缓存技术:从CPU Cache到AI KV Cache (二)Linux内核Cache

缓存技术:从CPU Cache到AI KV Cache (二)Linux内核Cache

霞姐聊IT
发布于 2026-06-01 16:49:15
发布于 2026-06-01 16:49:15
三、软件缓存时代:操作系统和数据库也开始缓存
上一节介绍了CPU 与内存之间的速度差及其解决方案,本节我们关注内存与磁盘之间的速度差,以及操作系统和数据库等软件如何通过缓存机制缓解这一瓶颈。
(一)Linux内核的Buffer Cache和Page Cache
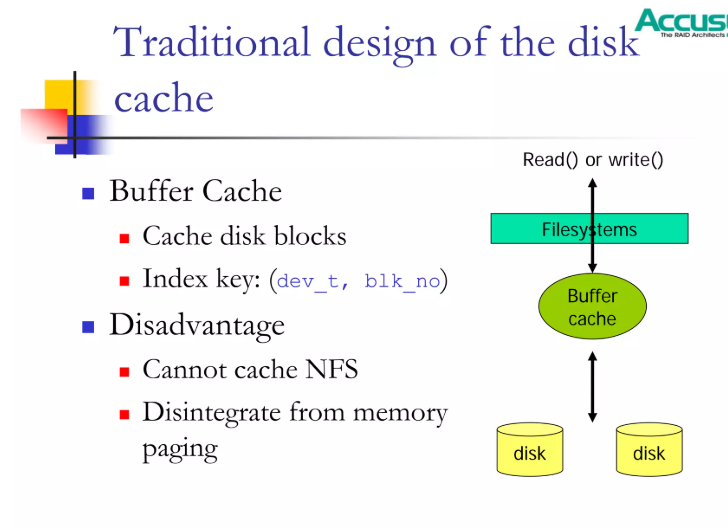
1.BufferCache Buffer Cache继承自Unix内核设计,Linux是类Unix系统,因此在Linux内核之初就存在这个方案。
Buffer Cache是内核为了解决磁盘访问过慢而设计的、存在于内存里的块级缓存系统。
内核虽然可以直接读写磁盘,但磁盘的传输速度很慢,这样系统的响应时间会很长,吞吐量会很差,性能会很糟糕。
所以内核通过在内存中保留Buffer Cache区域来减少磁盘访问的频率。
在Unix/Linux看来,disk由很多block组成,每个block里存放着512B、1KB、2KB等大小的数据。
通过Buffer Cache的数据结构可以唯一确定一个disk block:
struct buf
{
dev_t dev;//表示块设备
int blockno;//标识块号
char data[];//标识块中的数据
...
};
Buffer Cache的每个块由 struct buf 结构体表示,内核通过双向循环链表的形式,将其组织成哈希队列和空闲链表,实现对其高效的查找和分配。
对于文件系统上的常规文件访问,都必须经过Buffer Cache。
(1)读取数据时,使用bread(dev, block)接口,
如果缓存命中,直接返回buffer;
如果没有命中,则通过getblk()接口分配缓存,并发起磁盘读取,等待完成后返回buffer。
(2)写入数据时,采用Write Back策略,而不是直接用Write Through方案。
修改对应buffer并标记为Dirty,告知用户写入完成;
后面再在适当的时机调用bflush()、sync()等接口统一刷盘。
Buffer Cache与磁盘能保持“最终一致”:即大部分时间缓存数据可能与磁盘不同步。
系统通过后台刷盘、周期性sync,以及 fsck 或日志文件系统(Journal)机制,保证数据和文件系统元数据的一致性和可恢复性。
Buffer Cache带来的主要好处包括:
(1)减少磁盘读取提升系统性能
(2)实现Write Back方案,不仅能提升写性能,还能合并多次写操作,减少实际 I/O 次数,降低磁盘负载;对于闪存设备,也有助于减少写入放大,延长寿命。
(3)统一块访问接口。不管底层是什么样的块设备,使用bread()和bwrite()都可以对其进行操作。
但是Buffer Cache也存在一些局限性,比如:
(1)粒度限制
Buffer Cache 以块(block 512B、1KB、2KB)为单位管理磁盘数据,而文件操作通常按页(page 4KB、8KB)访问,导致与虚拟内存系统不兼容,文件缓存与内存管理体系割裂。
(2)不适合NFS
NFS的文件在远端服务器,客户端并不知道它的布局。
而Buffer Cache依赖 (dev, blockno)这样的本地设备索引,NFS无法提供。
因此buffer cache的管理方式无法有效管理NFS的缓存。
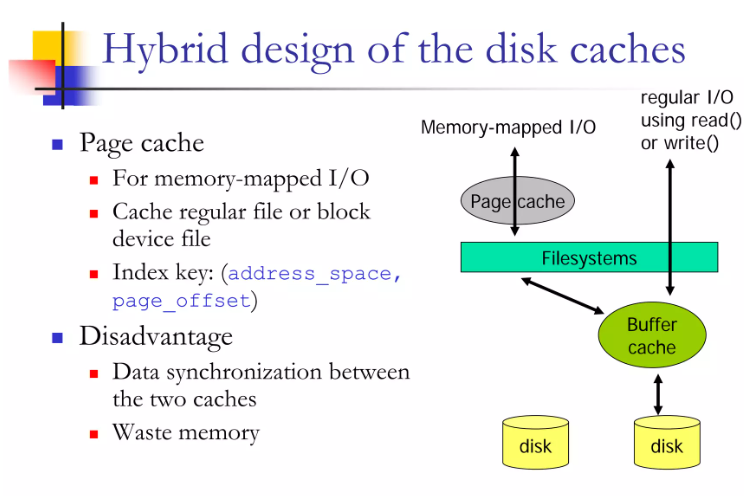
2.Page Cache
1992年的Linux 内核0.99版本开始引入虚拟内存机制;1994年,Linux内核1.0版本中实现了完整的分页式虚拟内存系统。
这时,Buffer Cache的粒度限制的局限性愈发凸显,所以在1995年,Linux内核1.3.50版本中,Page Cache被正式引入,以实现更好的缓存方案。
Page Cache是一个以内存页为单位的文件缓存系统。
它以(address_space, page_offset)的索引方式管理文件缓存。其中:
address_space:文件或设备在内核的映射结构
page_offset:对应文件内页号
可以看到,它就是为了实现文件页缓存管理设计的。
Page Cache的工作流程:
(1)读取文件
用户调用read() 或通过 mmap() 访问文件页时,内核首先在 Page Cache中查找对应 页,命中则直接返回页内容;未命中则分配一个内存页并从磁盘读取数据,再返回页内容。
(2)写入文件
用户调用write()修改文件时,先找到并修改对应的Page Cache页,将其标记为 Dirty,并返回写入成功。
后续通过sync() 或后台刷盘线程统一写回磁盘。
在这个技术方案阶段,Page Cache 和 Buffer Cache是共存的,Page Cache 负责文件页缓存,而Buffer Cache 负责块级缓存及元数据管理。
这样就带来了一些问题,包括:
(1)数据重复:同一份磁盘数据同时存在Page Cache 和 Buffer Cache
(2)同步困难:由于和buffer cache都管理着磁盘数据,因此Dirty页和块的写回需要额外逻辑,复杂度非常高。
3.Unified Page Cache
Mmap、NFS、共享库技术的普及,使得原先Page Cache和Buffer Cache同时存在产生的问题越来越凸显,因此,在1999年以后, Ingo Molnar这些内核开发工程师开始考虑Unified Page Cache技术方案。
该方案于2001年正式纳入Linux 2.4内核主线,并于2003年进化成成熟的技术方案,随Linux 2.6发布。
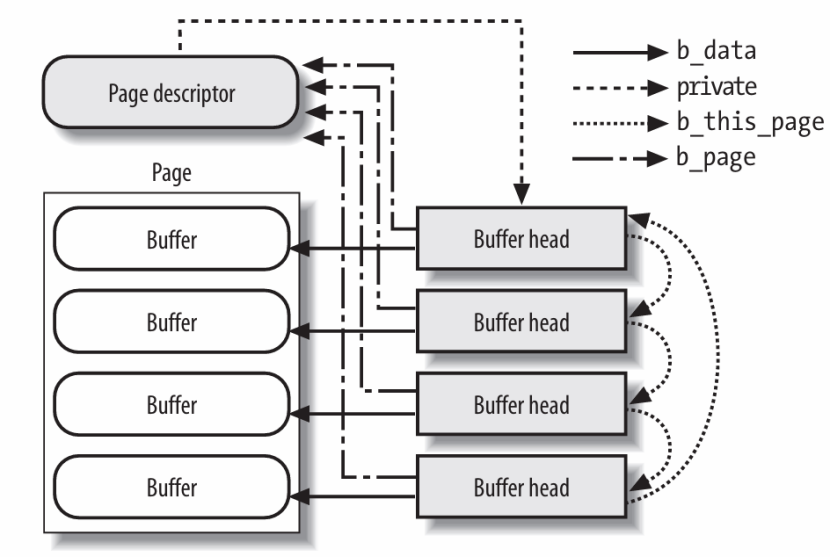
从此以后,Linux 中不再有独立的 Buffer Cache 缓存池,Buffer Cache仅作为页的元数据存在。
统一的方案如下图所示:
(1)磁盘数据会被统一缓存于Page Cache 的 Page页(物理页)里。
(2)每个Page都有一个对应的Page Descriptor(struct page),用于管理该页的状态、所属文件以及缓存信息。
(3)原先Buffer Cache的管理结构Buffer Head仍然保留,用于文件系统查询页中内容和磁盘中的块的对应关系。
可以看出来:Page负责存放数据,Buffer Head 负责描述磁盘块信息,Page Descriptor 负责管理整个页,三者协同工作,实现原来Page Cache 与 Buffer Cache 的功能。三者可以通过指针互相关联:
(1)Page Descriptor通过private指针关联一组 Buffer Head。
(2)这组Buffer Head通过b_this_page指针形成循环链表
(3)Buffer Head通过b_data指针指向该块在Page中的缓存数据区域,文件系统可以通过它定位和操作具体块的数据。。
(4)Buffer Head通过 b_page可回指Page Descriptor,通过它可以设置脏页等页状态管理工作。
4.Linux 缓存系统总结
Page Cache是内核对程序访问规律的内化利用。它还是利用了局部性原理:
刚访问过的数据还会被访问、刚访问过的数据附近的数据也会被访问,把磁盘 I/O从被动等待变成主动预测,是内核对未来访问行为的押注。
(1)刚访问过的数据还会被访问
Page Cache 的基本逻辑是:
第一次读文件:数据会从磁盘加载到Page Cache,然后传给用户;
而第二次读同样的数据,数据会在Page Cache命中,避开磁盘加载过程,传给用户。
比如执行两次下面的读文件的命令:
cat a.txt
cat a.txt
第一次可能真的读盘,第二次大概率直接从内存读。
并且,这样的时间局部性不是只服务于同一个进程,而是服务于整个操作系统。
例如:
进程 A 读了 libc.so
进程 B 启动时也需要 libc.so
如果 libc.so 已经在 Page Cache 中,B 就可以直接复用。
这也是为什么 Linux 运行久了以后,空闲内存会越来越少,但系统不一定变慢。因为很多内存被拿去记住系统最近用过的文件内容了。
(2)刚读这里,接下来可能读旁边
Page Cache的另一个关键能力是预读 read-ahead。
程序经常不是随机读取文件,而是顺序读取文件:
第 0 页 → 第 1 页 → 第 2 页 → 第 3 页
比如下面的命令都会涉及到顺序读:
grep keyword big.log
cp large.iso /tmp/
当Linux观察到你在顺序读,就会提前把后面的页读进Page Cache:
你读第1页,它会顺便读第 2、3、4、5 页
这样当程序真的访问下一页时,数据已经在内存里了。
Page Cache可以看做是内核的价值排序机制:
高概率复用的数据值得留在内存中,低复用价值的数据即使进入缓存,也会在内存压力下更容易被淘汰。
它把磁盘I/O 从被动等待,转化为基于访问模式的主动预测与调度。
也正因为如此,顺序访问、热点复用等模式能够充分发挥Page Cache 的优势,而随机 I/O、大文件一次性扫描等模式则可能造成预读浪费和缓存污染。
所以,很多存储系统的优化,本质上是在主动创造和利用局部性。
其中,LSM Tree、WAL、Kafka 日志存储、文件系统延迟分配等机制倾向于将随机访问转化为顺序访问,以增强空间局部性;
而 B+Tree 缓存、数据库 Buffer Pool 等机制则主要利用时间局部性,使热点数据能够长期驻留在内存中。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号