猜一猜!DeepSeek V4 API调用接近20亿Tokens具体花费了多少钱?

猜一猜!DeepSeek V4 API调用接近20亿Tokens具体花费了多少钱?

Hello工控
发布于 2026-05-29 13:40:47
发布于 2026-05-29 13:40:47
最近一段时间为了优化我们RealPLC产品的各个细节,基本用了两个AI方案:
- Codex + GPT 5.5High
- ClaudeCode + DeepSeek V4 Pro/Flash
当然,Codex用的Plus方案,用完后就切第二套方案。我们这个月确实每天都在不断地调整。
这个过程最大的花费实际不是API费用和订阅费,按我的体感是自己的时间,因为一个问题的改动,可能会搞坏其他的地方。
每一次改动,docker重启至少要几分钟,反反复复,时间不顶用。期间,也有很多朋友反复问什么时候发内测邀请码,但是,实实在在快要等发布的时候,因为某个小地方不爽,改一改,发现优化无止境,总有更好的方案,甚至重写,这个过程耗费不少时间。
但是,通过不断的优化,我们近期的方案也基本不会大改,前端UI的内容基本不会增加太多,多的是后期服务端的管理和配置,这需要大量的工作。
所以,简单发个网站很简单,但是要稳定运行,背后的服务这些工作量不少了,所以看似简单,当代码数量上了一个量级的时候,就不那么容易了。
这期我们分享下用DeepSeek V4的费用,毫不夸张,这个月差不多耗费了20亿的Tokens,单单只是这个API的费用,GPT的额度每天都用完。所以,RealPLC生来就是AI的产物,也是我们和AI结合的综合体。
01

DeepSeek V4费用
我记得有一期简单的介绍:DeepSeek V4 Pro 1个亿Token,到底要花多少钱?
刚好差不多过去了一个月,今天刚好欠费了,所以翻开后台数据,这里和大家分享下我个人的使用具体情况。
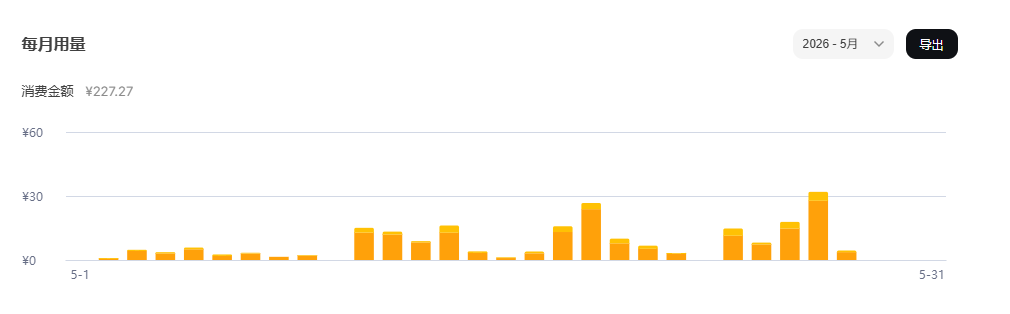
总消费:227.27元。具体分到模型上,这个图不明显,所以导出数据后,直接丢给DeepSeek网页端,让他做个html页面展示下,我们放到后面详细说明。
具体的Tokens可以看到:
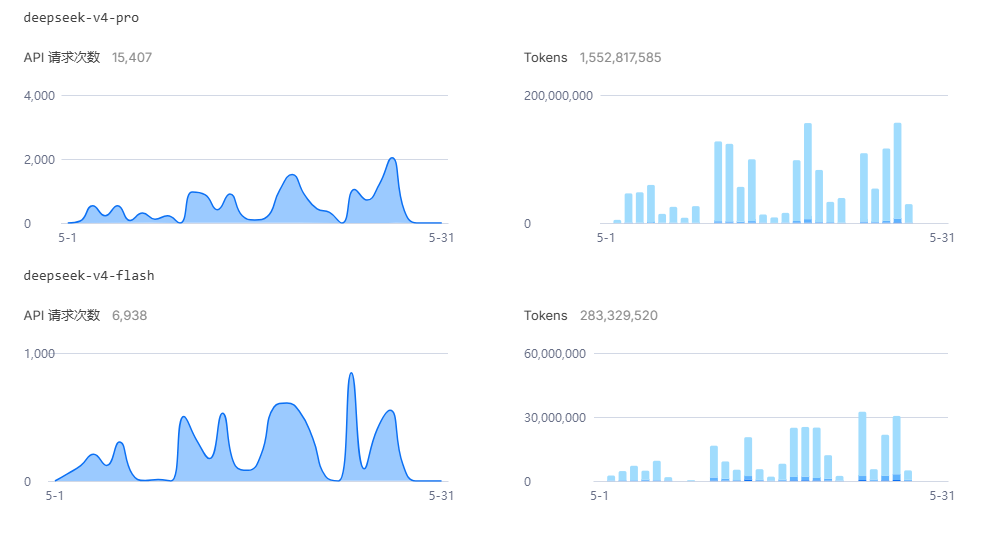
大部分用的是Pro,总体看:
Pro的Tokens:1552817585 约15亿多;
Flash的Tokens:283329520 约3亿多。
估计总体这个月差不多就是20亿的消耗。按照目前的金额粗算下(18亿 230元来计算),平均:1亿Tokens12元左右。
02
深度解析
我们让DeepSeek生成的html打开后,看到不错的页面:
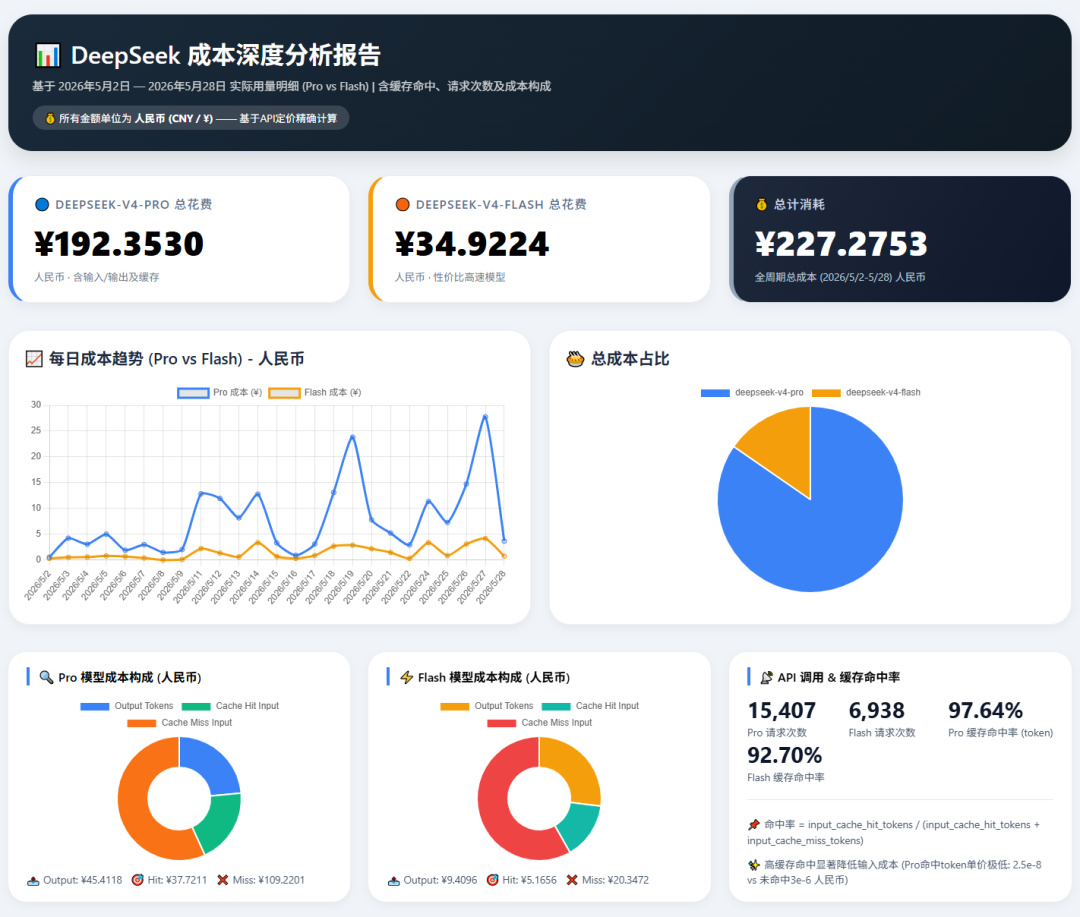
总成本概览
统计周期内,该账号(user_id: b5200252...)累计调用支出 ¥227.28元。
- deepseek-v4-pro(高精度模型):¥192.35元,占总成本的 84.6%。
- deepseek-v4-flash(高速轻量模型):¥34.93元,占总成本的 15.4%。
Pro 模型是绝对的成本主力,日均花费约 ¥8.74元;Flash 模型日均仅 ¥1.59元,适合对实时性要求高、但对成本敏感的任务。
成本构成分析(基于 Token 级明细)
Pro 模型成本构成:
- 输出 Token(¥0.000006/个):贡献 ¥43.52,占比 22.6%
- 缓存命中输入(¥0.000000025/个):贡献 ¥5.80,仅占 3.0%
- 缓存未命中输入(¥0.000003/个):贡献 ¥143.03,占比 74.4%
Flash 模型成本构成:
- 输出 Token(¥0.000002/个):贡献 ¥14.08,占比 40.3%
- 缓存命中输入(¥0.00000002/个):贡献 ¥0.92,仅占 2.6%
- 缓存未命中输入(¥0.000001/个):贡献 ¥19.93,占比 57.1%
关键发现:两种模型的成本大头均为 “缓存未命中输入 Token”,Pro 模型的未命中输入成本占比接近四分之三。如果能够进一步提升输入缓存命中率,Pro 的成本有大幅下降空间(命中后输入单价仅为未命中的 1/120)。
缓存命中率与调用频率
- Pro 模型:缓存命中率 = 93.5%(命中 Token 约 13.8 亿,未命中约 0.96 亿) 请求次数:13,809 次
- Flash 模型:缓存命中率 = 86.5%(命中 Token 约 2.57 亿,未命中约 0.40 亿) 请求次数:6,780 次
Pro 模型的请求次数是 Flash 的两倍多,且命中率更高,表明大量重复或相似的输入被有效缓存,降低了理论成本——但由于未命中输入的绝对量仍然巨大(0.96 亿 Token),总成本依然偏高。
每日成本趋势特点
- 平稳期(5月2日–9日):Pro 日成本 1~5 元,Flash <1 元。
- 爆发期(5月11日–27日):Pro 多次出现单日超过 12 元,最高 5月27日达 ¥27.76;Flash 最高单日 5月27日 ¥4.19。
- 5月19日 与 5月27日 是两个明显峰值,可能与业务活动增加或大量长上下文请求有关。
03
小结
看来要继续降低成本,还得提高输入的命中率。AI给的建议:
- 提高缓存复用:尽量复用相同的会话或系统提示词,减少
cache_miss输入量。当前未命中输入贡献了 Pro 约 74% 的成本,优化这部分可获得最大收益。 - 评估模型选择:对于非复杂推理任务,可多使用 Flash 模型。Flash 的成本仅为 Pro 的 1/5~1/6,且调用延迟更低。
- 控制输出长度:输出 Token 在两个模型中都占相当比例(Pro 23%,Flash 40%),适当限制
max_tokens或简化回答能直接节约成本。
参考链接:
【1】https://platform.deepseek.com/usage
【2】https://www.realplc.com
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号