新手必看!MySQL锁等待VS死锁:告别认知误区,别再被嘲讽!

新手必看!MySQL锁等待VS死锁:告别认知误区,别再被嘲讽!

俊才
发布于 2026-05-29 12:57:30
发布于 2026-05-29 12:57:30
线上MySQL锁异常是后端开发、运维工作中最常见的问题之一,同时也是认知误区最高的数据库问题。绝大多数开发者都会犯一个致命错误:把所有锁阻塞、SQL卡顿、锁超时问题,统统当成死锁处理,且招致别人嘲讽。
日常排查中,我们只会遇到两类锁冲突异常:
- 业务SQL长时间执行卡住,最终抛出锁等待超时异常Lock wait timeout exceeded; try restarting transaction,请求失败;
- 事务直接终止,报错Deadlock found when trying to get lock,触发事务回滚。
很多人默认将二者划等号,认为锁超时就是发生了死锁,排查时盲目翻看死锁日志、胡乱调整超时参数,最终不仅问题无法解决,还会延误线上故障定位。
实则二者有着本质区别:成因、运行表现、数据库处理机制、优化方案完全不通用。
- 锁等待:单向资源排队,属于正常锁竞争,具备自愈能力,仅超时后会失败
- 死锁:多事务循环互卡,属于恶性锁冲突,无自愈能力,必须引擎主动干预破解
一、InnoDB 行锁机制
我们日常遇到的锁等待、死锁问题,全部基于MySQL InnoDB引擎的行级排他锁,所有锁冲突的核心底层规则仅有一条:
事务A对某行数据执行UPDATE/DELETE操作并加排他锁后,在事务提交、锁释放前,其他事务无法修改该行数据,只能被动等待锁资源释放。
简言之,所有数据库锁冲突问题,本质都是多个事务争抢同一行数据资源引发的资源阻塞问题。
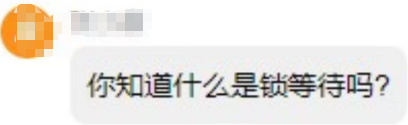
为方便后续实操复现,先创建统一测试表并初始化数据,可直接复制执行:
CREATE TABLE `user_account` (
`id` int PRIMARY KEY AUTO_INCREMENT,
`name` varchar(20) NOT NULL,
`balance` int NOT NULL DEFAULT 0
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 插入测试数据
INSERT INTO user_account(name,balance) VALUES ('张三',1000),('李四',1000);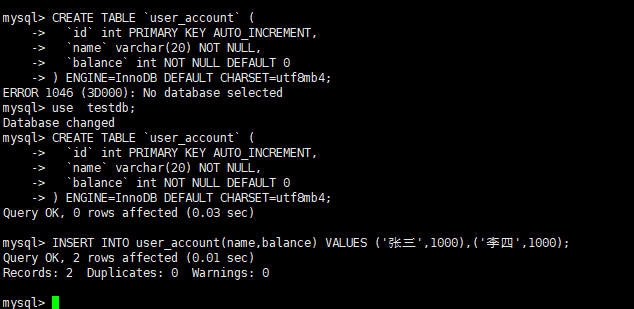
二、锁等待:单向排队的正常资源阻塞
1. 通俗理解
锁等待的本质:单一方向的锁资源排队等待。用生活场景通俗类比就是:单行道马路中,前车停靠占用道路(事务持有锁且未释放),后方所有车辆只能原地排队等候。只要前车驶离(事务提交、释放锁资源),后方车辆即可正常通行,全程无死局、无僵持。
核心特征就是:单向等待、无循环依赖。
2. 完整复现案例
打开两个独立的MySQL会话窗口,严格按照如下步骤执行操作,复现锁等待场景:
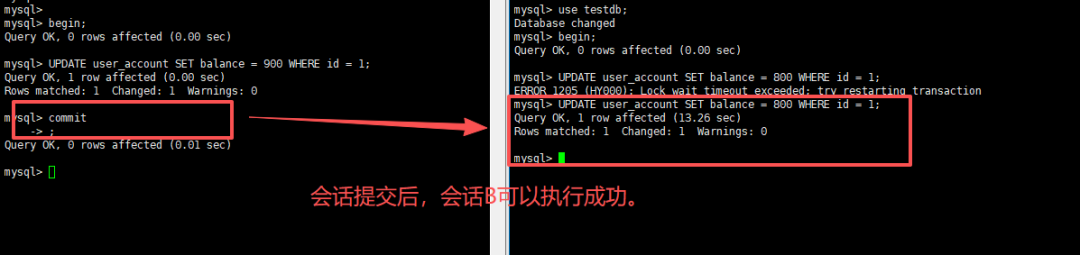
会话A(优先执行,持有行锁)
BEGIN;
-- 锁定 id=1 数据行,事务不提交,锁资源持续占用
UPDATE user_account SET balance = 900 WHERE id = 1;执行完成后,不提交事务、不关闭会话,此时会话A已永久持有id=1行的排他锁,不会主动释放。
会话B(后续执行,争抢锁资源)
BEGIN;
-- 尝试修改被会话A锁定的行,触发锁等待
UPDATE user_account SET balance = 800 WHERE id = 1;执行后可明显观察到:会话B的SQL语句无报错、无执行结果,持续卡住,进入典型的锁等待状态。

3. 锁等待两种结局:自愈成功 / 超时失败
结局1:等待超时(线上高频常见场景)
若会话A长期不提交事务、不释放锁,会话B会持续等待,直至触发超时机制,抛出经典异常:
Lock wait timeout exceeded; try restarting transaction
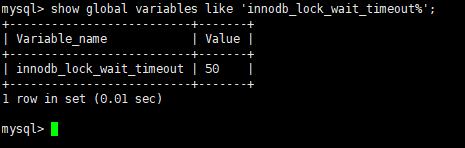
MySQL锁等待默认超时时间为50秒,可通过 innodb_lock_wait_timeout 参数自定义按需配置。
结局2:自动自愈(正常场景)
在会话A中执行COMMIT;提交事务、释放锁资源。锁释放瞬间,会话B卡住的SQL会立即执行成功,排队阻塞结束,无任何异常,业务正常流转。
4. 锁等待核心特征总结
- 等待关系:单向等待,仅后序事务等待前置事务,无互相等待场景
- 阻塞状态:不会永久阻塞数据库,仅单条请求卡住,最终要么自愈成功,要么超时失败
- 处理机制:无需人工干预,MySQL自动触发超时回收机制,释放阻塞请求
- 高频成因:长事务未及时提交、热点行高并发更新、事务内业务逻辑耗时过长
三、死锁:双向闭环的无解锁死局
1. 通俗理解
死锁的本质:多事务互相持有资源、互相等待的闭环死循环。
继续沿用生活类比:两条单行道十字交汇,A车占用B车必经道路,B车同时占用A车必经道路。双方均持有对方必需的资源,且都不释放自身已占用资源,最终双向僵持、谁也无法通行,形成永久无解死局。
核心特征总结:循环等待、双向资源依赖、无自愈能力、属于致命锁异常。
2. 完整复现案例
依旧使用两个MySQL会话,必须严格遵循以下时间顺序执行,缺一无法复现死锁场景:
第一步:会话A执行,锁定id=1行,不提交事务
BEGIN;
UPDATE user_account SET balance = 900 WHERE id = 1;第二步:会话B执行,锁定id=2行,不提交事务
BEGIN;
UPDATE user_account SET balance = 900 WHERE id = 2;第三步:会话A继续执行,尝试获取会话B的锁资源
UPDATE user_account SET balance = 800 WHERE id = 2;此时会话A陷入卡住状态,持续等待会话B释放id=2的行锁。
第四步:会话B继续执行,尝试获取会话A的锁资源,触发死锁
UPDATE user_account SET balance = 800 WHERE id = 1;关键区别:此时不会长时间卡住,而是瞬间触发死锁机制,直接抛出异常、回滚事务:
Deadlock found when trying to get lock; try restarting transaction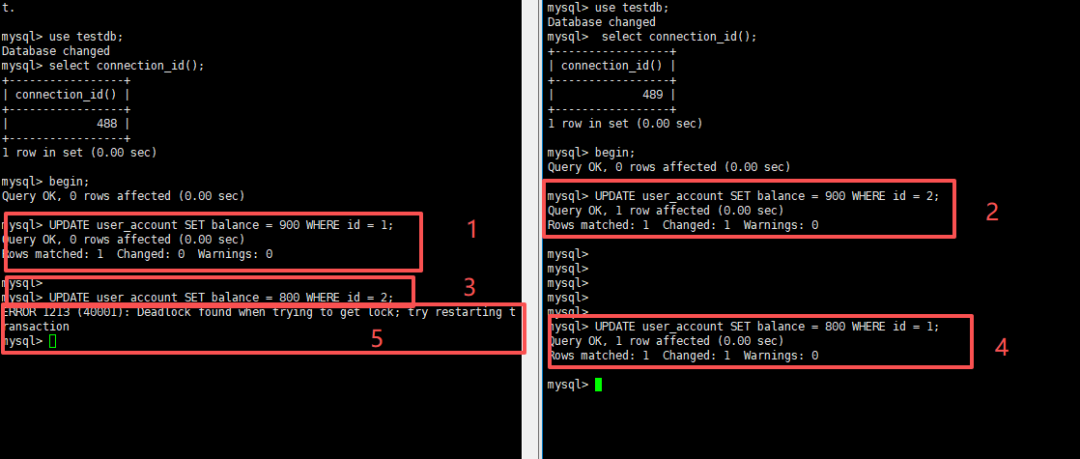
3. 死锁底层核心逻辑
上述操作会形成完整的事务循环等待链,这是死锁的核心成因:
- 事务A:已持有id=1行锁,等待获取事务B持有的id=2行锁
- 事务B:已持有id=2行锁,等待获取事务A持有的id=1行锁
两个事务资源互斥、需求互斥,无任何一方主动释放资源,形成数据库无法自行化解的死局。
这里解答大家的核心疑问:为什么锁等待需要等50秒超时,死锁却能瞬间报错?
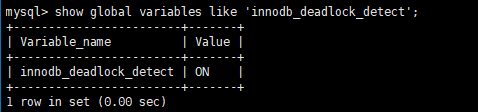
因为InnoDB引擎内置死锁实时检测机制,会持续扫描所有事务的资源等待链路。参数为innodb_deadlock_detect(默认开启),一旦识别到循环依赖的死锁场景,会立即回滚执行代价最小的事务,主动打破死局,避免数据库资源永久占用、服务阻塞。
4. 死锁发生的4个必要条件(缺一不可)
死锁不会随机触发,必须同时满足以下四个条件,日常优化可针对性打破任意条件,即可规避死锁:
- 互斥条件:同一锁资源,同一时间仅能被一个事务独占持有
- 持有并等待条件:事务已持有部分锁资源,同时主动等待其他未获取的锁资源(且等待的事务未达到锁等待超时时间)
- 不可剥夺条件:已被持有的锁资源,无法被其他事务强制抢占,仅能由持有者主动释放
- 循环等待条件:多个事务之间形成闭环的资源等待链路
四、锁等待与死锁对比
对比维度 | 锁等待 | 死锁 |
|---|---|---|
等待关系 | 单向等待(仅B事务等待A事务) | 循环双向等待(A、B事务互相等待) |
触发与报错速度 | SQL长时间卡住,默认50秒后超时报错 | 实时检测,瞬间识别死锁并立即报错回滚 |
自愈能力 | 具备自愈能力,锁释放后可正常执行 | 无自愈能力,必须引擎主动回滚打破死局 |
核心报错信息 | Lock wait timeout exceeded | Deadlock found when trying to get lock |
核心成因 | 正常锁竞争、长事务阻塞、热点行并发争抢 | 多事务数据更新顺序混乱,形成循环等待 |
问题严重程度 | 较轻,仅影响单条阻塞请求,无批量事务回滚 | 较高,触发事务回滚,可能引发数据一致性问题 |
五、锁问题排查及根治优化方案
1. 线上锁问题快速排查命令
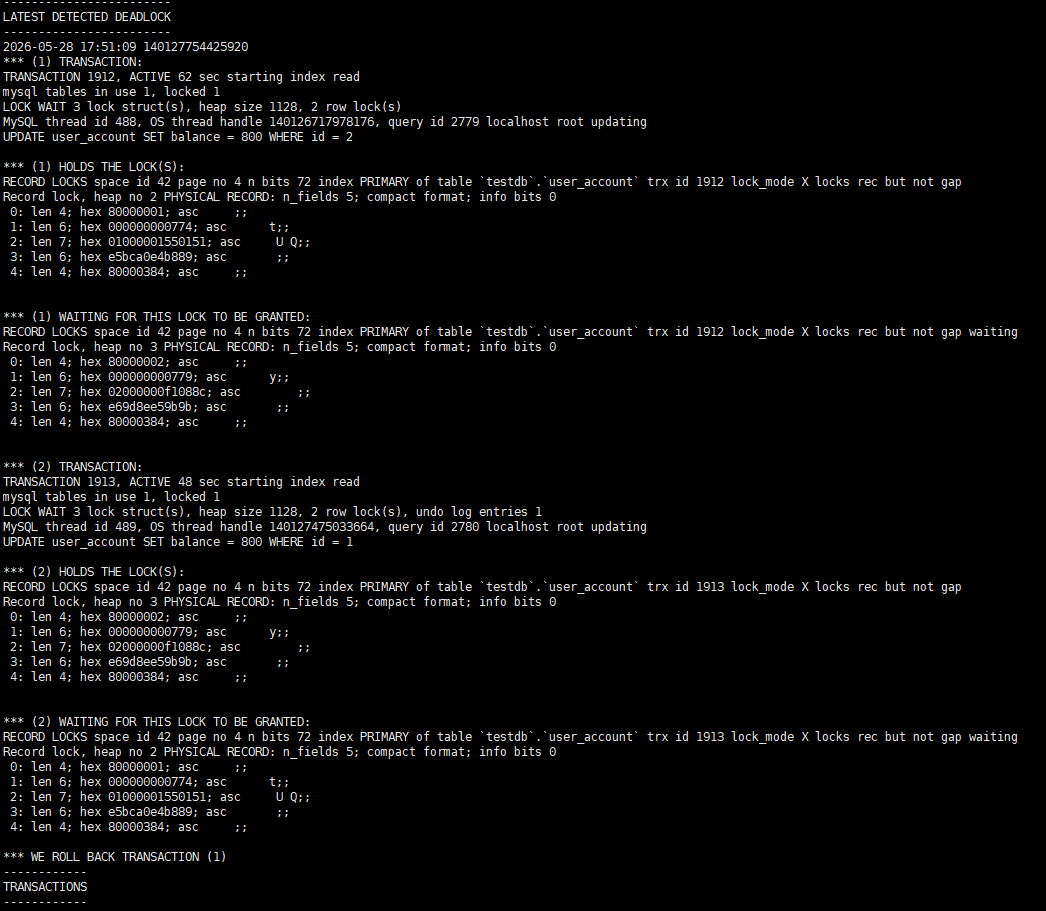
线上出现锁阻塞、死锁异常时,可通过以下命令快速定位问题根源:
SHOW ENGINE INNODB STATUS\G执行后在输出结果中找到LATEST DETECTED DEADLOCK模块,可查看最近一次死锁的完整事务执行链路、锁资源争抢明细、问题SQL,实现精准定位。
生产环境可以永久开启innodb_print_all_deadlocks=ON参数,将所有死锁日志持久化保存,方便后续故障回溯、问题复盘,但需注意日志量。可以通过自己写脚本记录的方式来记录死锁信息,需要的可以联系我获取脚本。
2. 锁等待优化根治方案
锁等待的核心优化思路是:缩短锁持有时间、减少锁竞争概率,具体落地措施:
- 杜绝长事务:事务做到即开即闭,禁止在事务内执行远程调用、文件读写、复杂业务计算等耗时操作
- 优化热点行竞争:拆分高并发更新的热点数据行,避免大量请求同时争抢同一行资源
- 保障SQL索引有效性:所有更新、删除语句必须走精准索引,避免行锁升级为表锁,扩大阻塞范围、加剧锁竞争
3. 死锁根治核心方案
线上99%的死锁问题,根源都是多事务更新数据资源的顺序混乱。根治死锁只需遵循一条核心准则:
- 系统内所有事务,统一按照固定顺序更新数据资源:例如转账、扣库存、数据更新等场景,统一约定优先更新ID较小的数据行,再更新ID较大的数据行,从根源打破“循环等待”必要条件,彻底杜绝死锁
- 辅助优化手段:拆分复杂大事务为多个小事务,减少单个事务持有锁的数量和时长,大幅降低锁冲突、死锁触发概率
六、总结
锁等待就像单向排队堵车,正常锁竞争,可自愈、超时失败,优化长事务即可解决;而死锁是双向闭环死局,恶性锁冲突,无自愈、必回滚,统一更新顺序即可根治。
线上排查快速判定技巧:
- 报错含timeout关键字是锁等待问题,重点优化长事务、减少热点阻塞
- 报错含deadlock关键字则是死锁问题,重点统一SQL更新顺序、精简事务
这就是锁等待与死锁的区别,大家都理解了吧。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号