柳叶刀审计250万篇医学论文 & AI 如何做数据检测

柳叶刀审计250万篇医学论文 & AI 如何做数据检测

勇哥AI笔记
发布于 2026-06-01 10:03:18
发布于 2026-06-01 10:03:18
最近被耿同学刷屏,一开始是抖音上看到打假视频:确实如他所说,没想到论文数据还能造假,大数定律中末位数有均匀分布,首位数有本福特定律,论文的数据编造技术还能这么质朴无华。
(最新的好消息是,耿同学被限流之后,又解除了限制,至少我今天又刷到了他最新爆出名字的视频)
没过几天哥伦比亚大学的 CITADEL 团队在《柳叶刀》发表了一项名一篇用AI来扫描 250 万篇生物医学论文的研究结果。
发现虚假引用率正在以 12 倍的速度爆炸式增长,这个增长时间跟 AI 写作工具的普及时间对得上。
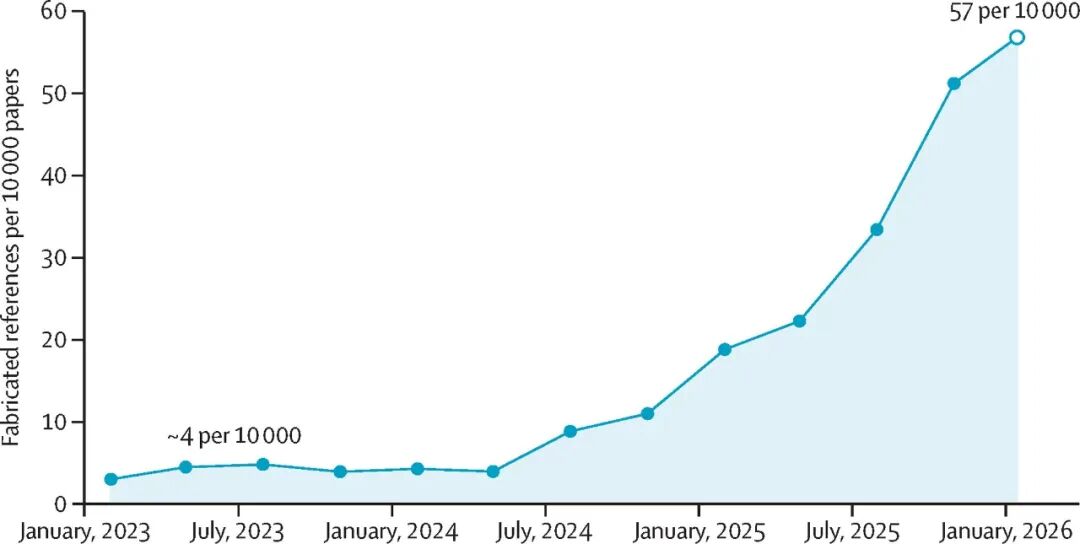
本来寻思按柳叶刀上通讯的思路,加上耿同学视频里思路,做一个审核工具,一搜之下,已经有好几个已经能用的开源打假工具。
于是做了一份整理:从数据取证到图片查重,从末位数字分布到本福特定律,这些工具可以做一轮筛查。
自动化引用验证系统
来自哥伦比亚大学护理学院与数据科学研究所开发了一套自动化引用验证系统。
扫描了 PubMed Central 开放获取子集中 2023 年 1 月至 2026 年 2 月间的约 250 万篇论文,涉及 1.26 亿条结构化参考文献。
检测流程设计得相当严谨。
系统对语料库中的每条参考文献,首先向 CrossRef 数据库发起查询。
CrossRef 维护着来自超过 2 万个出版商的 1.5 亿条学术作品元数据,包括作者姓名、期刊名称、卷号、期号和出版年份。
这些维度的数据会被交叉核对,只要有一条不匹配,引用就会被标记为可疑。
系统还会主动排除常见转录错误,比如 DOI 中数字位置调换、作者姓名轻微拼写变体等,只有在多次验证后仍无法找到匹配记录时,引用才最终被判定为虚假。
团队还对抽样的被标记引用进行了人工二次审核,由三位独立审稿人确认,以控制误报率。
结果令人震惊。
从 250 万篇论文中,审核结果确认了 4046 条虚假引用,涉及 2810 篇论文。
最急剧的加速拐点出现在 2024 年中期,这个时间点与 AI 写作助手从早期采用者工具转变为全球研究人员日常使用工具的时期完全吻合。
有一篇 2025 年发表在外科领域的开放获取肿瘤学期刊论文,30 条参考文献中有 18 条是虚构的,虚假率高达 60%。
不过这种验证机制也有盲区。
它主要覆盖 PubMed Central 的开放获取子集,对 JAMA、新英格兰医学杂志、柳叶刀本体等高影响力订阅期刊的代表性不足。
而且 DOI 级别的验证无法捕捉一种更狡猾的造假方式——嵌合引用。
所谓嵌合引用,就是 AI 混合了多篇真实论文的元素:第一作者确实在某期刊发表过文章,卷号期号也是真实的,但这篇具体论文根本不存在。
由于每个组件都可以单独验证通过,这类引用最难以被发现。
团队认为 12 倍的增长趋势可能来源于 AI 引用的三种常见幻觉类型:完全虚构引用(Phantom Citation)、嵌合引用(Chimera Citation)、损坏引用(Corrupted Citation)。
耿同学方法论
这个项目不是耿同学发布,是由 JasonYan-Bio 维护。
核心假设只有一句话:自然数据具有随机性,人为编造的数据会呈现不自然的规律性。
基于这个前提,它实现了六大检测模块。
第一个模块是末位数字检测。
自然实验数据的末位数字,0 到 9 的分布应该接近均匀,如果某些数字出现频率异常偏高或偏低,使用卡方检验就能判断偏离程度。
人为编造数据时,人脑无法真正生成随机数,末位数字的分布往往会有明显的偏好。
第二个模块是本福特定律检测。
对于跨越多数量级的自然数据,首位数字为 1 的概率约为 30.1%,而 9 的概率只有 4.6%。
如果数据严重偏离这个理论分布,就可能存在人为编造。
不过这个检测有条件限制:数据必须跨多个数量级,像百分比、特定量表分数这类受人为限制的范围就不适用。
第三个模块是 GRIM 测试(粒度相关均值不一致性检验)。
它的适用场景非常具体:对于整数取值的数据,比如 Likert 5 点量表,给定样本量 n 之后,合法的小数平均值只能落在特定的有限集合内。
如果论文报告的平均值在数学上根本不可能由整数样本产生,那这条数据就站不住脚。这是一种确定性检验,不依赖概率性判断。
第四个模块是固定关系检测。
两组独立实验的数据之间不应该存在恒定的差值、比值或线性关系。
如果你发现两组数据每一行的差值都精确等于同一个常数,或者在散点图上完美落在一条直线上,那就不是巧合能解释的了。
第五个模块是小数位一致性检测。
实验测量数据的小数点后数字应该具有随机性。如果多组数据的小数位后数字全部以 0 或 5 结尾,暗示存在人为修约甚至编造。
第六个模块是图像重复检测。
基于感知哈希和 SSIM 结构相似度算法,扫描论文中的图片是否存在重复使用或篡改。相似度超过 0.85 的阈值即被标记,典型应用包括 Western blot 条带重复使用、流式细胞图复用等。
综合评估引擎会把六个模块的结果汇总,生成一个 0 到 100 分的风险评分。
26 到 50 分是中风险,存在可疑模式,建议人工复核。
51 到 75 分是高风险,多项检测异常。76 到 100 分是极高风险,出现系统性异常,高度疑似数据造假。
输出内容包括异常检测的详细报告、风险评分、分布直方图和偏离热力图等可视化图表,以及建议进一步核查的具体数据点。
工具覆盖生物医学、化学、物理材料、社会科学和临床医学等多个领域,会根据领域自动选择适用的检测策略。
项目地址:https://github.com/JasonYan-Bio/geng-skills
从 PDF 到证据图片的完整审计链
相比于 geng-skills 更偏重数值维度的检测, research-integrity-auditor 则是一个用于论文科研诚信审查的技能Skill,更合适做发布之前的检验。
可以辅助审查论文 PDF、图表、实验数据和源数据表格中的异常线索:通过 MinerU 转换论文,自动构建可引用的证据台账,运行数字取证检查,并为高风险表格生成确定性的证据标注图。
它的目标不是直接“判定造假”,而是帮助你整理可复核的异常证据链:每条发现都应包含页码、图表编号、原始值、图片路径、Markdown 行号或内容块位置,并明确说明可能的善意解释和人工复核建议。
项目的设计思路是把论文审查变成一个可复现的工程流程,而不是依赖个人的主观判断。它明确了一条红线:不直接判定论文造假,不替代机构调查。
每条发现都是一个标记,附带位置信息、原始值和可能的善意解释,最终由人工来复核。
整个流程分为多个步骤。
第一步是用 MinerU 将论文 PDF 或公开论文 URL 转换为结构化数据。
MinerU 是一种基于 AI 的文档 OCR 解析服务,能把 PDF 中的文本、表格、图表和图片全部提取出来,生成 Markdown 格式的结构化全文。这一步需要配置 MinerU API Token。
第二步是构建证据台账。
脚本 build_evidence_ledger.py 从 MinerU 的输出中自动提取并索引所有证据单元,包括文本段落、表格数据、图表图片、标题信息、页码位置、边界框坐标、Markdown 行号、内容块定位,以及表格中每一行每一列的原始值。
这个台账后续所有的取证分析提供了精确的溯源能力。每当报告一个异常点时,都能追溯到这个异常来自哪个 PDF 的第几页、第几张图、第几个表格的哪个单元格。
第三步是运行数值取证。
脚本 numeric_forensics.py 对证据台账中的全部数值数据运行一系列确定性检查:精确重复值、重复的小数位、末位数字分布、取整度、本福特定律适用性分析以及简单的列间关系提示。
默认从表格中提取数据,避免参考文献年份等信息污染统计结果。
第四步是多 Agent 审查。
项目定义了九个专门审查角色,当子 Agent 可用时可以并行执行。
Image Forensics Agent 负责识别相同底图不同标签、相同实验主体不同信号等图片问题。
Data Duplication Agent 检测重复行列、固定偏移和轻微修改的副本。
Digit Pattern Agent 分析末位数字集中度、过于整齐的小数和可疑取整。
Math Consistency Agent 反推百分比与计数、检查不可能的四舍五入和固定公式关系。
Distribution Agent 比较数值曲线的形状和噪声纹理。
Domain Sanity Agent 从领域知识角度核查测量精度和实验合理性。
Defense Agent 为每个异常点构建最强的良性解释。
Judge Agent 合并证据、删除弱信号重复项、分配风险等级并生成最终报告。
第五步是生成标注证据图片。
当源数据审计 JSON 中包含固定差值发现或末位异常发现时,可以通过 render_evidence_tables.py 从原始 XLSX 文件生成带标注的 PNG 证据图片,每张图片都保留源文件、工作表名称、行列范围和风险备注等元信息。
最终报告以风险等级和最强证据链开头,然后按从强到弱的顺序列出所有发现,每条发现包含证据内容、使用的方法、为何可疑、可能的良性解释、压力测试结果、置信度和建议的人工验证步骤。
结尾单独列出局限性,包括 MinerU 提取质量、PDF 图片分辨率、样本量限制等。
项目地址:https://github.com/cylqwe7855-alt/research-integrity-auditor
paperconan:数据完整检测工具
这个项目名字比较有意思:“论文柯南“。
只需要把论文的 supplementary source data 文件夹指给它,也就是那一堆 xlsx、csv、tsv 文件,它会自动扫描并输出两个东西:一个是 scan.json,包含所有结构化命中记录,另一个是 report.html,一个自包含的可交互法证报告。
HTML 报告的交互性设计是一个亮点。
顶部有文件数、工作表数和高、中、低严重度命中数的摘要统计。左侧边栏可以按严重度、检测器类型或文件名勾选过滤,还支持关键字搜索。
主区域中每条发现是一个可折叠卡片,直接嵌入来源表格的片段,并且用黄色底色高亮可疑列,用红色边框标记可疑行。
如果命中项涉及末位数字卡方检验异常,卡片内会自带 0 到 9 的内联直方图,读者不需要离开页面就能直观看到分布偏差。
paperconan 内置了 13 个检测器。
identical_column 检测同一区块内两列是否完全一致。
constant_offset 检测同一区块内两列是否存在固定偏移,比如所有行的 B 列都恰好等于 A 列加 2.13。
constant_ratio 和 exact_linear 分别检测固定比例和精确线性关系。
arithmetic_progression 检测整列是否构成完美等差数列,一组对照组的 Y 值如果是完美的 1、2、3、4 整数序列,自然测量不可能产生这种结果。
在行内异常方面,within_col_value_duplication 检测单列内同一个 6 位以上小数值是否反复出现。
比如 0.208975 这个数字在声称独立的实验中出现了 8 次,概率太低。
within_col_decimal_repetition 检查同组 N 个数字的小数尾两位是否高度重复。
rounded_to_half_or_int 检测整列数据是否都被舍入到固定的刻度上,自然测量不会全部精确落在某个网格。
identical_after_rounding 则是发现两列数值在舍掉末位后完全一致的情况。
跨表检测方面,many_equal_pairs 检测两个本应独立的列中是否有超过 40% 的行完全相同。
cross_sheet_position_identical 检查两张工作表中同行同列位置的数值是否完全一样。
last_digit_chi_square 对整个工作表的末位数字做卡方检验,当 p 值低于 1e-6 时标记异常。
repeated_two_decimal_endings 专门检查末两位是否高度集中。
每条命中记录都带有严重度标记、涉及的文件名、工作表名、区块行号范围和具体的规则描述字符串,方便人工复核时直接定位到原始数据。
paperconan 还有一个自动抓取功能。
通过 paperconan fetch 命令,输入论文 DOI 就能列出候选数据集,支持直接从 Zenodo 和 Figshare 下载,Dryad 仅做检测。
项目还提供了一个 agent skill 入口,可以作为 Claude Code 或 Codex 等AI智能体的插件调用,包含了每个检测器的原理说明、典型命中模式和常见误报场景的参考文档。
项目地址:https://github.com/zixixr/paperconan
统计与机器学习的融合检测
这个项目把本福特定律的统计特性和单类支持向量机(OCSVM)的异常检测能力做了融合。
项目已经通过了大学生研究训练计划的国家级初评,说明在学术质量上有一定的背书。
核心检测策略分两条线。
本福特法则这条线提供统计学的理论依据和可解释性,当数据的首位数字分布偏离理论的对数规律时,就给出一个明确的偏离信号。
OCSVM 这条线则是一种单类分类算法,只需要用正常数据训练,就能识别出与训练分布显著不同的异常样本。
这个项目的独特之处就是引入了单类分类算法,单类支持向量机(One-Class SVM)是一种用于异常检测和异常值识别的机器学习算法。
它是一种无监督学习算法,专门设计用于处理只有一个类别的训练数据的情况,通常用于标记为“正常”或“不正常”的样本。
它能在不需要训练的情况下,找到论文中数据中异常的数据,而不是依据统计学的理论。
项目地址:https://github.com/solaire85/Benford-OCSVM-Detection-System88
综合以上四个开源项目的方法论,可以做一个完整的论文数据审计工具。
第一步是数据提取层。
从论文 PDF、补充材料的 CSV/XLSX/TSV 文件,以及论文中嵌入的图片中抽取所有可分析的原始数据。
这一步目前最好的方案是 MinerU OCR 配合 paperconan 的 fetch 机制,前者做文档解析,后者拉取 Zenodo 和 Figshare 上的公开数据。
第二步是多维度检测引擎。
目前可以整合的检测维度包括十三个。
数值维度有:末位数字卡方分布检测、本福特定律首位分布检测、GRIM 平均值兼容性检验、小数位一致性检测、取整度检测、固定差值固定比例关系检测、精确线性关系检测、等差数列检测、列内复现小数检测。
跨表维度有:同行同列数值一致性检测、列间高比例相同行检测。
图像维度有:感知哈希和 SSIM 图片相似度检测、多 Agent 图片身份与标签冲突审查。
机器学习维度有:OCSVM 一类支持向量机异常检测。
每条检测命中的异常点被赋予严重度等级,并记录溯源信息,包括来源文件、工作表名、行列位置、原始值、以及可能的高亮渲染图片。
这些信息汇总到一个结构化的证据台账中,可以按严重度、检测器类型或文件名过滤和搜索。
第三步是风险评估。
看证据之间的交叉验证关系。
如果只有某一个维度报警,可能是仪器校准或数据录入的问题。
但如果图片身份冲突同时叠加了机械数值模式和反推公式生成痕迹,且良性解释无法覆盖所有证据线,风险评分会显著升高。
geng-skills 的 0 到 100 分四级风险等级是比较成熟的量化方案,可以在此基础上扩展。
这样,把哥大的检测流程,结合四个开源项目的检测工具和方法,按上面的设计方案,综合成一个自动化线索发现的工具。
-END-
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-31,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号