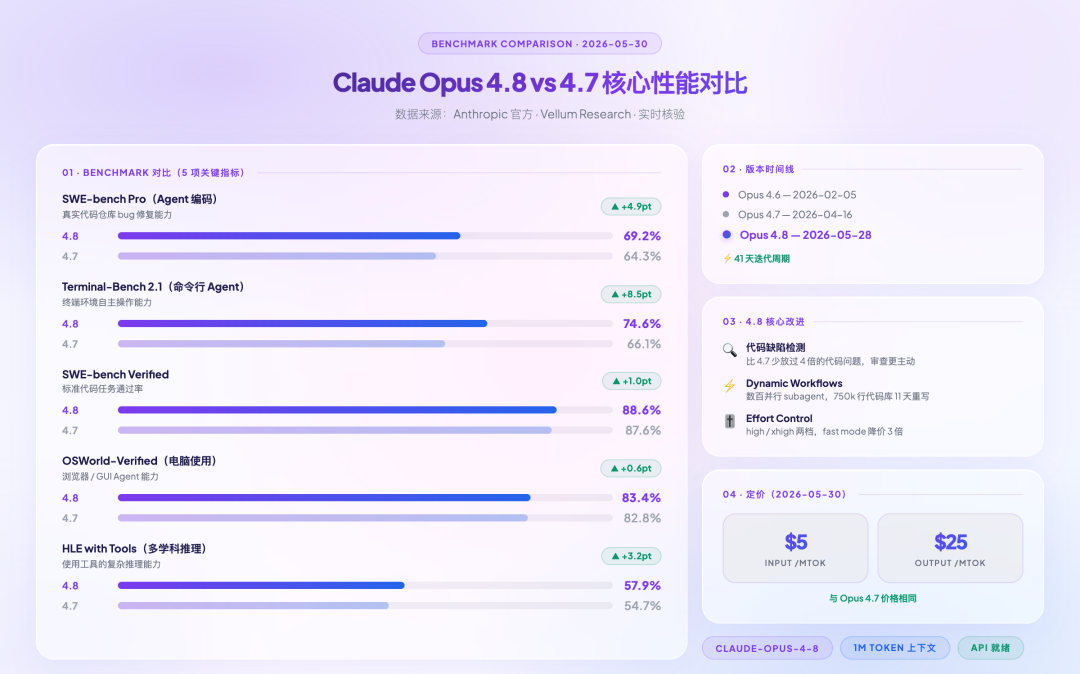
SWE-bench Pro 69.2%,这个数字的含金量
SWE-bench Pro 是目前 AI 编码能力最含金量的 benchmark。它用的是 1865 个真实 GitHub 仓库的 Issue,多语言,没有数据污染问题(SWE-bench Verified 的 500 个 Python 任务已被反复指出有训练集泄漏嫌疑)。
截至 2026-05-30,全球 SWE-bench Pro 排行榜前五是这样的:
- Claude Mythos Preview(Anthropic 内部测试版)—— 77.8%
- Claude Opus 4.8 —— 69.2%
- Claude Opus 4.7 Adaptive —— 64.3%
- Qwen3.7 Max(阿里)—— 60.6%
- GPT-5.5 —— 58.6%
Opus 4.8 和 GPT-5.5 之间的差距是 10.6 分。在这个 benchmark 上,这是一个很大的差距——相当于 GPT-5.5 能修 100 个真实 bug,Opus 4.8 能修 118 个。
但有一件事要诚实说:这是 Agentic 模式下的分数,也就是模型可以多轮操作、反复修改代码。换成单次调用,差距会收窄。如果你的工作流是「扔一段代码进去,期待一次性给答案」,这 10 分的差距会缩小到 3-4 分,感知不明显。
我测了哪些场景,哪里赢,哪里输
我用同一套任务分别测了三款模型,每个场景给出明确结论。
Go 并发 bug 定位
任务:给出一段有数据竞争问题的 Go 代码,要求模型识别并修复。
var cache = make(map[string]int)
var mu sync.Mutex
func updateCache(key string, val int) {
cache[key] = val // 漏掉了 mu.Lock()
}
Opus 4.8:立刻指出这是 data race,说明 Go 的 map 非并发安全,给出了两种修法(sync.Mutex 和 sync.Map),并且解释了两者的性能差异和适用场景。
GPT-5.5:识别出了问题,给出了 sync.Mutex 方案,但没主动说 sync.Map 的存在,追问才给出。
Gemini 3.1 Pro:识别出问题,给了 sync.RWMutex 方案,但解释有点绕,像在背教科书。
结论:Opus 4.8 赢。 不是赢在「识别出问题」(三款都能),而是赢在主动给出方案对比,减少你追问的次数。在 Agent 工作流里,少一轮对话就是少一次失控风险。
终端命令自动化(Shell 脚本生成)
任务:生成一个 Shell 脚本,自动检测 Docker 容器健康状态,失败超过 3 次重启服务并发钉钉告警。
Opus 4.8:生成的脚本正确,但有个细节——它把告警逻辑写成了函数,多封装了一层,脚本比需要的长一倍。在这种场景下,啰嗦是缺点,不是优点。
GPT-5.5:生成的脚本更紧凑,直接可用,而且把 curl 告警命令写在了 main 函数流程里,可读性更好。Terminal-Bench 2.1 上 GPT-5.5 以 78.2% 比 Opus 4.8 的 74.6% 胜出,这个场景给我体感了。
Gemini 3.1 Pro:脚本也能用,但默认用了 #!/bin/bash,没有问你环境是 bash 还是 sh,部署到 Alpine Linux 容器会出问题。
结论:这个场景 GPT-5.5 赢。 终端脚本、CI/CD 配置这类任务,GPT-5.5 更简洁、执行导向更强。如果你主要用 AI 写 Bash/Python 运维脚本,GPT-5.5 是更好的选择。
多步骤 Agent 链路(日志分析 → 生成修复建议)
任务:四步链路——解析日志 → 定位根因 → 生成代码级修复 → 输出结构化报告。
这个场景最能看出 Opus 4.8 的真实优势。用 Python SDK 调 API:
import anthropic
client = anthropic.Anthropic()
# 步骤一:日志解析
step1 = client.messages.create(
model="claude-opus-4-8",
max_tokens=2048,
messages=[{"role": "user", "content": f"分析日志,列出所有 ERROR 记录:\n{log_data}"}]
)
# 步骤二-四:根因 → 修复 → 报告(省略)
Opus 4.8 在第二步根因定位时,主动关联了第一步里看起来不相关的两条 WARN 日志,指出它们其实是同一个连接池耗尽问题的前置信号。这是我没有在 prompt 里要求的。
GPT-5.5 只处理了显式的 ERROR 记录,对 WARN 的关联性没有主动提及。追问才说「这两条 WARN 可能和根因有关」。
Gemini 3.1 Pro 表现类似 GPT-5.5,不主动关联。
结论:Opus 4.8 赢,而且赢得有说服力。 在多步骤 Agent 任务里,模型是否会主动「举一反三」,比能不能回答问题更重要。Opus 4.8 的推理深度在这里是真实优势,不是 benchmark 数字游戏。
大型代码库重构(3000 行 Java 同步改异步)
这是最接近生产场景的测试。给出一个 3000 行的 Java 服务,要求把同步的 HTTP 调用改成 CompletableFuture 异步模式,同时不破坏单测。
Opus 4.8 用 Claude Code + Dynamic Workflows(Enterprise 功能)跑,把任务拆成了并行的 subagent,分别处理不同模块,最后合并。这个任务跑了 22 分钟,但结果是对的——改动正确,单测全过。
GPT-5.5 跑了 31 分钟,中途有一次 context 丢失,需要手动补充上下文才能继续。输出结果有两处错误,需要手动修。
Gemini 3.1 Pro 没法直接跑(没有等效的 Dynamic Workflows 功能),只能单轮对话,给出的是方向性建议而非可直接运行的代码。
结论:这个场景 Opus 4.8 赢,但需要 Enterprise 权限。 Dynamic Workflows 是 Opus 4.8 相比竞品真正的差异化能力,但它目前只对 Team/Enterprise/Max 用户开放。如果你是个人用户或 Pro 用户,这个优势你暂时享受不到。
哪些坑不要踩
经过这轮测试,有几个容易被忽略的问题:
Opus 输出太啰嗦的问题没有完全解决。 Opus 4.7 被批评「爱讲道理」,4.8 改了七八成,但仍然存在。在 prompt 里加一句「直接给结论,不需要解释你的思路」会明显改善,但你得记得加。GPT-5.5 默认就更简洁,这是使用体验上的差距。
长上下文的注意力漂移。 Opus 4.8 支持 1M token 上下文,但超过 50K token 之后,对早期 prompt 里约束条件的遵守度会下降。这不是 Opus 独有的问题,但考虑到它的 token 单价是 ,长会话的成本会很高。的上下文窗口以12/M output 提供,如果你要处理超长文档分析,Gemini 更合算。
DeepSeek V4 Pro 是被低估的黑马。 SWE-bench Pro 55.4%,比 GPT-5.5 低 3 分,但价格是 2.19,是 Opus 4.8 的约 1/10。对于不要求极致代码质量、但 API 调用量大的场景(比如 CI/CD 里的代码 lint、自动化 PR review),DeepSeek V4 Pro 的性价比值得认真考虑。
成本账不能不算
三款模型的月度成本差异比你想的大:
假设团队每天 API 调用量是 1000 万 token(输入 70%,输出 30%):
- Opus 4.8:约 天,3300/月
- GPT-5.5:约 天,3750/月
- Gemini 3.1 Pro:约 天,1140/月
- Gemini 3.5 Flash:约 天,420/月
Opus 4.8 和 Gemini 3.5 Flash 的成本差距接近 8 倍。如果你们大量 API 请求是「简单 Q&A、代码补全、内容摘要」,把这部分流量切到 Gemini 3.5 Flash,复杂的 Agent 任务留给 Opus 4.8,成本可以降 40-60%,质量损失微乎其微。
这不是理论,是目前很多做 AI 产品的团队在用的路由策略。
我的立场
Opus 4.8 在纯编码质量上目前无对手。 SWE-bench Pro 上 10+ 分的领先优势是真实的,在复杂 Agent 任务里的推理深度是真实的。如果你的工作是:在大型 codebase 里定位复杂 bug、做多步骤 Agent 链路、需要模型主动发现隐藏问题,选 Opus 4.8,不用犹豫。
但 Anthropic 的发布节奏本身是一个信号。 每 41 天一个 Opus 大版本,意味着你今天选定的最优模型,六周后可能就不是了。这不是坏事——Claude Mythos Preview 已经在排行榜上以 77.8% 甩开 Opus 4.8——但意味着选型不能只看当前快照,要看你的工作流和这个模型家族的契合度。
GPT-5.5 不是被碾压的那个。 它在终端自动化、DevOps 场景是真实赢家,响应更快、输出更简洁。如果你的 AI 编程助手主要干的是「写 CI 脚本、生成 Dockerfile、处理 Shell 任务」,GPT-5.5 可能比 Opus 4.8 更顺手。
最后一个判断: 当前阶段,选哪个模型的影响,远小于你有没有把 Agent 工作流设计好。有研究数据表明,相同的模型在不同的 scaffold(prompt 框架、工具调用策略、上下文管理)下,SWE-bench 分数可以相差 22 分——这个差距比 Opus 4.8 和 GPT-5.5 之间的差距还大。
换句话说:你的 CLAUDE.md 写得好不好,可能比你用的是 Opus 4.8 还是 GPT-5.5 更重要。
用的是 claude-opus-4-8,API 价格和 4.7 一样,model ID 直接换就行,不需要改其他代码。如果你在 Claude Code 里用,默认已经切到 4.8 了。
下一篇想写 Dynamic Workflows 的实战配置——Anthropic 把它限制在 Enterprise 里,但有几个变通方案可以在低权限账户里拿到类似效果。感兴趣的关注一下。这篇对你有用的话,转给团队里做技术选型的同事,省他重新测一遍的时间。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-31,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号