Google放了个大的:Flash干翻Pro,每月烧掉3200万亿token

Google放了个大的:Flash干翻Pro,每月烧掉3200万亿token

老周聊架构
发布于 2026-06-01 17:37:22
发布于 2026-06-01 17:37:22
Google每月处理3.2千万亿(quadrillion)token。一年前这个数字是480万亿。一年,翻了7倍。 换算一下:每分钟190亿token。你读完这句话的时间里,Google已经处理了大约570亿token。
这周AI圈最大的新闻,不是谁又刷了个榜,而是Google在I/O 2026上干了一件反常识的事:
他们的"廉价版"模型,干翻了上代"旗舰版"。
Gemini 3.5 Flash——一个Flash级别的模型,在Agentic和编程任务上全面超越上一代Gemini 3.1 Pro。发布当天就全量上线,直接成为Gemini App(9亿月活)和Google搜索AI Mode(10亿月活)的全球默认模型。
这就好比丰田突然宣布:新款卡罗拉的百公里加速比上代雷克萨斯还快,而且便宜25%,今天全球4S店同步提车。
你说雷克萨斯车主什么心情?
一、Flash干翻Pro:到底强在哪?
先看数据。Gemini 3.5 Flash对比上代旗舰Gemini 3.1 Pro:
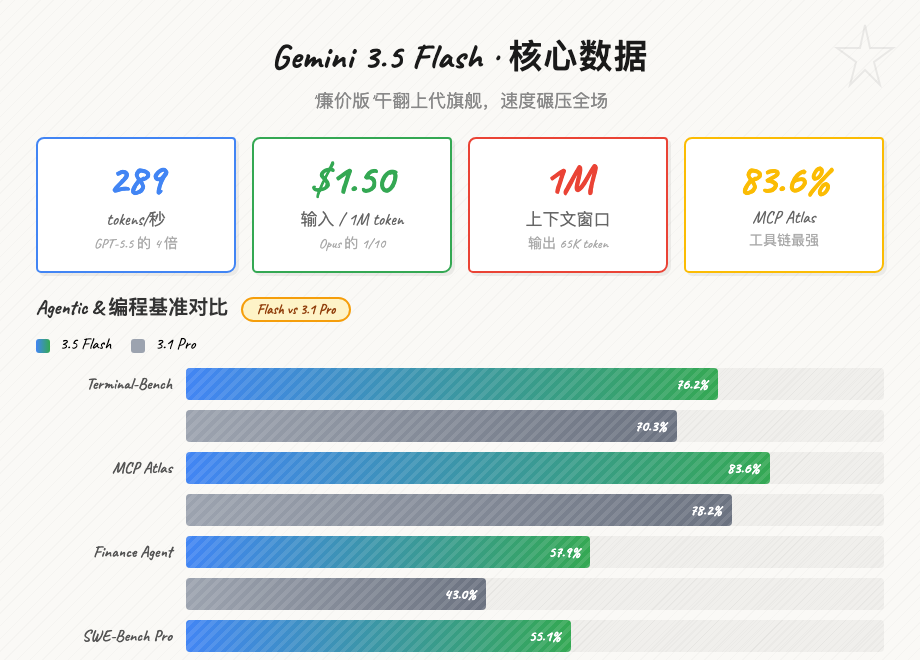
Gemini 3.5 Flash 核心数据
基准测试 | 3.5 Flash | 3.1 Pro | 差距 |
|---|---|---|---|
Terminal-Bench 2.1(Agentic) | 76.2% | 70.3% | +5.9 |
MCP Atlas(工具链) | 83.6% | 78.2% | +5.4 |
Finance Agent v2 | 57.9% | 43.0% | +14.9 |
Blueprint-Bench 2 | 33.6% | 26.5% | +7.1 |
SWE-Bench Pro(代码) | 55.1% | 54.2% | +0.9 |
MMMU-Pro(多模态推理) | 84.2% | — | 历史最高 |
关键数字:289 tokens/秒。
这个速度是GPT-5.5的4倍(71 tok/s),是Claude Opus 4的4.3倍(67 tok/s)。
用人话说:同样生成一篇1000字的报告,Claude Opus 4需要约30秒,GPT-5.5需要约28秒,Gemini 3.5 Flash只要7秒。
但Pro也不是完全被碾压
公平起见,3.1 Pro在几个维度上仍然领先:
基准测试 | 3.5 Flash | 3.1 Pro | 赢家 |
|---|---|---|---|
ARC-AGI-2(通用推理) | 72.1% | 77.1% | Pro |
Humanity's Last Exam | 40.2% | 44.4% | Pro |
MRCR v2 128K(长上下文) | 77.3% | 84.9% | Pro |
规律很明显:Flash赢在"干活"(Agentic、编程、工具调用),Pro赢在"想事"(深度推理、长上下文理解)。
这说明什么?Google不是在做一个"缩水版Pro",而是把Flash往一个完全不同的方向调教——它不是来思考人生的,它是来干活的。
二、价格:一半欢喜一半忧
先看Gemini 3.5 Flash的定价:
模型 | 输入 $/1M token | 输出 $/1M token |
|---|---|---|
Gemini 3.5 Flash | 9.00 | |
Claude Sonnet 4.6 | $3.00 | $15.00 |
GPT-5.5 | $5.00 | $30.00 |
Claude Opus 4 | $15.00 | $75.00 |
乍一看,Flash比Sonnet便宜一半,比GPT-5.5便宜三分之二,比Opus便宜十倍。 缓存输入价格更夸张:$0.15/1M token,打一折。
但开发者社区炸锅了。
知名开发者Simon Willison直接开喷:
"Gemini 3.5 Flash is 3x more expensive than 3 Flash Preview, and 6x more expensive than 3.1 Flash-Lite. All three major AI labs appear to be starting to probe the price tolerance of their API customers." ——3.5 Flash比上代Flash贵了3倍,比Flash-Lite贵了6倍。三大AI实验室都在试探API客户的价格底线了。
这是一个很有意思的趋势:模型越来越强,但"同级别"的价格也越来越贵。Flash已经不再是那个人畜无害的便宜货了。
Artificial Analysis的独立评测更扎心:综合计算后,3.5 Flash比上代Pro还贵75%。
所以到底是便宜了还是贵了?答案是:跟竞品比便宜了,跟自家上一代比贵了。 Google在跟你玩田忌赛马——用新一代的下等马打别人的中等马。
三、Gemini Omni:一个"世界模型"悄悄登场
I/O 2026的另一个重磅,是Gemini Omni。
Google DeepMind CEO Demis Hassabis亲自上台介绍,他说的原话是:
"Omni is not a video generator. It's a world model — a system that builds an internal understanding of reality." ——Omni不是一个视频生成器。它是一个世界模型——一个构建对现实内在理解的系统。
"任意输入,任意输出"——文本、图片、音频、视频都能进,视频和音频都能出。
Demo环节,Hassabis让Omni根据一段蛋白质折叠的文字描述,直接生成了一段黏土动画风格的解释视频,配音配乐一体化。
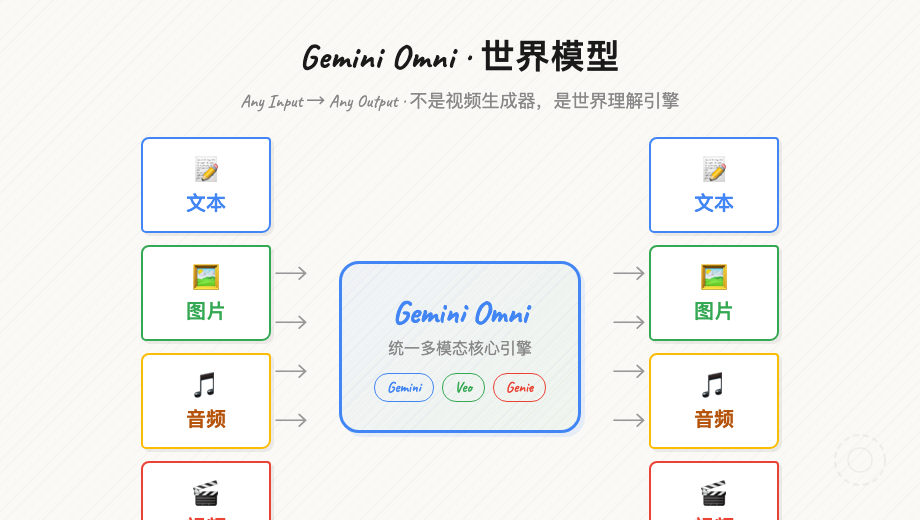
Gemini Omni 任意输入任意输出
架构上,Omni不是简单地把Gemini和Veo拼在一起。它把Gemini的推理能力和多个生成模型(Veo、Genie等)融合进了一个统一的核心引擎,所有模态在一个模型里同时处理,而不是分步走管道。
为什么这个很重要?
因为之前所有的"多模态"模型,其实都是"多个单模态模型的缝合怪"——文字进来走LLM,图片进来走ViT,视频生成走Diffusion。Omni试图打破这种管道架构,让模型真正"理解"不同模态之间的关系。
当然,这个方向早有先行者(GPT-4o就走了这条路),但Omni是目前公开的、把视频生成纳入原生多模态的最激进尝试。
四、3200万亿token的背后
Pichai在台上甩出的那个数据,值得单独拎出来聊。
年份 | 月处理token量 | 同比增长 |
|---|---|---|
I/O 2024 | 9.7万亿 | — |
I/O 2025 | 480万亿 | 49倍 |
I/O 2026 | 3200万亿 | 7倍 |
两年,330倍。
每分钟190亿token。375个Google Cloud客户在过去12个月里各自处理了超过1万亿token。850万开发者每月在用Google的模型。
The Register管这叫"Tokenmaxxing"——疯狂刷token量。
但这个数字真的有意义吗?
有,但不完全。
一方面,这说明AI已经从"实验品"变成了"基础设施"。3200万亿token不是刷出来的,是搜索、Gmail、Docs、Android、Chrome等产品真实的用户请求。Google的分发能力是它最大的护城河——你不需要去下载什么App,打开Chrome搜索就在用Gemini。
另一方面,token量≠价值量。一个用户反复问"今天天气怎么样"产生的token,和一个开发者用Agent完成复杂任务产生的token,含金量完全不同。
Pichai自己也说了:"These tokens represent problems being solved."——但问题的大小差了十万八千里。
五、跟竞品怎么比?一张图说清楚
现在前沿模型的竞争已经不是一维的"谁更聪明"了,而是在智能×速度×价格的三维空间里找位置。
维度 | Gemini 3.5 Flash | Claude Opus 4 | GPT-5.5 | Claude Sonnet 4.6 |
|---|---|---|---|---|
速度 | 289 tok/s | 67 tok/s | 71 tok/s | 82 tok/s |
SWE-Bench Pro | 55.1% | 64.3% | — | 52% |
MCP Atlas | 83.6% | 79.1% | 75.3% | — |
输入价格 | $1.50 | $15.00 | $5.00 | $3.00 |
输出价格 | $9.00 | $75.00 | $30.00 | $15.00 |
幻觉率 | 中等 | 最低 | 较低 | 低 |
一句话总结各家定位:
- Gemini 3.5 Flash:干活最快、最便宜,Agentic工具调用最强
- Claude Opus 4:写代码最强(SWE-Bench 64.3%),幻觉最少,但最贵
- GPT-5.5:深度推理最强,综合最均衡
- Claude Sonnet 4.6:性价比标杆,各项中上
如果你的场景是"Agent批量干活"——选Flash。如果你的场景是"改一个复杂的线上Bug"——选Opus。
六、I/O 2026的其他猛料
除了两个模型,Google这次I/O还甩了几个值得关注的东西:
Gemini 3.5 Pro:延期了
Pichai说"下个月上线"。台下开发者发出了一声集体叹息。
这是一个信号:Google可能在Pro级别上遇到了瓶颈,所以选择先把Flash推到极致。
Antigravity 2.0
Google的Agent开发平台,类似Claude Code但更"Agent-first"。支持动态子Agent编排、定时自动化、AI Studio集成。一个Demo展示了93个并行子Agent在一次运行中完成了15000+请求,总API成本不到$1000。
Gemini Spark
个人AI Agent,跑在Google Cloud的专属VM上,7×24小时运行,执行长周期后台任务。有点像给你配了一个"永不下线的AI助理"。
TPU 8i + 8t
第八代TPU,分推理芯片(8i)和训练芯片(8t)。Flash的289 tok/s就是跑在TPU 8i上的。
七、我的判断
看完整场I/O,我的三个核心观察:
1. "Flash级别干翻Pro"是一个行业拐点。
这意味着模型能力的增长速度,已经超过了产品线分层的更新速度。今年的Flash比去年的Pro强,明年的Nano可能比今年的Flash强。"按等级选模型"的思路正在失效——你应该按任务选模型,而不是按价格等级选。
2. Google的真正护城河不是模型,是分发。
9亿月活的Gemini App、10亿月活的AI Mode、每月3200万亿token——这些数字告诉你,Google不需要在基准测试上赢过每一个对手。它只需要"够好",然后靠Chrome、Android、Search的分发能力碾压一切。
3. "世界模型"的竞争刚刚开始。
Omni可能是今天最被低估的发布。视频生成只是表象,背后是对"物理世界理解"的野心。当AI不只是"会说话",而是"理解世界如何运作",这个变化比任何基准测试的进步都大。
Hassabis那句话说得对:"It's a step towards artificial general intelligence."
写在最后
每年I/O之后,总有人问:Google是不是又在画饼?
今年不一样。3.5 Flash发布当天就全量上线,直接替换掉了旧模型——这不是PPT发布,这是硬切换。
三大AI实验室的竞争格局越来越清晰:
- Google:不一定最强,但最快、最便宜、分发最广
- Anthropic:代码和安全性最强,开发者心智份额最高
- OpenAI:综合推理最强,品牌最响
选谁?看你的场景。
但有一件事是确定的:当Flash都能干翻Pro的时候,你再也不能用"等更好的模型出来"当摸鱼的借口了。模型够了,该你上场了。
— 完 —
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号