视觉算法落地复盘

视觉算法落地复盘

javpower
发布于 2026-05-20 13:08:40
发布于 2026-05-20 13:08:40

infographic
核心观点:脱离算力谈精度都是耍流氓,越聪明的模型越难部署。 Demo 跑通 ≠ 上线成功 | 论文 mAP ≠ 产线 FPS | 模型精度 ≠ 部署难度
写在前面
本文不是写给那些在学术会上吹牛的人的。
学术会的论文,每一篇都在说自己的模型多牛,mAP 再涨了几个点,新的 attention 机制如何妙不可言。但你拿他们的代码下来跑一跑,十次有九次导不出 ONNX,剩下一次是导出了但结果对不上。
本文是写给那些真正在前线战场上流血的人。写给那些凌晨三点还在调 ONNX 导出的人,写给那些被老板逼着用大模型上边缘设备的人,写给那些看着华丽的 Demo 视频心动不已、然后上手之后发现现实是一地鸡毛的人。
我在视觉算法落地这个坑里摸爬了很多年。从最早的传统图像处理,到后来的目标检测、语义分割,再到现在的大模型视觉。每一次技术迭代,学术界都会吹出一堆牛皮的论文,但没人告诉你落地的时候会遇到什么。他们只告诉你 mAP 是多少,不告诉你推理一张图要多久。他们只告诉你模型参数量是多少,不告诉你显存要吃多少。他们只告诉你效果多惊艳,不告诉你导出的时候会哭多惨。
本文的核心观点很简单:脱离算力谈精度都是耍流氓,越聪明的模型越难部署,Demo 跑通和上线之间隔着无数个通宵。
这不是什么新鲜的见解,这是每个在一线干过的人都知道的常识。只是这个常识被学术论文的光环和公司宣传的滤镜给遮住了。
第一章:算力是硬通货
老板的要求往往违反热力学定律

infographic
不可能三角
一、算力的残酷现实
做视觉算法落地,你首先要明白一件事:算力是硬通货。
不是什么"可以优化"的软指标,是你绕不过去的铁墙。你的模型再牛,跑不动就是跑不动。你的算法再巧,显存不够就是不够。
我见过太多这样的场景:产品经理拿着一篇论文跑来说"这个模型效果很好,我们也要用",然后你一看论文里的实验设置,清一色的 8 张 A100。而你们公司的生产环境?两张 T4,还要和其他业务共享。
你跟他说显存不够,他说"你们技术人员想办法优化一下"。
优化?你让我把一头大象塞进冰箱里,然后跟我说"你想办法压缩一下"?
算力的残酷在于,它是一个绝对的物理约束。 你不能像调参数一样调显存,不能像训练模型一样训练算力。你有多少卡就是有多少卡,你的卡是 T4 还是 A100 决定了你能用什么模型。
二、老板的热力学定律
每个做视觉算法落地的人,都会遇到一个违反热力学定律的老板。他们的要求通常是这样的:
- 精度要最高
- 速度要最快
- 成本要最低
这三个要求放在一起,就像说我要一辆车,要法拉利的速度、五菱宏光的空间、五万块的价格。你跟他说这不可能,他说"我不管你怎么做,这是业务需求"。
"业务需求"这四个字,是所有不可理要求的遮羞布。
业务需求要求实时检测,但你的模型推理一张图要 200 毫秒。业务需求要求检测万物,但你的模型只训过 80 个类别。业务需求要求部署在边缘设备上,但你的模型要吃 16GB 显存。
每一次你都要在精度、速度、成本三个维度上做取舍,而老板总是希望你三个都不取舍。
我见过最离谱的一次是这样的:一个工业检测项目,要求在树莓派 4B 上跑开放词汇检测,还要实时。我说这不可能,对方说"我们竞争对手都能做到"。
后来我一打听,竞争对手的"开放词汇"就是固定 200 个类别加一个关键词匹配,跟开放词汇检测半毛钱关系都没有。但宣传的时候都叫"开放词汇检测",你说这事儿无赖不无赖。
三、算力预算的残酷物语
算力预算是另一个让人崩溃的话题。
大多数公司的算力预算是这样分配的:训练阶段谁都不想出钱,部署阶段更没钱。 你要训练一个模型,先跟运维申请显卡,等两周审批下来,项目截止日期都过了。你要上线一个服务,发现生产环境的卡是三年前的 T4,而你的模型是在 A100 上开发的。
你跟运维说要升级,运维说"预算明年才有"。
更残忍的是多业务共享算力。你的视觉服务和别人的 NLP 服务挤在同一张卡上,别人的服务一波峰值来了,你的推理就卡成屎。你的 P99 延迟从 30ms 飙到 300ms,前端同事追着你问为什么页面卡顿,你只能说"算力不够"。然后前端同事转头就跟产品经理说"视觉算法太慢了"。你连辩解的机会都没有。
算力第一定律:你能用什么模型,不取决于你的技术水平,而取决于你的算力预算。 你的预算只够买两张 T4,那你就别想什么 DINOv3、SAM。老老实实用 YOLO,把数据管道和后处理做好,比什么都强。这不是保守,这是现实。
四、算力规划的正确姿势
那算力规划到底该怎么做?
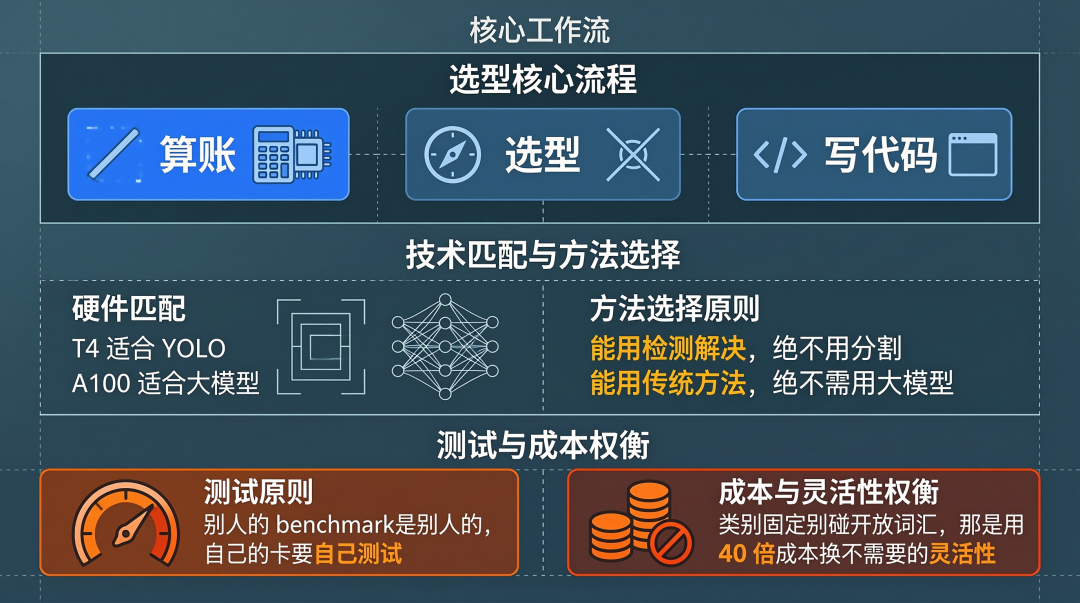
我的经验是:先算账,再选型,最后才写代码。
很多人的做法是反过来的:先写代码跑通,再想怎么部署,最后发现跑不动。这就像先买了一头大象,再想怎么拉回家。
算账要算三个东西:显存、算力、带宽。
指标 | 计算方法 | 为什么重要 |
|---|---|---|
显存占用 | 跑一遍 nvidia-smi 就知道 | 决定你能不能加载模型 |
算力 (FLOPs) | 用 thop 或 ptflops 计算 | 决定推理速度上限 |
带宽 | 输出数据量 × 并发数 | 分割场景容易爆 |
带宽很多人忽略,但它很重要。 你的模型输出一张图要传多少数据?如果是分割图,一张 1024×1024 的 mask 要传 1MB。多目标多分割,带宽就爆了。我见过一个项目,模型推理只要 20ms,但传输结果要 100ms,算下来比不传输还慢。
选型的原则很简单:什么卡跑什么模型。 T4 就是 YOLO 的命,A100 才有资格想大模型的事。别拿着别人在 A100 上跑的 benchmark 来说服自己"这个模型可以用"。别人的 benchmark 是别人的,你的卡是你的。在你自己的硬件上跑一遍,比看一百篇论文都管用。
第二章:检测与分割的妥协
YOLO 是干脏活的老黄牛,VLM 是中看不中用的花瓶
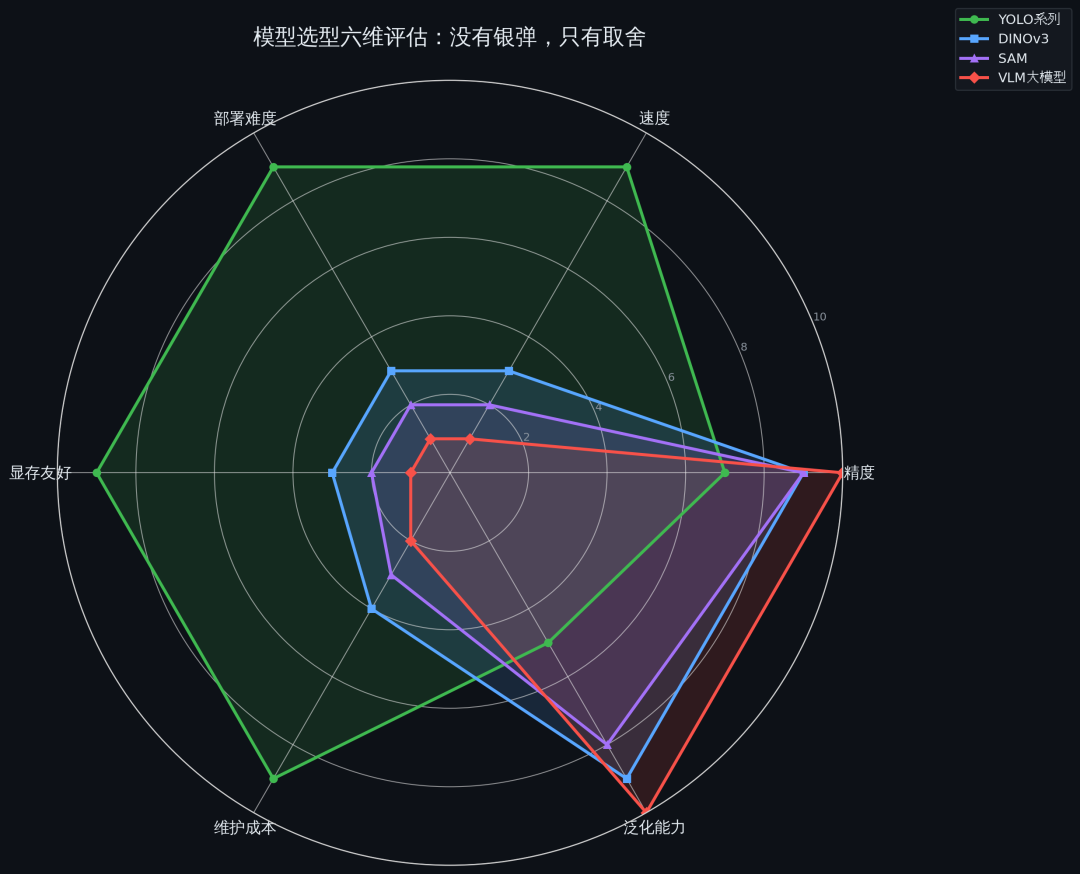
preview
模型雷达对比
一、YOLO:不想干但不得不干的老黄牛
YOLO 这个家伙,说实话,没人喜欢用它。
精度不是最高的,效果不是最好的,小目标检测一般,密集场景会漏。但为什么大家还是用它?
因为它快啊。因为它能跑啊。因为它好部署啊。
在落地的世界里,能跑就是硬道理。 你的 DINOv3 mAP 高五个点又怎么样?推理一张图 200ms,线上服务延迟就爆了。
YOLO 的优势不在于它多牛,而在于它多稳。它像一头老黄牛,不挑活,不挑食,给点草就能干活。你给它 T4,它能跑。你给它 1080Ti,它也能跑。你给它树莓派,它还是能跑。
这种稳定性在工程落地中比什么都重要。因为你永远不知道生产环境会给你什么硬件,你只能确保你的模型在任何硬件上都能跑。
当然,YOLO 也有自己的问题:
问题 | 工程解决方案 |
|---|---|
小目标检测差 | 切图放大 (Tiling) + 多尺度融合 |
密集场景漏检 | 调 NMS 参数 + DIoU-NMS |
旋转目标 | 加数据增强 (Rotation) + 旋转框检测 |
遮挡严重 | 使用 Soft-NMS + 多帧时序融合 |
这些都是"能解决的问题",而不是"跑不动的问题"。在落地的世界里,能解决的问题就不是问题,跑不动的问题才是真问题。
二、VLM:中看不中用的花瓶
再说说 VLM(视觉语言模型)。这两年吹得天花乱坠,什么"看图说话"、"开放世界理解"、"零样本检测"。听起来很美,但你拿到工程现实里一试,就知道这玩意儿有多鸡肋。
先说速度。 一个典型的 VLM,推理一张图要 500ms 到 2s。这还是在 A100 上的数字。你要是放到 T4 上,就更不用说了。而你的业务场景通常要求实时,30fps 是基本线,也就是每张图 33ms 以内。VLM 的推理速度和实时要求之间,差了一个数量级。
你说这个差距能不能优化?能,但优化完也就是从 2s 变成 500ms,还是差了十倍。
再说稳定性。 VLM 的输出是自由文本,你让它检测缺陷,它可能给你写一段诗。你让它识别类别,它可能给你冒出一个谁也不认识的词。这种不确定性在学术演示里不是问题,因为你可以 cherry-pick 好的结果。但在生产环境里,你不能 cherry-pick。每一张图都要给出确定的结果,不能含糊。
最后说成本。 VLM 的参数量通常是几十亿甚至几百亿,这意味着巨大的显存占用和算力消耗。你要在线上服务部署一个 VLM,光显存就要吃掉几十 GB。多实例并发?那就是几十 GB 乘以实例数。
VLM 的落地现状:演示很惊艳,上线很绝望。
三、开放词汇检测的幻觉
开放词汇检测是近两年最大的幻觉之一。
什么"检测任何物体"、"无需训练"、"自然语言描述"。听起来天衣无缝,但落地的时候你会发现,这些能力都是用算力硬扛出来的。
开放词汇检测的典型方案是 CLIP 做图文匹配,或者用 VLM 直接理解图像内容。这两种方案的共同点是:每检测一个类别,都要做一次图文匹配或一次前向推理。
你要检测 100 个类别,就是 100 次匹配。你要检测 1000 个类别,就是 1000 次。这个计算量是随类别数线性增长的,而传统检测器的计算量跟类别数无关。
这就是为什么开放词汇检测在类别多的时候会变得极其慢。
所以开放词汇检测的本质是什么?是用算力换灵活性。 你不需要为每个新类别收集数据、训练模型,但你付出的代价是每次推理都要多花几十倍的算力。
这在某些场景下是值得的,比如类别经常变、数据收集成本极高的场景。但在大多数工业场景下,类别是固定的,数据是可以收集的,这时候用传统检测器加微调才是正解。
四、分割的尴尬处境
分割的尴尬在于,它的价值很难量化。
检测的价值很容易理解:检测到了就是检测到了,没检测到就是漏检,误检就是误检。但分割呢?分割的边界差了两个像素,算好还是算坏?IoU 从 0.92 变成 0.90,业务上有区别吗?
大多数时候没有。但分割的计算量可比检测大得多,输出也大得多。一张检测结果就是几个数字,一张分割结果是一整张 mask。
我的建议:能用检测解决的问题,就不要用分割。 检测框能解决的事,就别动分割。只有在真正需要像素级别精度的场景下,比如医疗影像、细胞分析,才值得付出分割的代价。其他场景,检测框加个粗略的轮廓就够用了。
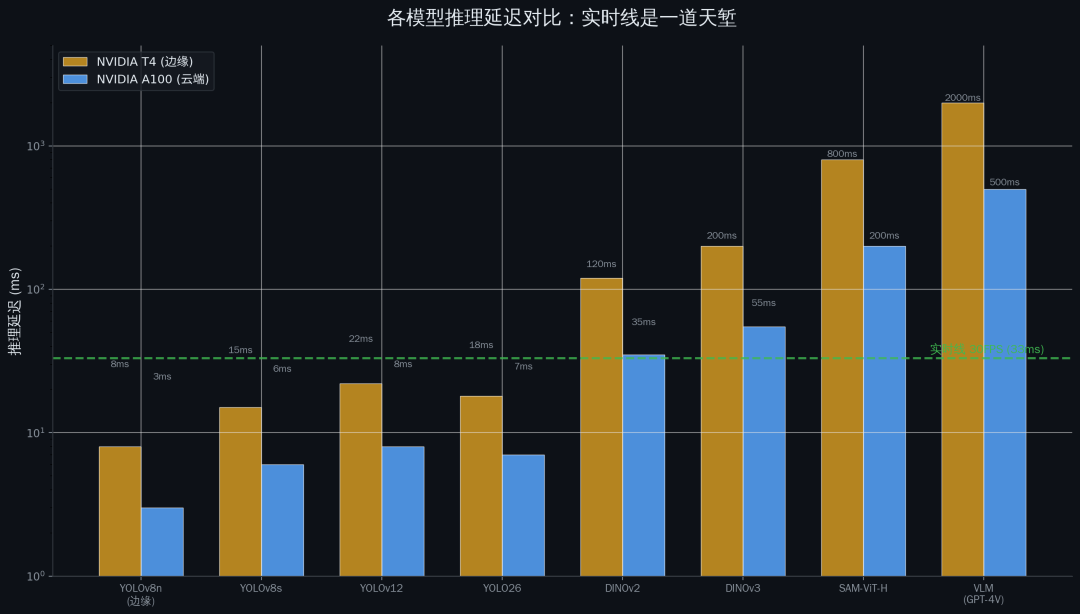
preview
推理延迟对比
第三章:大模型的沉重肉身
DINOv3 泛化强但推理难伺候,SAM 分割一切也吃掉一切显存
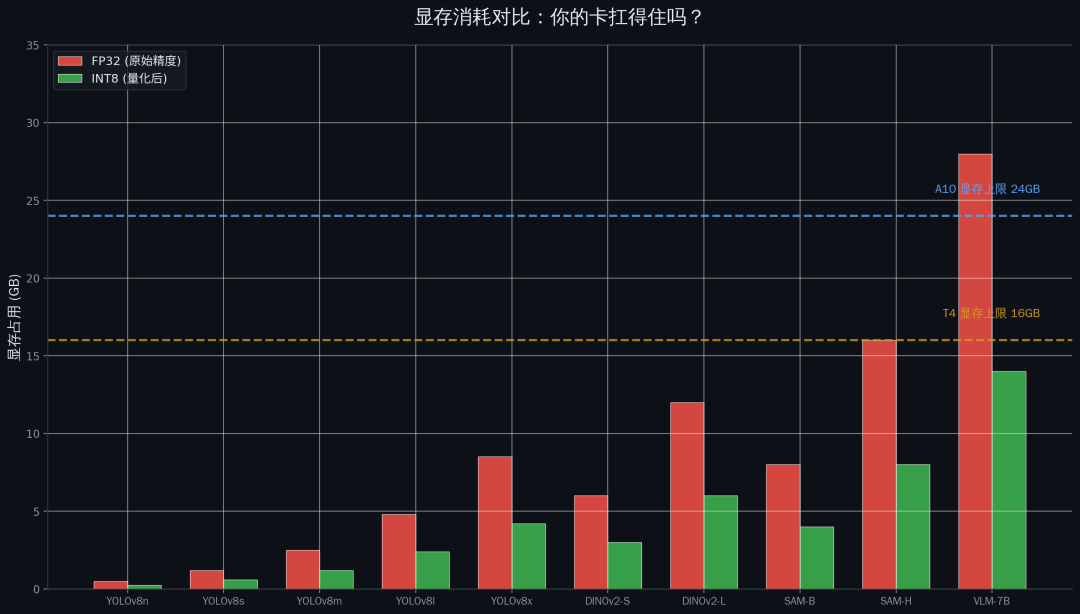
preview
显存消耗对比
一、DINOv3:泛化能力的诱惑
DINOv3 是一个让人又爱又恨的模型。
爱它是因为它的泛化能力确实强,在各种场景下都能检测得不错。恨它是因为它太难伺候了。参数量大、显存占用高、推理慢,这三个问题像三座大山压在你头上。
先说参数量。 DINOv3 的大版本参数量在几亿到十几亿的量级,这意味着它的模型文件就有几 GB。你光加载模型就要花几秒钟,这在需要快速启动的服务场景下是不可接受的。
而且你不能只看模型文件大小,还要看运行时显存。模型参数、优化器状态、中间激活值,这些加起来显存占用通常是模型文件的两到三倍。一个 2GB 的模型文件,运行起来可能要吃 6GB 显存。
再说推理速度。 DINOv3 的推理速度在 A100 上大约是 150-200ms 一张图,这还是最优情况。如果你的输入图像比较大,或者你需要处理多尺度特征,那就更慢了。
而且这个速度是在 A100 上的,你放到 T4 上试试?直接慢十倍。一张图两秒钟,这还叫实时检测吗?这叫实时延迟。
但你说它泛化能力强不强?确实强。在开放场景下,它能检测出很多传统检测器检测不到的东西。
问题是,大多数工业场景不是开放场景。 你的场景是固定的,类别是固定的,这时候你用 DINOv3 的泛化能力就是在浪费。就好比你用一架波音飞机去赶集市,能到是能到,但你花的油钱比集市里买的东西还贵。
二、SAM:分割一切也吃掉一切显存
SAM,Segment Anything Model。这个名字起得多好啊,分割一切。
但实际使用下来,你会发现它分割一切的同时,也吃掉了你一切的显存。 SAM 的 ViT-H 版本,参数量 2.4B,模型文件 2.4GB,运行时显存占用轻松超过 16GB。你的 T4 只有 16GB 显存,光跑 SAM 就把显存占满了,别的什么都别想跑了。
SAM 的另一个问题是它的推理模式。SAM 需要提示点(prompt),可以是点、框或者 mask。这意味着你不能直接把图像丢给它就完事,你还得先有一个检测器给它提供提示点。
所以实际上,SAM 很少单独使用,它通常是一个级联流水线的一部分。 检测器先检测出目标,然后把检测框作为提示点给 SAM,SAM 再输出精确的分割结果。这就是一个两步的流程,延迟是两个模型的延迟之和。
很多时候所谓的"大模型解决一切",其实就是把问题从一个地方转移到了另一个地方。 以前你的问题是分割不准,现在你的问题是显存不够、推理太慢、级联延迟太高。问题没有消失,只是换了一个形式。而且新问题比旧问题更难解决,因为旧问题可以通过改模型解决,新问题是硬件级别的,你改不了。
三、大模型落地的残酷算术
如果你真的要用大模型落地,我给你算笔账。
以 DINOv3 为例,假设你用它做开放词汇检测,类别数 100:
指标 | DINOv3 + A100 (10卡) | YOLO + T4 (2卡) | 倍数 |
|---|---|---|---|
单帧延迟 | 250ms | 15ms | 16x |
并发支持 | 10路 | 10路 | - |
月租成本 | $20,000 | $500 | 40x |
年成本 | $240,000 | $6,000 | 40x |
40 倍的差价换来的是什么? 是开放词汇能力。但你的业务真的需要开放词汇吗?还是说你只是觉得开放词汇听起来很酷?
如果你的类别是固定的,就别花这个冤枉钱。把钱省下来给团队买好点的显卡,比什么都强。
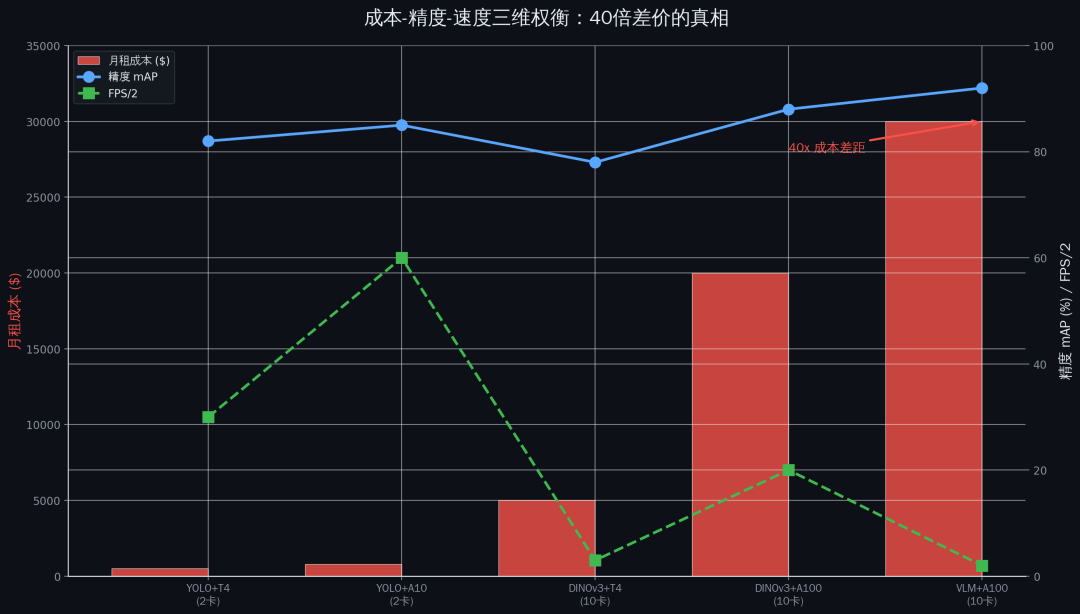
preview
成本对比
第四章:缝合怪流水线
级联往往延迟爆表,最终出路往往是蒸馏
preview
级联vs蒸馏
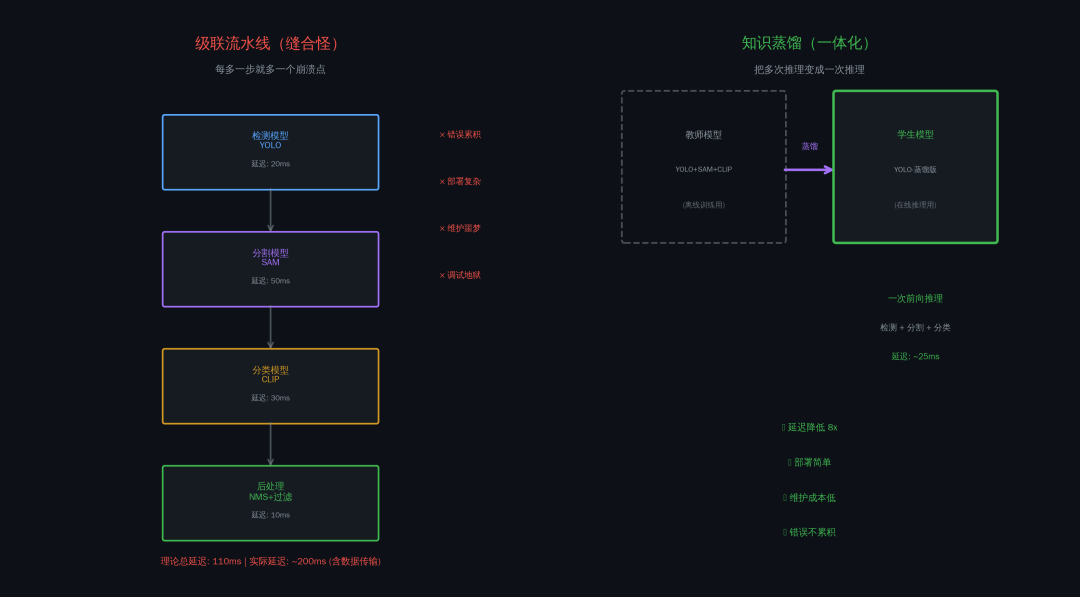
一、级联的诱惑
当一个模型解决不了问题的时候,人们的第一反应是什么?
加一个模型。
检测不够准?加个分割模型精炼轮廓。分类不够细?加个 CLIP 做细粒度分类。这就是级联,也叫缝合怪流水线。
听起来很合理,每个模型做自己擅长的事,组合起来就是完美方案。但实际上,级联是延迟的坟墓。
为什么?因为延迟是累加的。
你的检测模型要 20ms,分割模型要 50ms,分类模型要 30ms,后处理要 10ms。理论上总延迟是 110ms,大约 9fps。但实际上呢?
模型之间的数据传输要时间,内存拷贝要时间,前后处理要时间,实际延迟往往是理论值的 1.5 到 2 倍。所以你的 110ms 实际上可能是 200ms,也就是 5fps。这还叫实时吗?
而且级联还有一个致命问题:错误累积。
前一个模型的输出是后一个模型的输入,前一个模型犯的错,后一个模型会放大。检测模型漏检了一个目标,分割模型就不可能分割到它。检测模型误检了一个目标,分割模型就会分割出一个错误的区域。这种错误累积在单个模型的时候不明显,但在级联流水线中会被指数级放大。
二、级联的工程噩梦
级联的工程问题不仅仅是延迟。
首先是部署复杂度。 你要同时部署多个模型,每个模型都有自己的依赖、配置、版本。模型 A 用 PyTorch 1.13,模型 B 用 PyTorch 2.0,模型 C 用 TensorFlow。你要把它们都转成 ONNX 或 TensorRT,每个都有自己的坑。然后你还要写一套管道代码把它们串起来,这套代码的复杂度往往不低于模型本身。
其次是维护噩梦。 任何一个模型更新了,整个流水线都要重新测试。模型 A 的输出格式变了,模型 B 的输入就要改。模型 B 的输出变了,模型 C 的输入又要改。这种级联依赖让维护成本指数级上升。
我见过一个团队,三个模型的级联流水线,每次更新任何一个模型,都要花一周时间重新测试整个链路。后来他们干脆冻结了模型版本,谁也不敢动了。
最后是调试地狱。 级联流水线出了 bug,你要怎么调?是模型 A 的问题,还是模型 B 的问题,还是管道代码的问题?你要一个一个排查,每个模型都要单独测试,然后组合测试,然后端到端测试。这个调试过程的时间成本,往往比开发模型本身还高。
三、蒸馏:唯一的出路
那级联的出路是什么?
蒸馏。 把多个模型的能力压缩到一个模型里,让一个模型同时学会检测和分割,或者同时学会检测和分类。这样你就不需要级联了,一次前向就能得到所有结果。
延迟从多个模型的总和变成了一个模型的时间,这是质的飞跃。
但蒸馏也不是什么仙丹妙药:
挑战 | 说明 |
|---|---|
需要数据 | 用教师模型生成伪标签,过程本身就很耗时 |
学生容量 | 太小装不下知识,太大失去蒸馏意义 |
调试复杂 | 温度参数、损失权重、蒸馏层选择都需要调 |
但即便如此,蒸馏仍然是目前最好的方案。因为它解决的是根本问题:把多次推理变成一次推理。 这是从架构层面解决问题,而不是在原来的架构上打补丁。
我见过太多团队在级联流水线上做各种微调优化,什么异步推理、批处理优化、内存池化,折腾了半天提升了 20%,结果蒸馏一上来直接快了五倍。
方向错了,努力就是浪费。
第五章:ONNX 跨界地狱
动态维度是诅咒,用 C++/Java 重写后处理是反人类的
ONNX坑点地图
一、ONNX 导出的玄学
ONNX 是什么?官方说法是"开放神经网络交换格式",听起来很美好,仿佛你只要把模型导出成 ONNX,就能在任何平台上跑。
但实际使用中,ONNX 导出就是一门玄学。 你永远不知道下一个报错是什么,也不知道为什么能导出但结果不对。
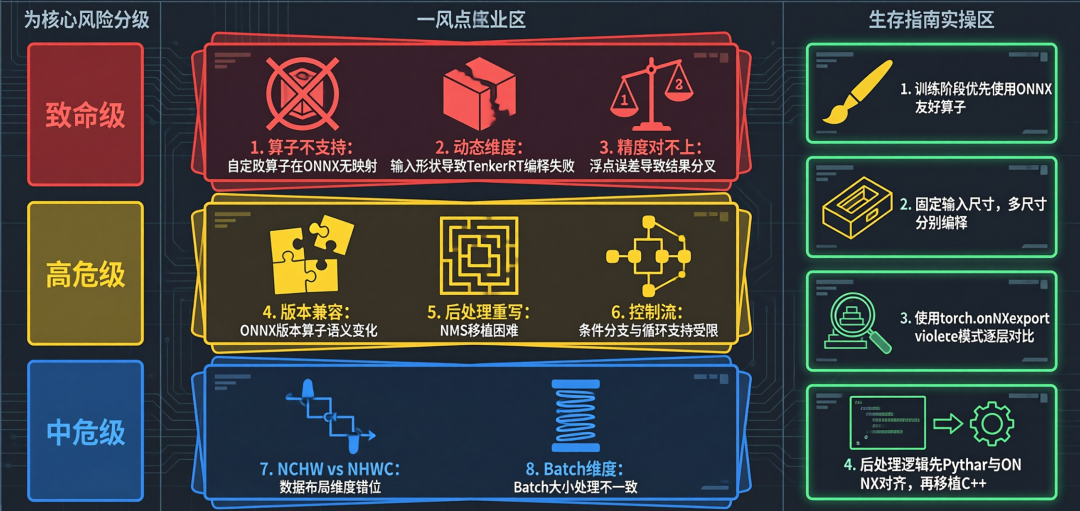
最常见的坑有这么几个:
第一,不支持的算子。 PyTorch 里能用的算子,ONNX 不一定支持。你开心地用了一个自定义算子,导出的时候直接报错。然后你就得把这个算子拆成 ONNX 支持的基本算子的组合,这个过程有时候比写模型还累。
第二,动态维度。 这是 ONNX 最大的诅咒,后面单独讲。
第三,版本兼容性。 ONNX opset 版本不同,支持的算子也不同。你用 opset 14 导出的模型,在只支持 opset 11 的推理引擎上跑不了。
最让人崩溃的是"导出成功但结果不对"。 这种情况比直接报错还恶心,因为直接报错你还能知道哪里有问题,结果不对你连问题在哪里都不知道。可能是某个算子的实现差异,可能是精度损失,可能是某个分支逻辑不一样。
你要一层一层地对比 PyTorch 和 ONNX 的中间输出,找到哪一层开始出现差异。这个调试过程可以轻松花掉你一整天。
二、动态维度:最大的诅咒
动态维度是 ONNX 最大的诅咒,没有之一。
什么是动态维度?就是模型的输入形状不固定。 比如你的模型可以接受任意大小的图像,这在 PyTorch 里很正常,但在 ONNX 和推理引擎里就是一场灾难。
为什么?因为很多推理引擎在编译模型的时候,需要知道确切的输入形状才能做优化。比如 TensorRT,它会根据输入形状选择最优的 kernel。你的输入形状不固定,它就没法优化,或者要为每种形状都编译一个版本。
这就导致了一个很荒谬的现象:你的模型在某个图像尺寸下跑得很快,换个尺寸就爆了。
解决动态维度的方案通常有两种:
方案 | 优点 | 缺点 |
|---|---|---|
固定输入尺寸 | 简单,编译一次 | resize 会丢失信息,影响精度 |
多尺寸编译 | 精度不受影响 | 编译时间和显存占用倍增 |
没有完美的方案,只有取舍。
三、后处理的反人类重写
如果说 ONNX 导出是玄学,那后处理的重写就是反人类。
为什么要重写? 因为很多模型的后处理逻辑在 ONNX 里表达不了,或者表达了但效率极低。比如 NMS(非极大值抑制),这个操作涉及循环和条件分支,在 ONNX 里实现起来效率很低。所以很多时候,你会把后处理从 ONNX 图里拿出来,用 C++ 或 Java 重写。
这就是噩梦的开始。
你要用 C++ 或 Java 重写 Python 的后处理逻辑,这个过程充满了坑:
- 数据对齐问题: ONNX 的输出是 NCHW 格式,你的 Java 代码可能用的是 NHWC,光维度转换就能让你调半天。
- 精度问题: Python 里用 float64 算的东西,你在 C++ 里用 float32,结果就不一样了。
- 边界情况: Python 里很多操作都有默认的边界处理,你在 C++ 里得自己写,少写一个判断就可能崩溃。
我见过最离谱的一次是这样的:一个团队花了两周时间用 Java 重写了 YOLO 的后处理,结果和 Python 版本对比发现 mAP 差了两个点。排查了一周,发现是 NMS 里一个排序的稳定性问题。Python 的排序是稳定排序,Java 的排序是不稳定排序,同分的检测框顺序不一样,导致 NMS 结果不一样。
这种坑,你不踩一遍根本想不到。
部署流程全景
第六章:边缘生存
量化是逼出来的妥协,剪枝往往跑不快

边缘设备矩阵
一、边缘设备的残酷现实
边缘设备是什么?就是那些算力弱、内存小、功耗低的设备。树莓派、Jetson Nano、手机芯片、工业相机的内置芯片,这些都是边缘设备。
它们的共同特点是:资源极度有限。 你在服务器上随便用的东西,在边缘设备上都是奢侈品。
边缘设备的最大的残酷在于,它的资源是真的不够。不是"勉强能用"的不够,是"怎么折腾都不够"的不够。你的模型在服务器上占 4GB 显存,边缘设备总共就只有 2GB 内存,还要分给操作系统和其他程序。
你怎么放进去?这不是优化的问题,这是物理上不可能的问题。
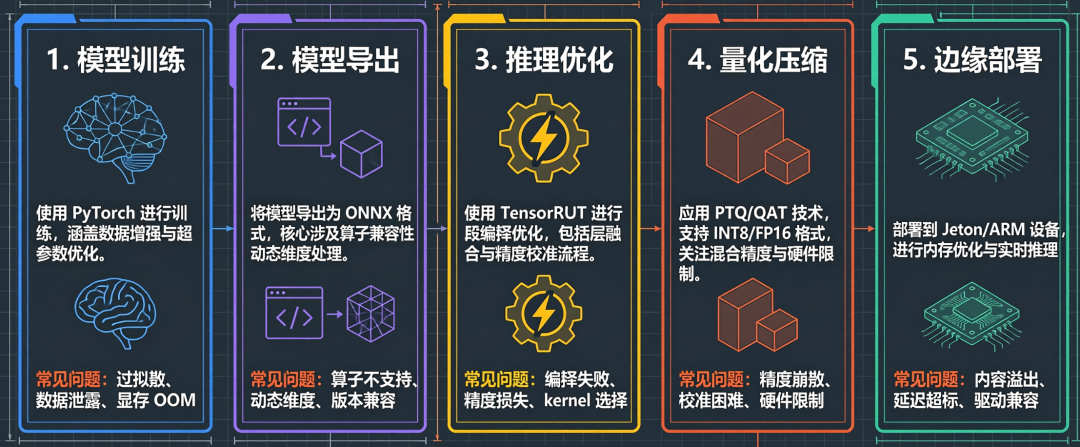
所以边缘部署的核心不是"怎么把模型放进去",而是"怎么把模型缩小到能放进去"。这就引出了两个核心技术:量化和剪枝。听起来都很美好,但实际用起来都是泪。
二、量化:逼出来的妥协
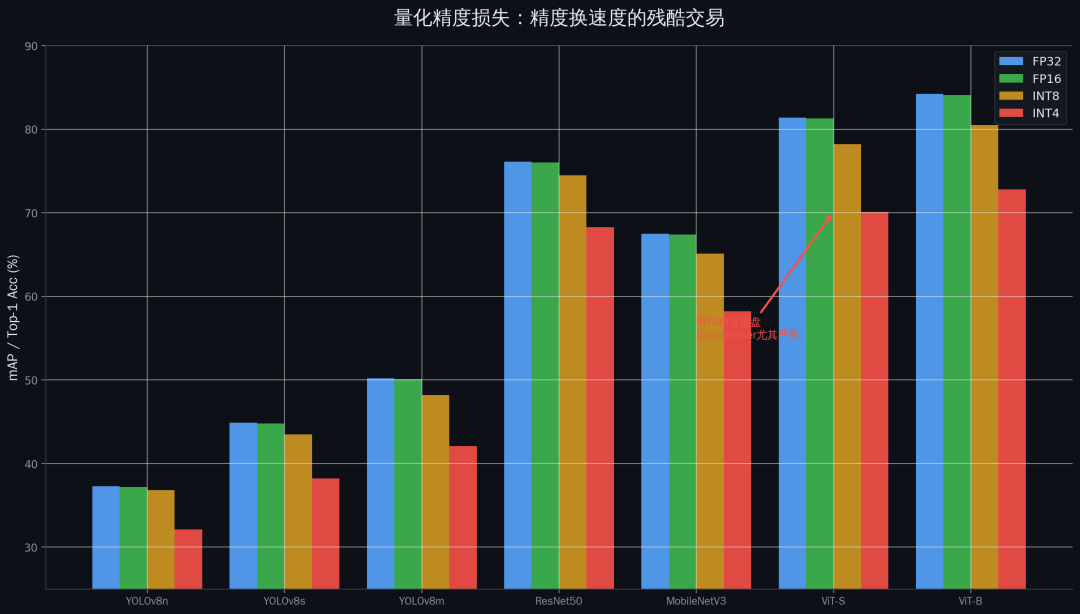
量化是什么?简单说,就是把模型的参数从高精度格式变成低精度格式。
精度 | 模型大小 | 推理速度 | 典型精度损失 |
|---|---|---|---|
FP32 | 100% | 1x | 0% (baseline) |
FP16 | 50% | ~1.5x | ~0.1% |
INT8 | 25% | ~2-3x | ~0.5-2% |
INT4 | 12.5% | ~4x | 5-15% (可能崩盘) |
每降一级精度,模型就小一倍,推理就快一倍,但精度也会下降。这是一个残酷的交易:用精度换速度。
量化最大的坑在于:精度下降不是均匀的。 有些模型量化后精度只掉一个点,有些模型量化后精度直接崩盘。你不知道你的模型属于哪种,只有试了才知道。
而且同一个模型的不同层,对量化的敏感度也不一样。有些层量化后没什么影响,有些层量化后直接废了。你要一层一层地试,找出哪些层可以量化、哪些层不能量化。这个过程叫混合精度量化,耗时耗力,但效果比简单的全量化好得多。
PTQ(训练后量化)和 QAT(量化感知训练)是两种主流方案:
- PTQ: 简单,不需要重新训练,但精度损失可能较大。大多数人先试 PTQ。
- QAT: 精度损失小,但需要重新训练,这意味着你又要申请算力了。
在实际工作中,大多数人先试 PTQ,如果精度不行再考虑 QAT。但很多时候 PTQ 的结果就是不行,你只能硬着头皮上 QAT。
这就是现实,没有捷径。
三、剪枝:理想很丰满,现实很骨感
剪枝是另一个听起来很美的技术。把不重要的参数剪掉,模型变小了,速度变快了,精度还不变。多美啊。
但实际上,剪枝的效果很大程度上取决于硬件。
在 GPU 上,剪枝后的稀疏矩阵运算往往比密集矩阵还慢,因为 GPU 是为密集运算设计的。你剪掉了 50% 的参数,速度可能只快了 10%,甚至更慢。
这就是剪枝的骨感现实:理论上参数少了应该快,实际上硬件不支持稀疏运算,反而更慢。
只有在专门支持稀疏运算的硬件上,比如某些 NPU,剪枝才能真正发挥作用。但即便是 NPU,不同的 NPU 对稀疏率的支持也不一样。有的支持 2:4 稀疏,有的支持任意稀疏,有的只支持结构化稀疏。你的剪枝方案必须和硬件紧密配合,这就大大增加了工程复杂度。
我的建议是:如果你的目标是边缘部署,先试量化,再考虑剪枝。 量化的效果更可预测,工具链更成熟,而且几乎所有硬件都支持低精度运算。剪枝更像是一个"锦上添花"的技术,在特定场景下有用,但不是通用解法。
preview
量化精度损失
技术选型决策树
infographic
技术选型决策树
写在最后:活着就是胜利
infographic
写到这里,这篇文章差不多就到尾声了。
回头看看这些内容,其实说来说去就是一个核心观点:脱离算力谈精度都是耍流氓。 这个观点不新鲜,但每次有新模型发布的时候,总有人忘记它。
视觉算法落地这个领域,没有银弹,没有万能药。 每一个项目都是一次取舍,每一次部署都是一次妥协。你要在精度、速度、成本之间找到平衡点,而这个平衡点每次都不一样。
今天的最优解不是明天的最优解,这个项目的最优解不是那个项目的最优解。你要做的就是在每一次取舍中找到最适合当前场景的方案,而不是追求什么都最好的幻觉。
最后,我想对所有在视觉算法落地一线的同伴们说几句。
这个行业很苦,但也很有意思。你解决的每一个问题都是实打实的,你写的每一行代码都是真正在服务用户的。别被学术论文的光环迷了眼,也别被老板的不切实际的要求吓住了。
找到你的算力边界,在边界内做到最好,这就是落地的王道。
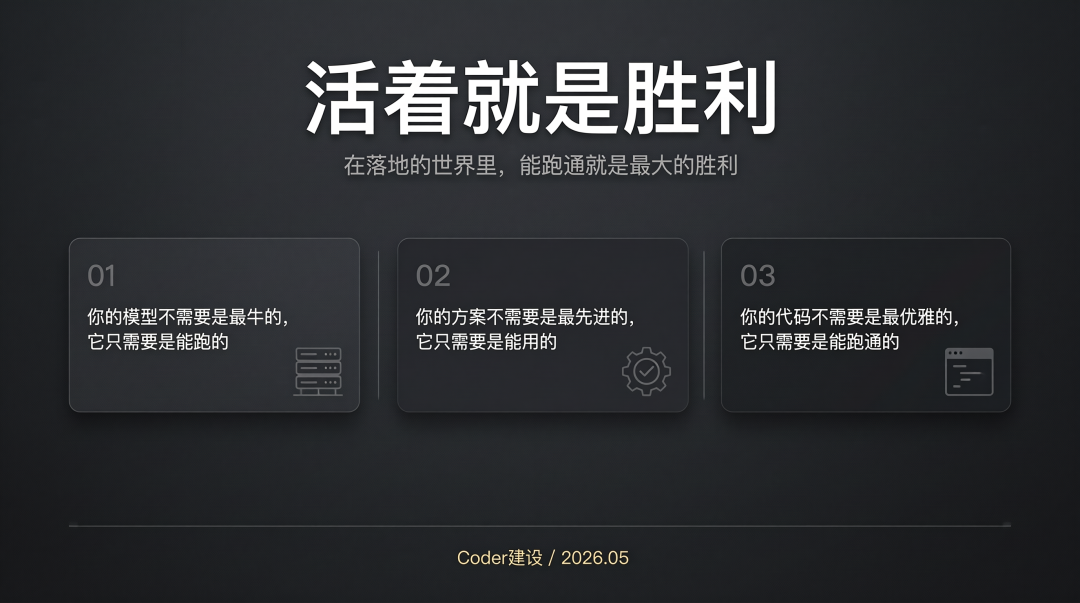
活着就是胜利。 这不是什么鸡汤,这是我在无数个通宵后想明白的道理。 你的模型不需要是最牛的,它只需要是能跑的。 你的方案不需要是最先进的,它只需要是能用的。 你的代码不需要是最优雅的,它只需要是能跑通的。
在落地的世界里,能跑通就是最大的胜利。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号