Hermes Agent 工具系统实战解析:40+ 工具为什么不用配置表?
原创
Hermes Agent 工具系统实战解析:40+ 工具为什么不用配置表?
原创
运维有术
发布于 2026-05-24 11:09:33
发布于 2026-05-24 11:09:33
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 120 篇,Hermes Agent 最佳实战「2026」系列第 3 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。
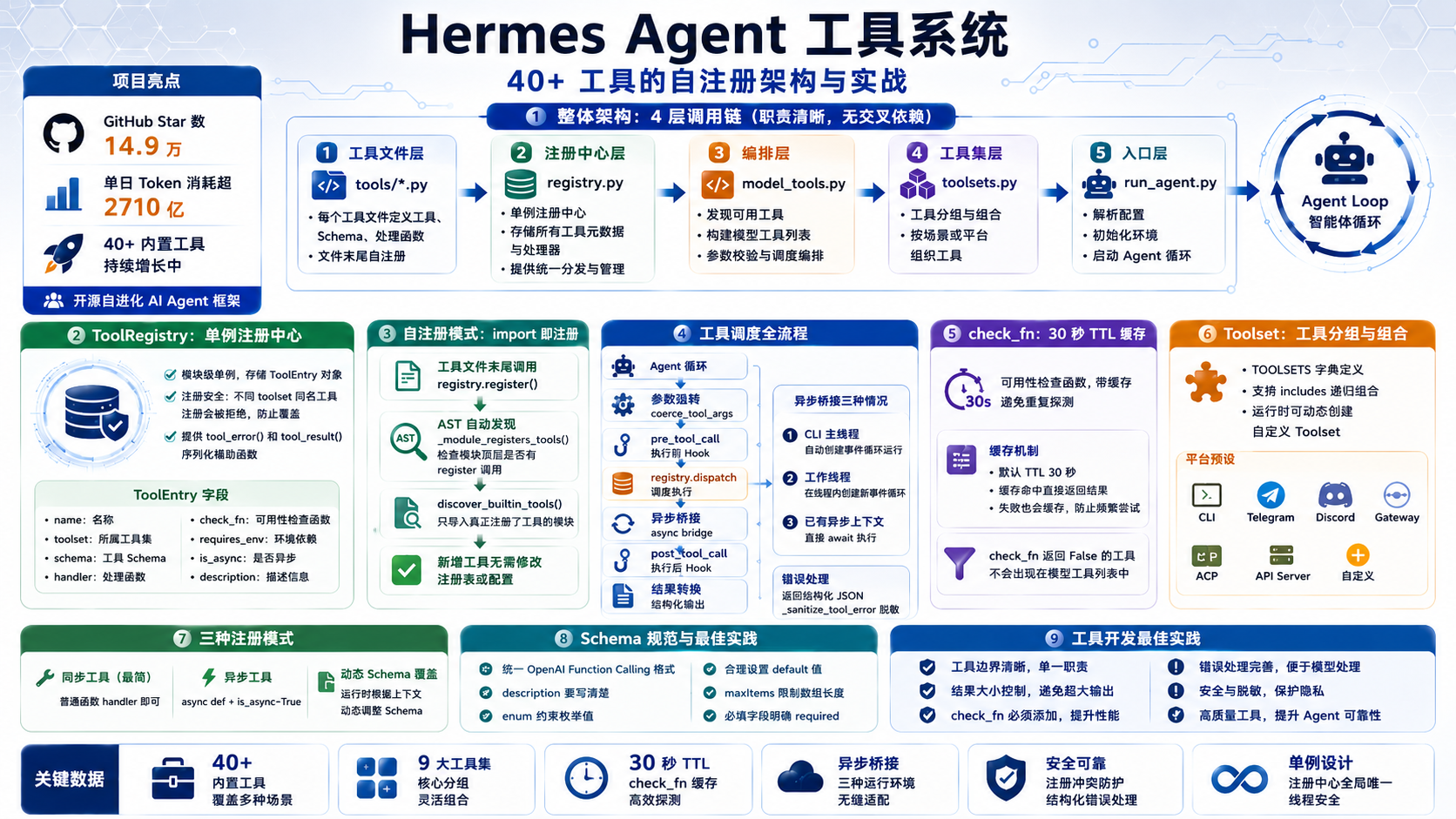
封面图 - Hermes Agent 工具系统架构示意图
图 1:Hermes Agent 工具系统全景
GitHub 上一个不到一年的项目,Star 数冲到了 14.9 万。2026 年 5 月 9 日,它的单日 Token 消耗超过 2710 亿,在 OpenRouter 排行榜上首次登顶。
这是 Hermes Agent - Nous Research 开源的自进化 AI Agent 框架。翻了一圈源码和社区讨论,我发现它工具系统的设计相当值得琢磨:一个单例注册表、AST 分析自动发现、import 即注册的机制,把 40+ 内置工具管理得井井有条。
说明:本文内容基于 Hermes Agent 源码(NousResearch/hermes-agent)和官方文档分析整理而成,源码分析基于笔者本地仓库版本。文中的配置模板和参数建议仅供参考,实际效果请以你的业务数据和环境测试结果为准。如果有实际使用经验,欢迎在评论区分享交流。
这篇文章就拆解一下它的 Tools & Toolsets 系统,看看这套架构到底怎么运作的。
1. 整体架构:4 层调用链
Hermes Agent 的工具系统分成 4 层,每一层职责清晰:
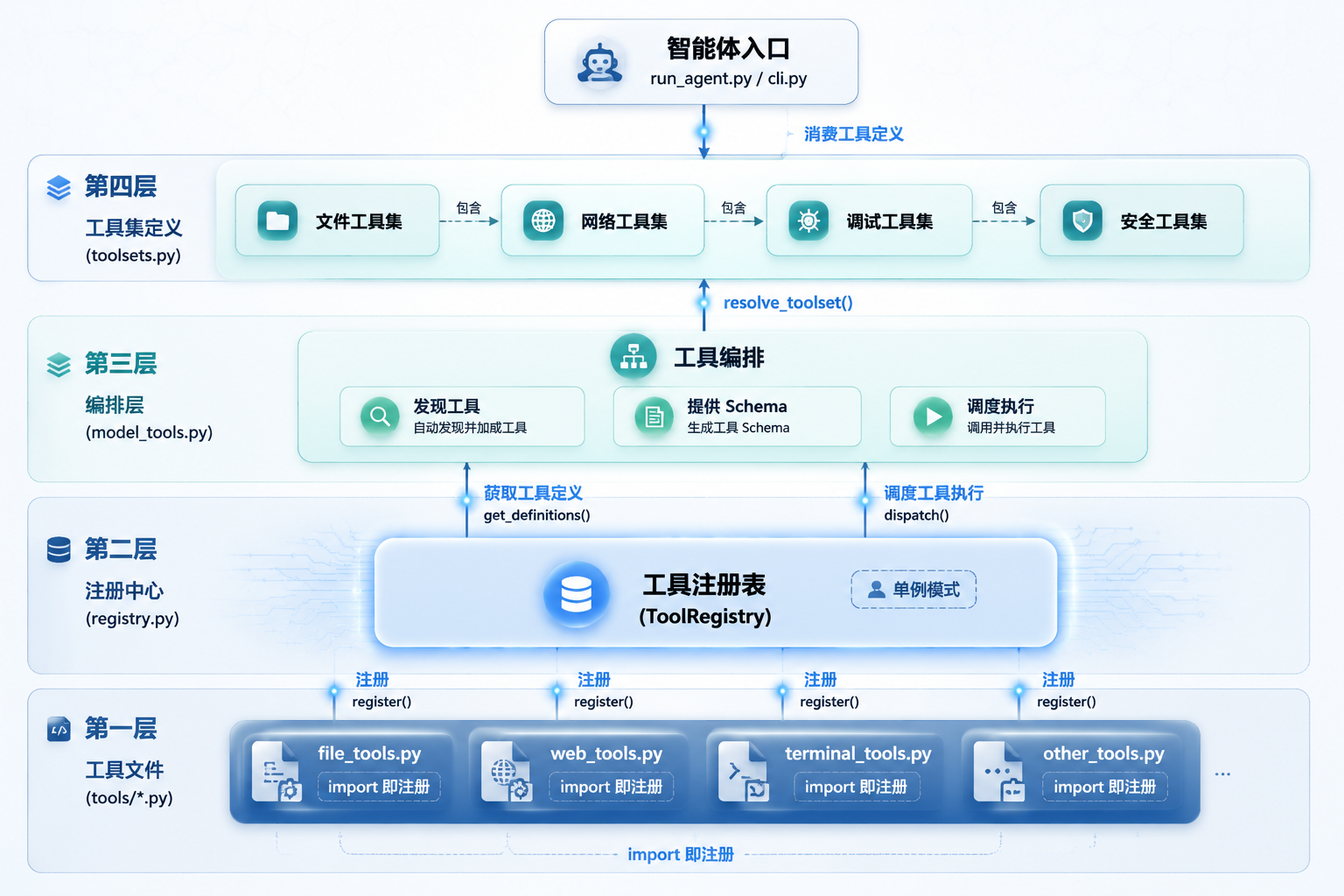
4 层架构图
图 2:Hermes Agent 工具系统 4 层架构
tools/*.py ← 各工具文件(模块导入时自注册)
↓ register()
tools/registry.py ← 单例注册中心(ToolRegistry)
↓ get_definitions() / dispatch()
model_tools.py ← 编排层(发现 + Schema 提供 + 调度)
↓ resolve_toolset()
toolsets.py ← Toolset 定义(工具分组、组合)
↓
run_agent.py/cli.py ← 入口(消费工具定义,驱动 Agent Loop)这 4 层各管各的。tools/*.py 只管注册自己,registry.py 只管存取,model_tools.py 做编排调度,toolsets.py 负责分组组合。没有交叉依赖,也没有上帝类。
2. ToolRegistry:一个单例管所有工具
2.1 核心数据结构
tools/registry.py 是整个工具系统的中枢。核心类 ToolRegistry,模块级单例:
# 模块级单例
registry = ToolRegistry()每个工具注册进来,存的是 ToolEntry 对象。源码里的定义:
class ToolEntry:
__slots__ = (
"name", "toolset", "schema", "handler", "check_fn",
"requires_env", "is_async", "description", "emoji",
"max_result_size_chars", "dynamic_schema_overrides",
)每个字段干什么用:
字段 | 用途 |
|---|---|
| 工具名,全局唯一标识 |
| 所属工具集(如 |
| OpenAI Function Calling 格式的 JSON Schema |
| 处理函数,同步或异步 |
| 可用性检查函数,带 30s TTL 缓存 |
| 所需环境变量列表 |
| 是否异步处理器 |
| 返回结果字符上限,防止上下文溢出 |
| 运行时动态覆盖 Schema 的回调 |
2.2 注册安全机制
register() 方法有一套防护逻辑,源码里写得很清楚:
def register(self, name, toolset, schema, handler, ..., override=False):
existing = self._tools.get(name)
if existing and existing.toolset != toolset:
# MCP-to-MCP 允许覆盖(服务器刷新场景)
both_mcp = (existing.toolset.startswith("mcp-")
and toolset.startswith("mcp-"))
if both_mcp:
pass # 允许
elif override:
pass # 显式允许(插件场景)
else:
# 拒绝 - 防止意外覆盖内置工具
logger.error("Tool registration REJECTED: ...")
return说白了就是:不同 toolset 的同名工具注册会被拒绝。除非你是 MCP 工具刷新,或者显式传了 override=True。这个设计防止了插件或 MCP 服务器不小心覆盖内置工具。
2.3 两个辅助函数
源码里还提供了 tool_error() 和 tool_result() 两个序列化辅助函数,省得每个 handler 都手写 json.dumps():
def tool_error(message, **extra) -> str:
result = {"error": str(message)}
if extra:
result.update(extra)
return json.dumps(result, ensure_ascii=False)
def tool_result(data=None, **kwargs) -> str:
if data is not None:
return json.dumps(data, ensure_ascii=False)
return json.dumps(kwargs, ensure_ascii=False)用起来很简洁:return tool_error("file not found") 或者 return tool_result({"content": text})。
3. 自注册模式:import 即注册
这是 Hermes 工具系统里面很有意思的设计。
3.1 模块级注册
每个工具文件在模块末尾直接调用 registry.register()。模块被 import 的时候,Python 执行模块级代码,注册就自动完成了。
拿 tools/file_tools.py 举例(源码末尾,第 1169-1172 行):
from tools.registry import registry, tool_error
registry.register(name="read_file", toolset="file", schema=READ_FILE_SCHEMA,
handler=_handle_read_file, check_fn=_check_file_reqs,
emoji="📖", max_result_size_chars=100_000)
registry.register(name="write_file", toolset="file", schema=WRITE_FILE_SCHEMA,
handler=_handle_write_file, check_fn=_check_file_reqs,
emoji="✍️", max_result_size_chars=100_000)
registry.register(name="patch", toolset="file", schema=PATCH_SCHEMA,
handler=_handle_patch, check_fn=_check_file_reqs,
emoji="🔧", max_result_size_chars=100_000)
registry.register(name="search_files", toolset="file", schema=SEARCH_FILES_SCHEMA,
handler=_handle_search_files, check_fn=_check_file_reqs,
emoji="🔎", max_result_size_chars=100_000)四个文件操作工具,四行注册代码。没有任何装饰器、没有继承、没有配置文件。直来直去。
3.2 AST 分析 + 动态导入
但问题来了:谁来 import 这些文件?
答案在 discover_builtin_tools() 函数里。它不是无条件 import 所有 .py 文件,而是先用 AST 分析,只导入真正注册了工具的模块:
def discover_builtin_tools(tools_dir=None):
tools_path = Path(tools_dir) or Path(__file__).resolve().parent
module_names = [
f"tools.{path.stem}"
for path in sorted(tools_path.glob("*.py"))
if path.name not in {"__init__.py", "registry.py", "mcp_tool.py"}
and _module_registers_tools(path) # AST 分析
]
for mod_name in module_names:
importlib.import_module(mod_name) # 触发自注册_module_registers_tools() 的判断逻辑:解析 .py 文件的 AST,检查模块顶层是否存在 registry.register(...) 调用。只看模块顶层,不深入函数体 - 这样辅助模块不会被误识别。
这个设计有一个好处:新增工具文件完全不需要修改任何注册表或配置。只要文件里有 registry.register() 调用,它就会被自动发现和注册。
4. 工具调度全流程
从模型发起 Function Call 到拿到结果,中间经历了这些步骤:
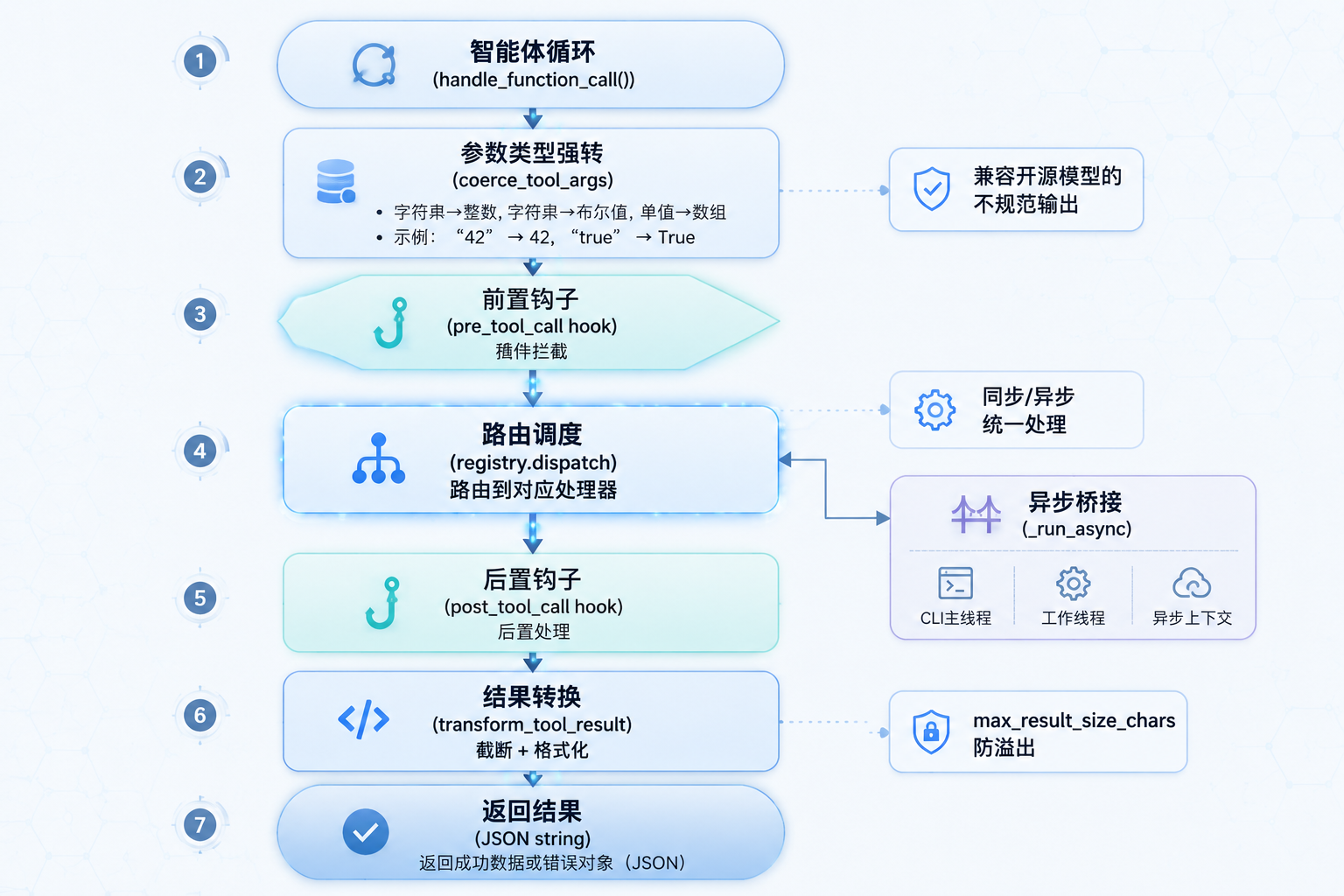
工具调度流程图
图 3:Hermes Agent 工具调度全流程
Agent Loop → handle_function_call()
↓
coerce_tool_args() # 参数类型强转
↓
pre_tool_call hook # 插件拦截
↓
registry.dispatch() # 路由到处理器
↓
async bridge (_run_async) # 异步桥接(如果需要)
↓
post_tool_call hook # 后置处理
↓
transform_tool_result # 结果转换
↓
返回 JSON 字符串4.1 参数类型强转
LLM 返回的参数类型经常和 Schema 对不上。比如 Schema 声明 integer,模型返回字符串 "42"。coerce_tool_args() 处理这些常见不匹配:
"42"→42(string → integer)"true"→True(string → boolean)"https://a.com"→["https://a.com"](bare value → array,当 Schema 期望 array)- JSON 字符串
"['a','b']"→['a', 'b'](解析嵌套结构)
还支持 union type 和 nullable。源码注释里写得很直接:Open-weight models (DeepSeek, Qwen, GLM) sometimes emit {"urls": "https://a.com"} when the tool expects {"urls": ["https://a.com"]}。
4.2 异步桥接
_run_async() 是同步上下文里跑异步工具的关键。源码里分了三种情况:
- CLI 主线程:用持久化事件循环(避免
asyncio.run()反复创建/销毁循环导致 "Event loop is closed" 错误) - 工作线程(如 delegate_task 的线程池):每线程一个持久化循环
- 已有异步上下文(如 gateway):新建独立线程运行,带 300s 超时保护
这个设计解决了一个实际问题:缓存的 httpx/AsyncOpenAI 客户端绑定在事件循环上,循环一关,GC 清理时就会报错。持久化循环让客户端一直有效。
4.3 错误处理
工具执行出错不会抛异常,而是返回结构化错误 JSON。registry.dispatch() 里的逻辑:
try:
if entry.is_async:
return _run_async(entry.handler(args, **kwargs))
return entry.handler(args, **kwargs)
except Exception as e:
raw = f"Tool execution failed: {type(e).__name__}: {e}"
sanitized = _sanitize_tool_error(raw) # 脱敏处理
return json.dumps({"error": sanitized})_sanitize_tool_error() 会剥离结构性 framing token(XML 标签、CDATA、代码围栏),防止错误信息里的特殊内容干扰模型的上下文理解。这个细节说明 Hermes 团队在安全上花了不少心思。
5. check_fn:可用性检查的 30 秒缓存
有些工具依赖外部状态。比如终端工具需要检查 Docker daemon 是否在跑,浏览器工具需要 Playwright 二进制文件,web 工具需要 API Key。
check_fn 就是干这个的 - 一个零参函数,返回 bool:
def check_vision_requirements():
"""检查视觉分析所需依赖"""
try:
import some_vision_lib
return True
except ImportError:
return False但每次调用都去探测外部状态很浪费。所以 Hermes 加了 30s TTL 缓存:
_CHECK_FN_TTL_SECONDS = 30.0
_check_fn_cache: Dict[Callable, tuple[float, bool]] = {}
def _check_fn_cached(fn):
now = time.monotonic()
cached = _check_fn_cache.get(fn)
if cached and (now - cached[0]) < _CHECK_FN_TTL_SECONDS:
return cached[1] # 命中缓存
try:
value = bool(fn())
except Exception:
value = False # 异常 = 不可用
_check_fn_cache[fn] = (now, value)
return value30 秒的 TTL 选择也有讲究 - 用户通过 hermes tools enable 改配置,大概 30 秒内生效。太短浪费资源,太长用户体验差。
get_definitions() 返回 Schema 的时候会过滤:check_fn 返回 False 的工具不会出现在给模型的工具列表里。这样模型就不会调用一个实际不可用的工具。
6. Toolset:工具分组与组合
6.1 基本结构
toolsets.py 里的 TOOLSETS 字典定义了所有工具集。每个工具集包含 tools(直接包含的工具名)和 includes(组合的其他工具集):
TOOLSETS = {
"web": {
"description": "Web research and content extraction tools",
"tools": ["web_search", "web_extract"],
"includes": []
},
"debugging": {
"description": "Debugging and troubleshooting toolkit",
"tools": ["terminal", "process"],
"includes": ["web", "file"] # 组合其他 toolset
},
"safe": {
"description": "Safe toolkit without terminal access",
"tools": [],
"includes": ["web", "vision", "image_gen"] # 纯组合,无直接工具
},
}includes 支持递归解析和钻石依赖(去重)。比如 hermes-gateway 包含了所有平台工具集,各平台又都包含核心工具列表,但最终解析出来不会重复。
6.2 平台预设
源码里有一个 _HERMES_CORE_TOOLS 列表,70+ 个核心工具名,各平台共享:
平台 Toolset | 说明 |
|---|---|
| CLI 完整工具集 |
| 各消息平台工具集 |
| 网关工具集(组合所有平台) |
| 编辑器集成(VS Code、Zed) |
| OpenAI 兼容 API |
每个平台预设的核心工具列表一样,区别在于各平台可能追加自己的专属工具。比如 hermes-discord 追加了 discord 和 discord_admin 工具,hermes-feishu 追加了飞书文档相关工具。
6.3 运行时创建自定义 Toolset
create_custom_toolset() 允许在运行时动态创建工具集:
from toolsets import create_custom_toolset
create_custom_toolset(
name="my_workflow",
description="Custom workflow toolset",
tools=["my_tool", "web_search"],
includes=["file"] # 组合 file toolset
)创建后和其他静态定义的 Toolset 完全等价。
7. 三种工具注册模式:源码实战
7.1 同步工具(最简模式)
以 read_file 为例,来自 tools/file_tools.py:
from tools.registry import registry, tool_error
READ_FILE_SCHEMA = {
"name": "read_file",
"description": "Read file contents...",
"parameters": {
"type": "object",
"properties": {
"path": {"type": "string", "description": "File path to read"},
"offset": {"type": "integer", "description": "Starting line number", "default": 1},
"limit": {"type": "integer", "description": "Max lines to return", "default": 500},
},
"required": ["path"]
}
}
def _handle_read_file(args, **kw):
tid = kw.get("task_id") or "default"
return read_file_tool(
path=args.get("path", ""),
offset=args.get("offset", 1),
limit=args.get("limit", 500),
task_id=tid
)
registry.register(
name="read_file",
toolset="file",
schema=READ_FILE_SCHEMA,
handler=_handle_read_file,
check_fn=_check_file_reqs,
emoji="📖",
max_result_size_chars=100_000,
)要点:handler 接收 args 字典和 **kwargs(task_id 等上下文信息),返回 JSON 字符串。
7.2 异步工具
web_extract 是异步工具的代表,来自 tools/web_tools.py:
registry.register(
name="web_extract",
toolset="web",
schema=WEB_EXTRACT_SCHEMA,
handler=lambda args, **kw: web_extract_tool(
args.get("urls", [])[:5] if isinstance(args.get("urls"), list) else [],
"markdown"),
check_fn=check_web_api_key,
requires_env=_web_requires_env(),
is_async=True, # 标记为异步
emoji="📄",
max_result_size_chars=100_000,
)唯一区别就是 is_async=True。框架的 _run_async() 会自动处理同步/异步桥接,handler 本身不需要关心调用上下文。
7.3 动态 Schema 覆盖
delegate_task 的 Schema 需要根据运行时配置动态调整(比如最大并发子 Agent 数)。源码里的做法:
def _build_dynamic_schema_overrides() -> dict:
"""每次 get_definitions() 调用时执行,返回要覆盖的 Schema 字段"""
overrides_params = {**DELEGATE_TASK_SCHEMA["parameters"]}
overrides_params["properties"] = {
k: dict(v) for k, v in
DELEGATE_TASK_SCHEMA["parameters"]["properties"].items()
}
overrides_params["properties"]["tasks"]["description"] = (
_build_tasks_param_description() # 读取当前配置
)
return {
"description": _build_top_level_description(),
"parameters": overrides_params,
}
registry.register(
name="delegate_task",
...,
dynamic_schema_overrides=_build_dynamic_schema_overrides,
)dynamic_schema_overrides 是一个零参回调,在 get_definitions() 被调用时执行。返回的字典会浅合并到原始 Schema 上。这样模型看到的工具描述始终和当前配置一致。
8. Schema 设计规范
翻看源码中的 Schema 定义,有几个值得注意的规范:
8.1 Schema 结构
统一遵循 OpenAI Function Calling 格式:
{
"name": "search_files",
"description": "Search file contents or find files by name...",
"parameters": {
"type": "object",
"properties": {
"pattern": {"type": "string", "description": "Regex pattern..."},
"target": {
"type": "string",
"enum": ["content", "files"],
"default": "content"
},
"limit": {"type": "integer", "default": 50},
},
"required": ["pattern"]
}
}8.2 设计要点
从源码的 Schema 定义中可以提炼出几个原则:
description 要写清楚。search_files 的 description 足有 3 行,解释了两种搜索模式和各自的行为。模型靠这个描述决定什么时候调用工具、传什么参数。
enum 约束枚举值。target 参数用 enum: ["content", "files"] 而不是自由文本,减少模型误调用。
合理设置 default。limit 的 default 是 50,不是无限制返回。offset 的 default 是 0。这些默认值在模型没指定参数时生效。
maxItems 限制数组长度。web_extract 的 urls 参数设置了 maxItems: 5,防止模型一次传太多 URL。
9. 最佳实践
基于源码分析和社区反馈,总结几条实践建议:
9.1 工具边界设计
一个工具做一件事。源码里 read_file、write_file、patch、search_files 是四个独立工具,而不是一个 file_operation 工具带 action 参数。这样 Schema 更清晰,模型的调用准确率更高。
9.2 结果大小控制
设置 max_result_size_chars。file_tools.py 里设的是 100,000 字符(约 25-35K tokens)。没有这个限制,一个工具返回的结果可能直接撑爆上下文窗口。社区反馈中"上下文窗口溢出"是高频问题,合理控制返回大小是关键。
9.3 错误处理模式
用 tool_error() 返回结构化错误,不要抛异常。源码里每个 handler 都是这么做的:
def _handle_write_file(args, **kw):
if not args.get("path"):
return tool_error("write_file: missing required field 'path'...")
if "content" not in args:
return tool_error("write_file: missing required field 'content'...")
# ...9.4 check_fn 必须加
依赖外部状态的工具一定要提供 check_fn。如果不加,工具会出现在模型可用的工具列表里,但调用时必然失败。模型会反复重试,浪费 Token。社区反馈里 MCP 服务器连接超时、Docker 权限拒绝这类问题很常见,check_fn 可以提前暴露这些状态。
9.5 Toolset 组合策略
按场景分组,用 includes 组合复用。源码里 debugging 工具集组合了 web 和 file,因为调试时经常需要搜索错误信息 + 读取文件。safe 工具集组合了 web、vision、image_gen,排除了 terminal - 适合不需要执行命令的场景。
9.6 MCP 集成
Hermes 支持 MCP 协议扩展外部工具。MCP 工具动态注册到 registry,toolset 名为 mcp-<server_name>。配置支持三种传输方式:
mcp_servers:
filesystem:
command: "npx"
args: ["-y", "@modelcontextprotocol/server-filesystem", "/tmp"]
timeout: 120
remote_api:
url: "https://my-mcp-server.example.com/mcp"
headers:
Authorization: "Bearer sk-..."MCP 工具和内置工具在 registry 里完全等价,check_fn、dispatch()、get_definitions() 都用同一套逻辑。
总结
Hermes Agent 的工具系统做对了几件事:
import 即注册。新增工具文件不需要修改任何注册逻辑,只要文件里有 registry.register() 调用就会被自动发现。
单例注册表。所有工具的 Schema、handler、可用性检查集中在一个地方管理,没有散落各处的字典和配置。
分层清晰。注册、发现、编排、分组各层独立,修改一层不影响其他层。
防御性设计。注册隔离、错误脱敏、Schema 清洗、参数强转、结果截断...源码里到处是防呆措施。
说到底,这套架构不是什么复杂的设计模式,就是"每个工具自己管自己,注册表统一收口"的思路。但正因为它简单,所以好扩展、好调试、好理解。14.9 万 Star 不是白来的。
如果你也在做 Agent 框架或者给 Hermes 写自定义工具,这套注册表模式值得参考。
相关资源
GitHub 仓库:https://github.com/NousResearch/hermes-agent
官方文档:https://hermes-agent.nousresearch.com/docs/user-guide/features/tools
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号