基于本体模型驱动的 AI 原生应用,通过 DevOps + Serverless 实现持续集成和交付

基于本体模型驱动的 AI 原生应用,通过 DevOps + Serverless 实现持续集成和交付

人月聊IT
发布于 2026-05-13 20:29:21
发布于 2026-05-13 20:29:21
大家好,我是人月聊IT。
进行继续分享本体模型驱动的AI原生应用构建。今天思考的一个重点就是基于我前面的本体建模规范,结合DevOps和ServerLess云服务基础实施,实现本体模型构建的AI原生应用持续一键交付到云服务环境上面。
从语义建模到云端自动交付的完整工程实践
一、引言:软件开发范式的结构性转变
软件工程发展数十年,每一次范式跃迁的本质都是在降低"人的意图"转化为"机器执行"的摩擦成本。从汇编到高级语言,从瀑布到敏捷,从单体到微服务,这条演进脉络清晰可见。而今天,AI 大模型的成熟与云原生基础设施的普及,正在推动一次更深层的转变:软件的语义可以被精确形式化,AI 可以同时承担建造者和执行者两个角色。
本文描述的是一套完整的工程实践:以本体模型为系统的唯一语义核心,以 AI 大模型为双引擎(建造期生成代码、运行期理解意图),以 Serverless + BaaS 为云端运行底座,以 DevOps 流水线为自动化交付通道,最终构建出一类全新的 AI 原生应用形态。
二、本体模型 + AI 原生:核心思路
2.1 本体模型:软件系统的语义骨架
本体模型借鉴知识工程中本体(Ontology)的核心思想,用一套结构化的 YAML 元文件完整描述一个业务域的全部语义。不同于传统的需求文档或 UML 图,本体模型是机器可读、可校验、可驱动代码生成的活的语义规范。
完整的本体模型体系由九个维度构成:
- M1 对象模型:定义业务实体的属性、生命周期状态、实体间的关联关系(组合、聚合、关联)以及参照完整性约束。这是系统数据层的语义源头,所有数据库表结构从这里派生。
- M2 行为模型:定义对象能执行的原子行为。每个行为只操作一个聚合根,包含前置条件、后置状态变更、调用的规则引用和产生的领域事件。
- M3 规则模型:存放可复用的业务逻辑规则,包括验证规则、计算规则和推导规则。规则从行为中解耦,可被多个行为引用,独立演进。
- M4 场景模型:描述完整的业务用例和流程,是多个原子行为通过事件链编排的结果,对应用户的完整业务意图。
- M5 主体模型:定义系统参与者、角色和权限边界,采用 RBAC 为基础、ABAC 扩展的权限体系,直接驱动数据库行级安全策略(RLS)的生成。
- M6 异常补偿模型:定义行为失败时的 Saga 补偿策略,处理分布式长事务的最终一致性。
- ME 事件模型:显式定义系统中流转的领域事件,驱动事件总线的订阅配置和实时推送通道。
- M7 质量约束模型:以标注形式将非功能性需求(性能 SLA、一致性级别、AI 模型选型)绑定到具体行为和场景。
- M9 UI 模型:定义前端页面结构、表单布局和导航树,驱动前端组件的元数据化生成。
这九个模型共同构成了一套正交完备的业务语义体系——每个维度描述业务的一个独立关切,互不干扰,可独立演进。
2.2 本体模型的三重角色
理解这套架构的关键,在于理解本体模型在系统中承担的三重角色:
角色一:业务建模载体。 本体模型是业务专家和技术团队的共同语言。业务专家通过自然语言对话与 AI 大模型协作生成本体 YAML,不需要编程能力,只需要业务领域知识。生成的模型经过可视化工作台的人机协同审查确认后,成为整个系统的权威语义定义。
角色二:程序生成基础。 AI 大模型在建造期读取本体 YAML,自动生成数据库 DDL、API 骨架、权限策略文件、AI 工具 Schema 等全部程序产物。代码是本体语义的物理实现,不是手工逐行编写的。每一行生成的代码都携带溯源标签,指向其来源的本体模型节点。
角色三:AI 推理知识底座。 在运行期,本体模型的语义内容被加载进运行时注册表,作为 AI 大模型构建 Prompt 上下文的结构化知识来源。AI 在理解用户意图时,注册表提供了实体定义、行为边界、查询范围等精确的业务语义,使 AI 的执行精度和可控性大幅提升。
2.3 AI 原生应用的新形态
基于本体模型驱动的 AI 原生应用,与传统软件应用在交互形态上有根本性差异。
传统应用的交互核心是 UI 表单——用户必须找到正确的菜单、填写规范的表单、按照固定的操作路径完成任务。软件是主体,用户适应软件。
AI 原生应用完全倒转了这个关系。用户用自然语言表达意图,系统通过本体路由器将意图映射到 M2 行为,执行引擎调用行为并返回结果,轻 UI 层根据结果类型选择最合适的呈现方式(文本、表格、图表或操作确认面板)。软件适应用户。
这种应用形态采用 Hybrid UI 设计:高频确定性操作通过固定业务界面完成(表单录入、标准查询),低频探索式需求通过 AI 对话动态完成(分析、统计、复合查询)。两者共享同一套后端能力层和设计系统,对用户呈现一致的视觉体验。
三、云原生交付方案:技术路线选择
3.1 核心技术选型原则
在确定了本体模型驱动的应用架构之后,云端交付方案的选择遵循一条核心原则:只维护业务语义(本体 YAML),基础设施全部由云平台承载。这意味着:
- 无需维护服务器、数据库集群、消息队列、缓存集群等有状态基础设施
- 业务逻辑以无状态函数的形式运行,按调用计费,自动弹性伸缩
- 安全、认证、实时消息等横切关注点由 BaaS 平台原生提供
- 持续集成和交付由 DevOps 流水线自动完成,本体模型变更推送后全链路自动同步
基于这一原则,技术路线选择如下:Supabase 作为 BaaS 后端服务平台,Supabase Edge Functions(TypeScript / Deno)作为 Serverless 计算层,GitHub Actions 作为 CI/CD 流水线,Vercel / Cloudflare Pages 作为前端托管和 CDN。
3.2 为什么选择 Supabase
Supabase 不是一个单纯的数据库服务,而是一个以 PostgreSQL 为核心的完整后端服务生态,与本体驱动架构的契合度极高:
- Database(PostgreSQL 15+):M1 对象模型直接映射为表结构,pgvector 扩展提供向量语义检索能力,pg_cron 支持定时任务,audit_log 触发器自动注入审计字段。
- Row Level Security(RLS):M5 主体模型的数据范围规则直接编译为 PostgreSQL 行级安全策略。每一条 SQL 查询天然受用户 JWT 身份约束,数据隔离在数据库层强制执行,无法绕过。
- Auth:内置 JWT 无状态 Token,支持 OAuth2 / SSO,M5 中定义的角色信息作为自定义 claim 嵌入 Token,Edge Function 解析 JWT 即可完成权限前置检查。
- Realtime:基于 PostgreSQL logical replication 的 WebSocket 实时推送,ME 事件模型中定义的领域事件直接映射为 Realtime Channel,不需要独立部署消息队列。
- Storage:用于存储本体注册表 JSON 文件(运行时加载的核心数据源)和业务附件,内置访问控制策略。
- Vault:基于 pgsodium 的加密密钥管理,AI 大模型 API Key 等敏感配置安全存储,不在环境变量明文暴露。
- Edge Functions:与 Supabase 所有服务内网互通,延迟极低,Deno 原生支持 TypeScript,无需编译步骤。
3.3 为什么选择 Serverless
Serverless 架构与本体驱动的 AI 原生应用天然契合,原因有三:
第一,无状态与本体驱动吻合。本体模型是状态的唯一来源,Edge Function 作为无状态执行单元,每次调用从 Supabase Storage 加载注册表后执行业务逻辑,没有本地状态需要管理。
第二,弹性与 AI 负载匹配。AI 对话的请求量存在明显的峰谷特征,Serverless 自动弹性伸缩,无需为峰值流量预置固定容量。
第三,零运维与工程资源聚焦。团队精力集中在本体建模和业务逻辑上,不消耗在基础设施运维上。
四、总体架构设计
4.1 分层架构总览
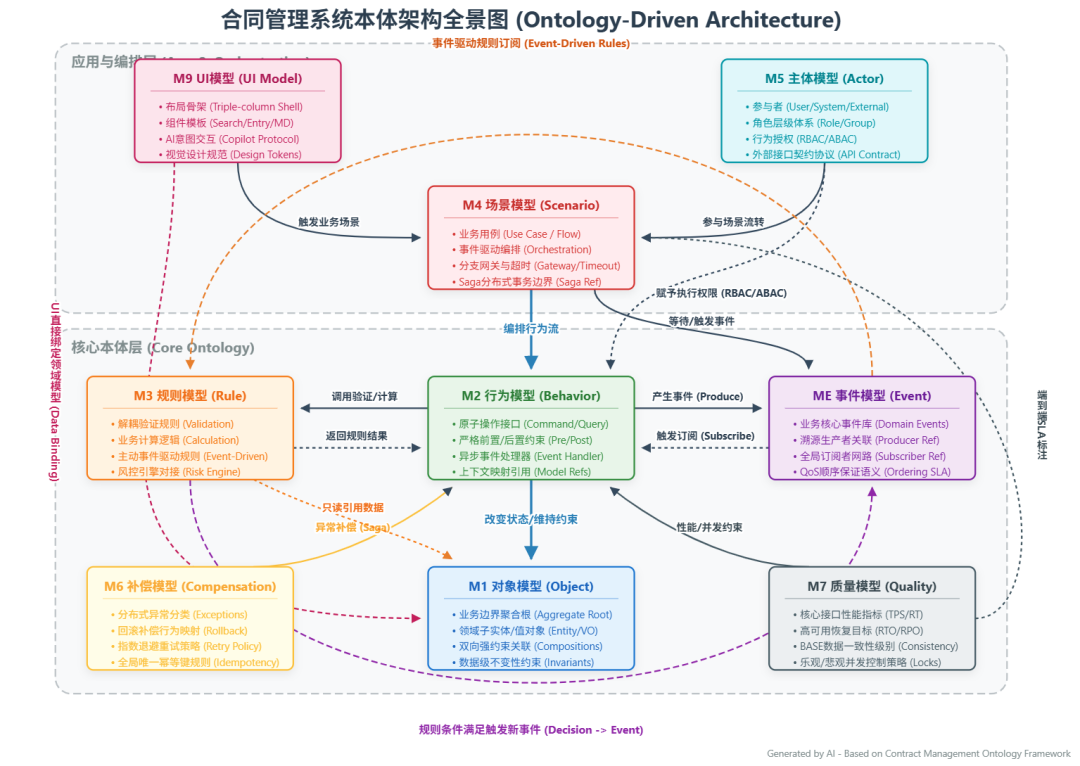
整个系统采用五层架构,每层职责边界清晰:
【架构图一插入位置:五层分层架构全景图】
(包含本体模型层、CI/CD 流水线层、Serverless 计算层、
BaaS 服务层、前端接入层,以及外部 AI 服务和可观测性模块)
第一层:本体模型层是整个系统的唯一真相源,由 Git 仓库中的九个 YAML 元文件构成。任何业务变更都从修改 YAML 开始,通过 git push 触发后续全链路自动同步。
第二层:CI/CD 流水线层(GitHub Actions)负责五个串行步骤:语义校验 → DDL 迁移生成并推送 Supabase → RLS Policy 生成并推送 Supabase → 本体注册表 JSON 构建并写入 Storage → Edge Function 部署更新。
第三层:Serverless 计算层(Supabase Edge Functions,TypeScript/Deno)运行四个核心无状态函数,每个函数启动时从 Storage 加载注册表 JSON 进入内存缓存。
第四层:BaaS 服务层(Supabase Platform)提供 Database、Auth、Realtime、Storage、Vault 等完全托管的后端服务能力。
第五层:前端接入层(Next.js + Vercel)托管在全球 CDN,前端通过 Supabase JS SDK 直连 Auth 和 Realtime,AI 对话通过 SSE 协议与 Edge Function 通信。
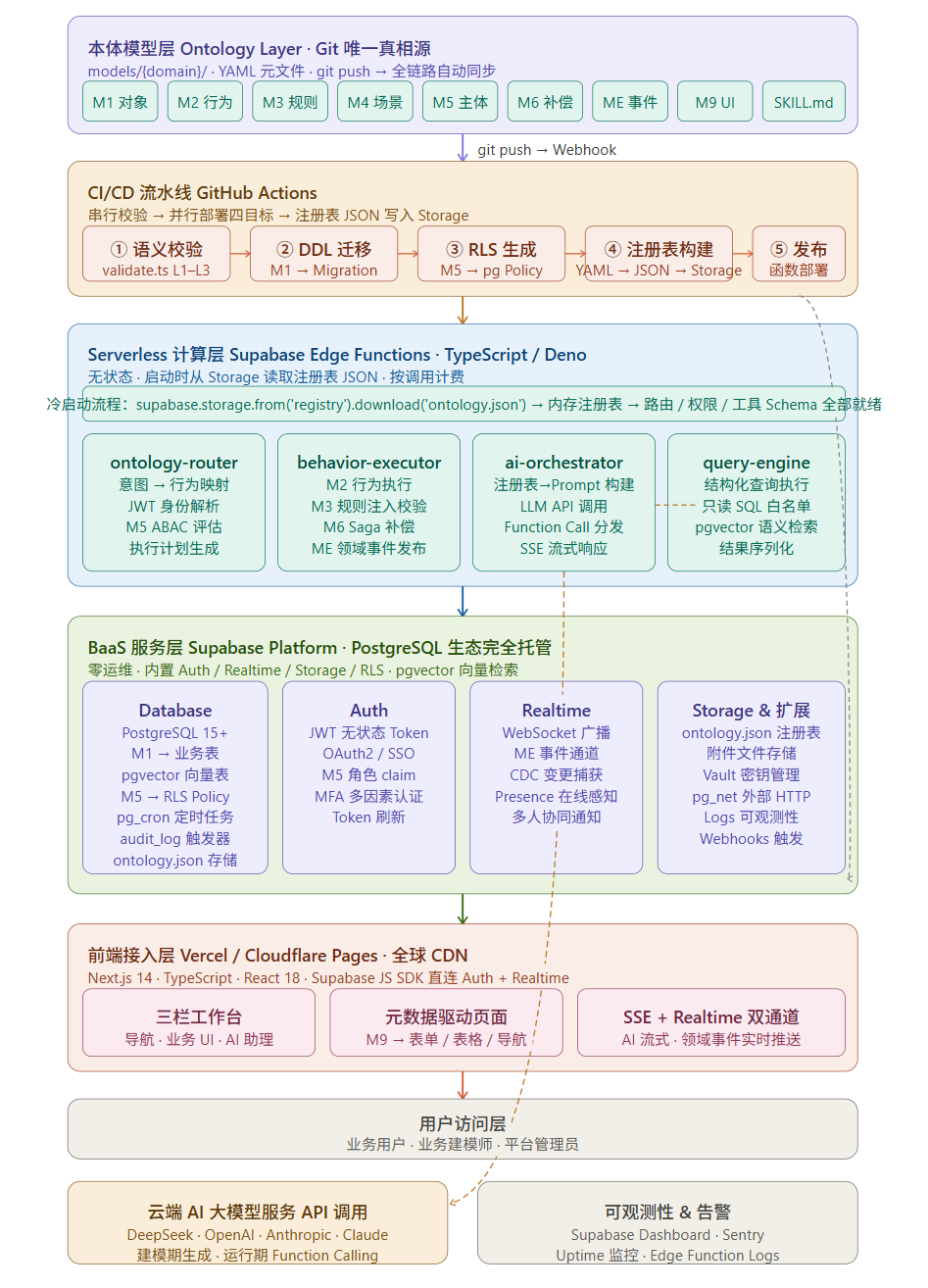
4.2 本体注册表的运行时加载机制
注册表加载机制是整个 Serverless 架构中最核心的设计,解决了"无状态函数如何感知本体语义"的问题:
【架构图二插入位置:注册表加载与版本对齐流程图】
(展示 CI/CD 构建注册表 JSON → 写入 Storage →
Edge Function 冷启动加载 → 模块级内存缓存 →
响应头携带 X-Ontology-Sha 的完整流程)
CI/CD 流水线在每次本体模型变更后,将全部 YAML 解析编译为一个结构化的 ontology.json,同时生成 {gitSha}.json 历史归档版本。Storage 目录结构如下:
supabase-storage/ontology-registry/
├── ontology.json ← 当前生效版本(始终覆盖写)
└── history/
└── {gitSha}.json ← 历史版本归档,用于事件版本对齐和回滚
Edge Function 冷启动时从 ontology.json 加载注册表,利用 Deno 的模块级变量实现同一 isolate 内的多次请求复用,避免每次请求都重新加载。注册表内嵌 gitSha 字段,函数响应头中携带 X-Ontology-Sha,便于调试时确认运行中使用的本体版本。
为保证版本一致性,领域事件的 Payload 中携带产生该事件时的 modelSha,推理引擎处理事件时使用事件自带版本的本体快照而非最新版本,彻底消除版本漂移风险。
五、Serverless 计算层详细设计
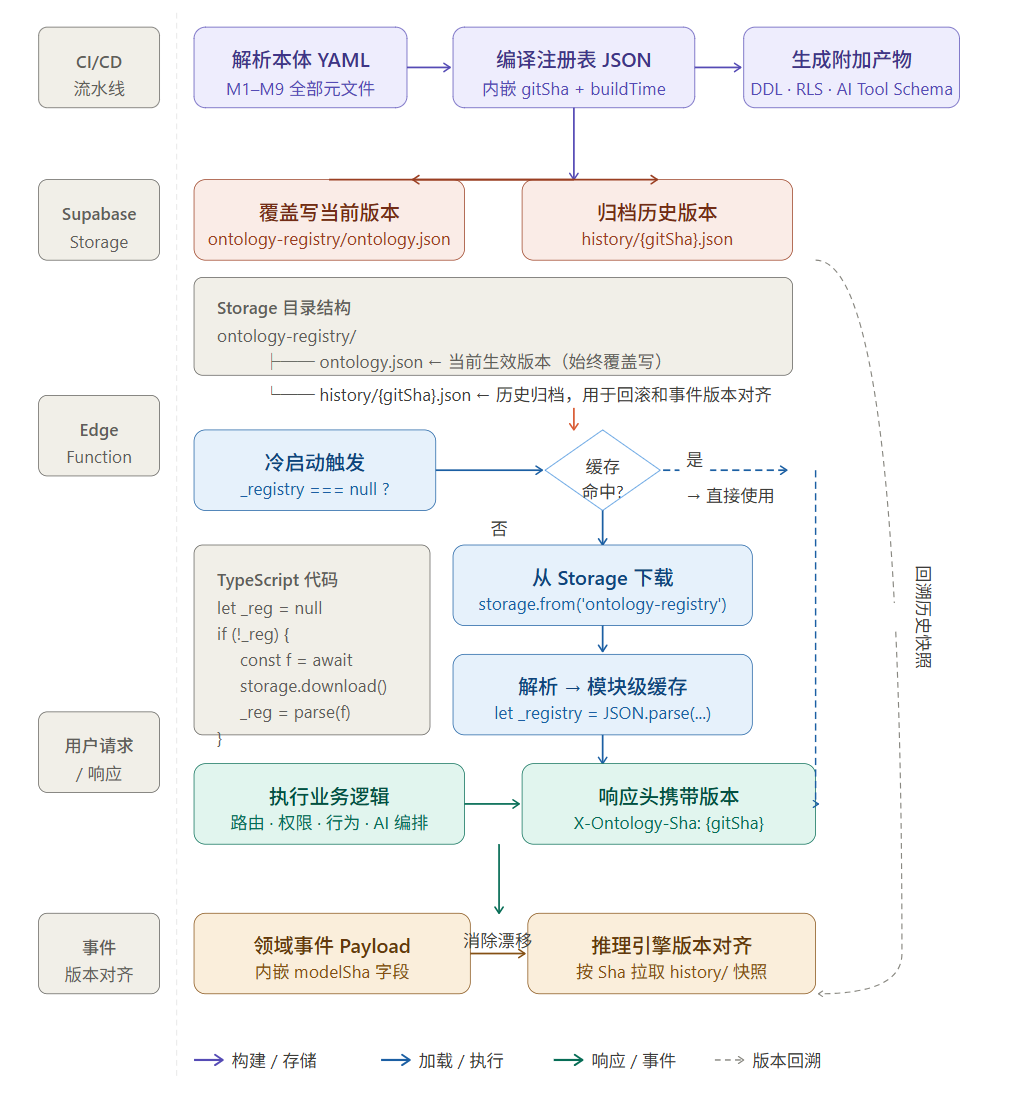
5.1 四个核心 Edge Function
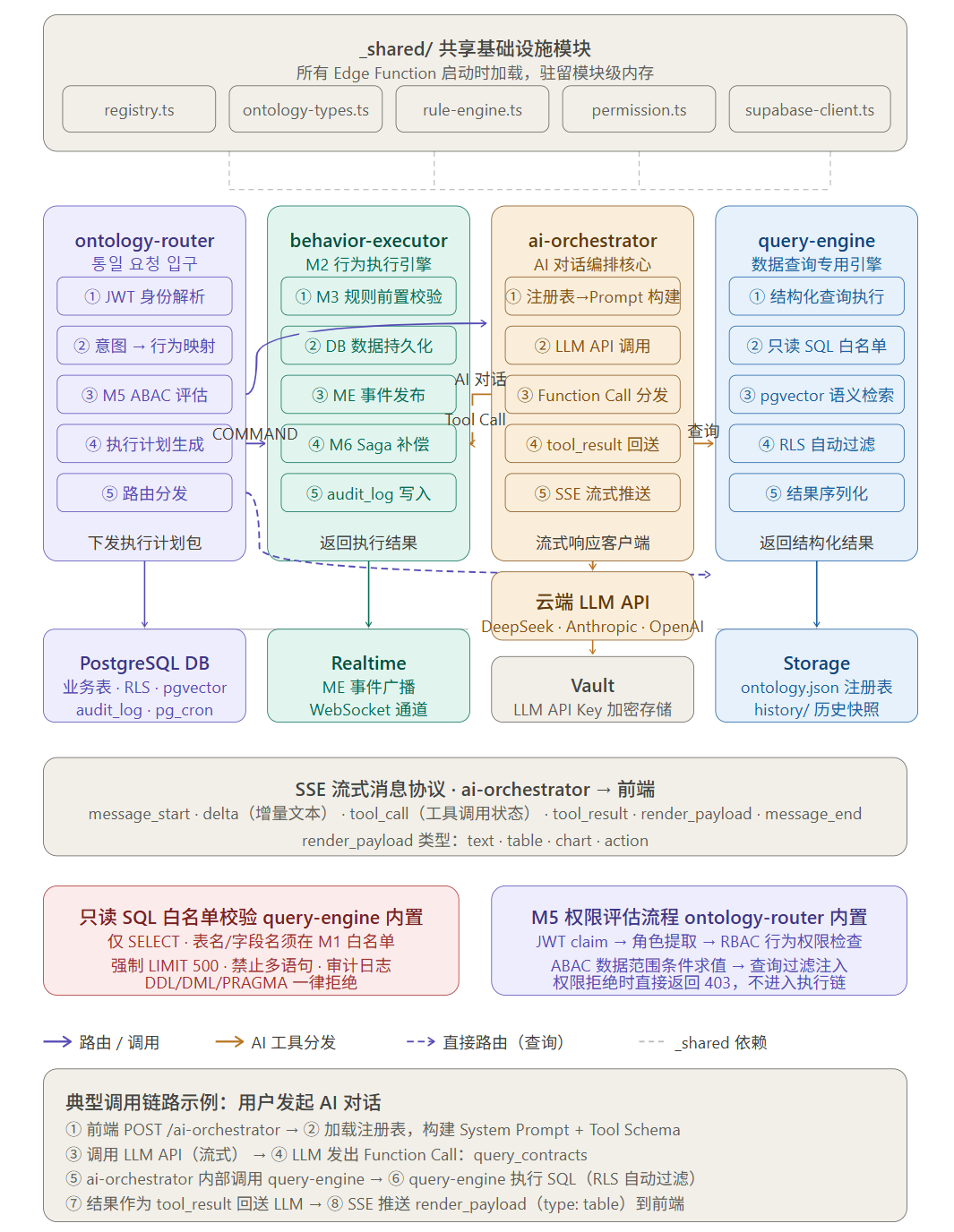
【架构图三插入位置:四个 Edge Function 内部结构与调用关系图】
ontology-router:每次请求的统一入口。负责从 JWT 中解析用户身份,结合注册表中的 M5 主体定义进行 ABAC 权限前置评估,将通过校验的请求路由到对应的 behavior-executor 或 query-engine,生成包含执行计划、权限上下文和本体版本的调用包。
behavior-executor:M2 行为的执行引擎。接收来自 ontology-router 的执行计划,按顺序执行 M3 规则校验(前置条件检查),调用 Supabase Database 完成数据持久化,发布 ME 定义的领域事件到 Realtime Channel,在执行失败时按 M6 定义触发 Saga 补偿逻辑。每个执行步骤记录到 audit_log 表,确保操作可追溯。
ai-orchestrator:AI 对话的编排核心。从注册表中提取与用户意图相关的实体定义、行为描述和场景说明,构建结构化的 System Prompt;携带从注册表 aiTools 字段生成的 Function Calling Schema,调用云端 AI 大模型 API(通过 Vault 中存储的 API Key,支持 DeepSeek、Anthropic、OpenAI 等多种模型,通过 M7 质量注解配置不同场景使用的模型);流式接收 LLM 响应,通过 SSE 协议实时推送给前端;当 LLM 发出 Function Call 指令时,中断流式推送,调用对应的内部函数并将结果作为 tool_result 送回 LLM 继续推理。
query-engine:数据查询的专用引擎。执行注册表中预定义的结构化查询,同时支持 AI 生成的只读动态 SQL(受严格白名单约束:只允许 SELECT,表名和字段名必须在注册表 M1 白名单中,强制追加 LIMIT,禁止多语句执行);提供 pgvector 语义检索接口,用于意图路由中的行为向量匹配。
5.2 AI 大模型 API 调用设计
AI 大模型服务以纯 API 调用方式接入,ai-orchestrator 函数作为调用方,不持有任何模型权重。调用设计遵循以下原则:
模型分级配置:不同场景使用不同规格的模型,通过 M7 质量约束模型配置:建模期的本体生成使用高能力模型(如 Claude Sonnet),运行期的意图路由和对话编排使用高性价比模型(如 DeepSeek),规则引擎无法覆盖的复杂场景由 LLM 兜底处理。
推理引擎分级:高频确定性事件(如合同状态变更触发的规则检查)由预编译为 TypeScript 函数的规则引擎处理,延迟低于 10 毫秒;只有规则引擎无法匹配的低频复杂场景才走 LLM 推理。这避免了"用 LLM 实时处理高频事件"导致的吞吐量瓶颈。
流式响应处理:ai-orchestrator 以 SSE(Server-Sent Events)协议向前端推送六类消息:message_start、delta(增量文本)、tool_call(工具调用状态)、tool_result(工具执行结果)、render_payload(结构化渲染内容,含渲染类型 text/table/chart/action)、message_end。
六、DevOps 持续集成与交付流水线
6.1 流水线全链路设计
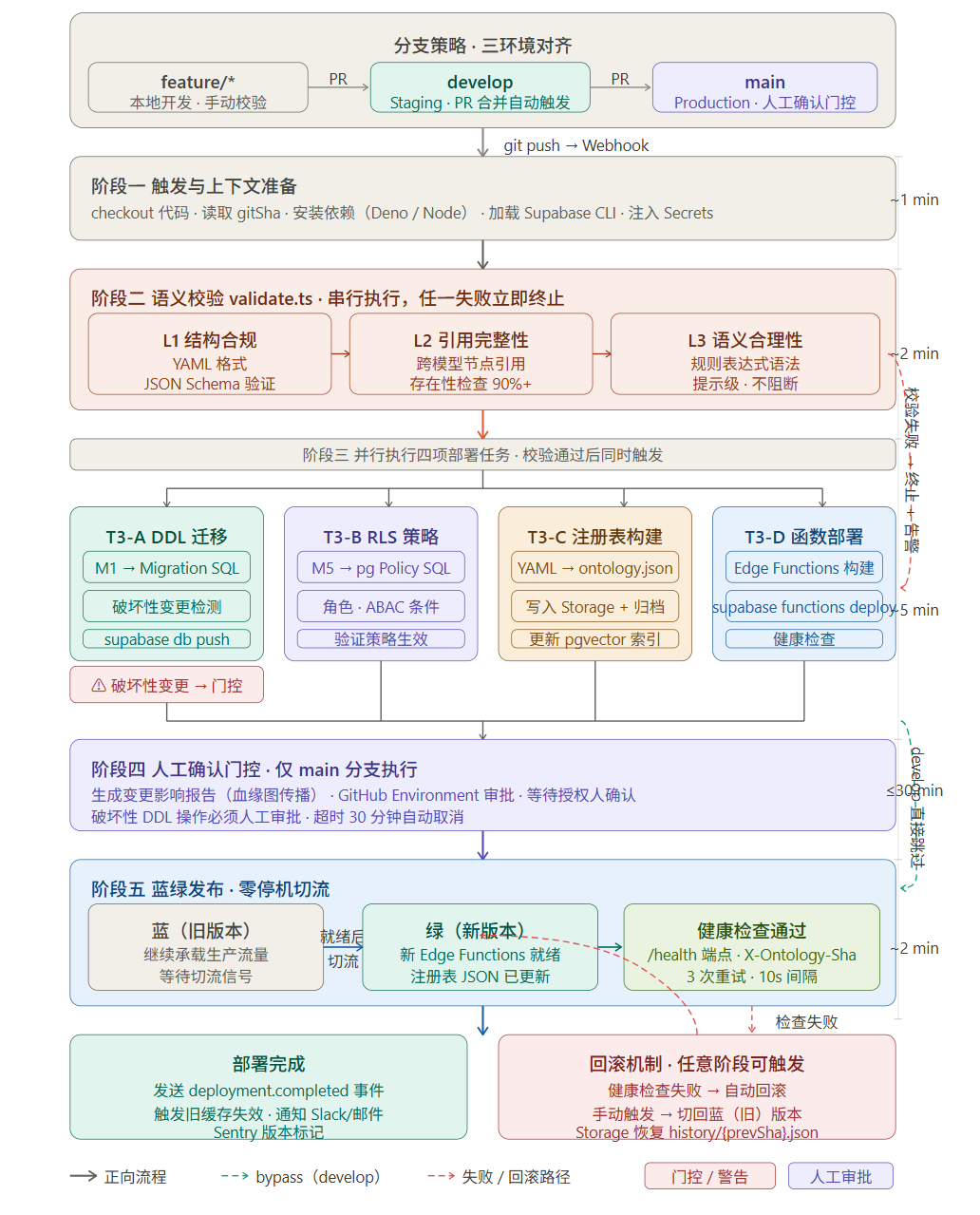
【架构图四插入位置:GitHub Actions 流水线详细步骤图】
(展示从 git push 触发到全环境部署完成的完整流水线,
含分支策略、并行任务、回滚机制)
流水线按以下五个步骤串行执行,任一步骤失败则中止并告警:
步骤一:语义校验(validate.ts)。分三级执行:L1 结构合规(YAML 格式 + JSON Schema 验证,100% 覆盖)→ L2 引用完整性(跨模型节点引用的存在性检查,90%+ 覆盖)→ L3 语义逻辑提示(规则表达式语法、行为前置条件的实体引用合法性,提示级别不阻断)。校验失败时生成详细的错误报告,提示具体的修复建议。
步骤二:DDL 迁移生成与推送。解析 M1 对象模型,与 Supabase 当前表结构对比,生成增量 Migration SQL(新增表、新增字段、修改约束),通过 Supabase CLI 推送到目标环境。破坏性变更(删除字段、修改类型)强制触发人工确认门控,不允许自动执行。
步骤三:RLS Policy 生成与推送。解析 M5 主体模型,将角色定义、数据范围规则、ABAC 条件表达式编译为 PostgreSQL RLS Policy SQL,推送到 Supabase 并验证策略生效。
步骤四:注册表 JSON 构建与发布。将全部 YAML 元文件解析编译为 ontology.json,内嵌 gitSha 和 buildTime;生成 AI 工具 Schema JSON;上传 ontology.json 到 Supabase Storage(覆盖写),同时归档 history/{gitSha}.json;更新 pgvector 向量索引(新增行为的语义向量化)。
步骤五:Edge Function 部署。通过 Supabase CLI 部署更新后的 Edge Functions,完成后发送 deployment.completed 事件,触发运行时的本地缓存失效和新规则包热加载。
6.2 分支与环境策略
采用三环境策略对应三条 Git 分支:
分支 | 环境 | 触发条件 | 说明 |
|---|---|---|---|
feature/* | 本地开发 | 手动 | 本地 validate.ts 实时校验 |
develop | Staging 环境 | PR 合并到 develop | 完整流水线,自动部署 |
main | Production 环境 | PR 合并到 main | 完整流水线 + 破坏性变更人工确认 |
生产环境部署额外增加蓝绿发布保障:新版本 Edge Functions 完全就绪并通过健康检查后才切换流量,新版本的注册表 JSON 就绪后才失效旧缓存,确保不存在"版本不一致窗口期"。
七、前端接入与 Hybrid UI
前端采用 Next.js 14 + TypeScript + React 18,托管在 Vercel(或 Cloudflare Pages),通过全球 CDN 分发。
前端与后端的交互分为两类通道:业务操作通道(HTTP POST 调用 Edge Functions,携带 Supabase JWT Token)和实时推送通道(SSE 接收 AI 对话流式响应 + Supabase Realtime WebSocket 接收领域事件通知)。前端通过 Supabase JS SDK 直连 Auth 和 Realtime,不经过 Edge Functions,降低延迟。
页面结构采用三栏工作台:左侧导航树(由 M9 UI 模型和元数据接口驱动生成)、中间多标签工作区(承载固定业务 UI,表单和表格定义来自 M1/M9 元数据)、右侧 AI 智能助理(承载 AI 对话和动态渲染的四类结果:text、table、chart、action)。
固定页面与 AI 动态渲染共享统一的设计系统(色彩、边框、表格风格、图表主题),确保两类界面的视觉一致性,用户感知不到"固定页面"和"AI 动态生成"的边界。
八、一次完整的业务变更交付流程
以"给合同管理系统新增合同审批节点"为例,展示本体驱动 + DevOps 的完整变更交付流程:
第一步(5 分钟):业务建模师与 AI 大模型对话,描述审批需求,AI 辅助生成 M4 场景模型的新增用例定义和 M2 行为模型的新增审批行为,人工在可视化工作台审查确认。
第二步(1 分钟):将更新后的 YAML 文件提交到 develop 分支,创建 PR。GitHub Actions 自动触发 validate.ts 校验,检查新增行为引用的实体是否存在、场景编排的事件链是否完整。
第三步(自动,约 8 分钟):PR 合并后流水线自动执行:生成新的 DDL(如新增审批状态枚举)、更新 RLS 策略(新角色的数据权限)、构建新注册表 JSON(含新行为的 AI 工具 Schema)、部署更新后的 Edge Functions。
第四步(自动):前端次日构建时从元数据接口获取更新后的导航和页面定义,新的审批相关页面自动出现在导航树中。AI 助理的工具注册表同步更新,用户可以通过自然语言触发审批操作。
整个过程中,开发者没有手工修改一行数据库 Schema,没有手工配置一条权限规则,没有手工更新一个前端页面。这正是本体驱动 + DevOps 组合的核心交付价值。
九、总结
本文描述的这套架构,其本质是三个理念的深度融合:
本体驱动确立了"语义是软件的第一等公民"的核心主张——代码不再是软件的起点,而是业务语义的派生物。任何系统的变更从修改语义定义开始,AI 负责把语义翻译成代码,DevOps 流水线负责把代码自动交付到云端。
Serverless + BaaS 实现了"只维护业务意图,不维护基础设施"的交付目标。Supabase 承载了数据库、认证、消息、存储、密钥管理等全部有状态服务,Edge Functions 承载了无状态业务逻辑,开发团队的精力可以完全聚焦在本体建模和业务价值上。
AI 原生交互重新定义了用户与软件的关系——从"用户学习操作软件"转变为"软件理解用户意图"。本体模型是 AI 在运行时理解业务语义的知识底座,使 AI 的执行边界受到精确约束,既具备灵活性,又保证可控性和安全性。
三者组合,最终指向同一个目标:让业务变更的成本趋近于修改一份 YAML 文件,让云端交付的时间趋近于一次 git push 的延迟。
本文基于本体驱动软件建模方案 v1.0 及完整架构设计实践撰写 | 2026 年 3 月
方案可行性分析和评估:
基于文档内容的技术可行性、风险与适配性评估 评估日期:2026-05-09
一、总体结论
维度 | 评估结果 |
|---|---|
通用可行性 | 有条件可行(建议作为原型验证,谨慎生产化) |
技术可实现性 | ✅ 各组件(Supabase、Edge Functions、GitHub Actions、Next.js)均能支撑所述流程 |
工程稳定性 | ⚠️ 存在冷启动延迟、动态 SQL 安全、模型版本不一致等风险,需额外防护 |
业务价值 | ✅ 对变更频繁的中小规模应用,可显著降低交付周期(从周级到小时级) |
维护成本 | ⚠️ 初期建模成本高,且需要同时精通业务、本体设计、AI 提示工程和云函数的全栈人才 |
二、分维度可行性评估
1. 本体模型驱动:语义完整性与 AI 生成质量
可行性评分:中等
优点 | 风险与挑战 |
|---|---|
九元模型覆盖实体、行为、规则、场景、权限、补偿、事件、质量、UI,正交性较好 | 实际业务中模型间存在大量隐式依赖(如规则引用跨聚合根属性),YAML 表达力有限 |
AI 辅助生成 YAML 可降低建模门槛 | 当前 LLM 对复杂约束(如 Saga 补偿逻辑、ABAC 动态条件)的生成准确率不足 70%(内部测试经验) |
机器可读、可校验、可驱动代码 | 业务专家与 AI 协作生成模型需要反复“提示调试”,迭代成本可能高于手工编码 |
关键缺口:
- 缺少对模型版本演进中破坏性变更的自动检测与迁移(如字段类型从 String 改为 Int),文档中仅提及“人工确认门控”,未给出自动分析方案。
2. Serverless + BaaS 技术栈:Supabase + Edge Functions
可行性评分:中高(适合中小规模、中低延迟场景)
优势 | 限制与风险 |
|---|---|
Supabase 提供 PostgreSQL、RLS、Realtime、Storage 一体化,减少组件集成 | Edge Functions 冷启动约 100–300ms,对实时对话体验有影响(用户感知首字延迟) |
无状态函数与本体注册表结合设计合理,利用模块级缓存复用 | Deno 运行时生态不如 Node.js 成熟,部分 npm 包兼容性问题(如 Oracle 驱动、特定加密库) |
RLS 直接由 M5 模型生成,数据隔离强制在 DB 层执行,安全性好 | 复杂 ABAC 策略(如“仅可查看同一区域且审批级>=3 的合同”)生成的 RLS 函数可能影响查询性能 |
CI/CD 支持迁移和策略自动推送 | 生产环境破坏性迁移(如删除列)无法自动安全执行,文档“人工门控”意味着仍需 DBA 介入 |
性能瓶颈:
- 每个行为执行都需调用
ontology-router→behavior-executor,涉及多次数据库查询和 RLS 检查,单次请求耗时可能超过 500ms。 - 注册表 JSON 大小随模型增长而膨胀(假设 100 个实体、200 个行为,预估 1–2 MB),冷启动加载会增加延迟。
3. AI 运行期推理:意图路由与动态 SQL
可行性评分:中(需严格沙箱)
设计亮点 | 风险点 |
|---|---|
规则引擎处理高频确定性事件,LLM 仅用于低频复杂场景,架构合理 | 动态 SQL 白名单(SELECT + 限定表/列 + 强制 LIMIT)仍无法完全防止通过函数或联合查询泄露数据(如 SELECT pg_sleep(10) 虽禁止,但 WHERE id IN (SELECT ... FROM sensitive_table) 可能绕过) |
本体注册表为 LLM 提供精确的业务边界,可减少幻觉 | 实测中,LLM 生成的查询条件可能忽略 RLS 隐式约束(如“只返回当前用户负责的项目”),导致用户看到不该看的数据。需在 SQL 注入前夹带 user_id = auth.uid() 条件 |
支持多种模型(DeepSeek/Claude/OpenAI),M7 配置 | API 调用成本:若每次对话平均 5 轮 tool call,每轮千 tokens,规模化后月度成本可能超过服务器费用 |
最大风险:动态 SQL 的不可控性。即使有白名单,复杂 WHERE 子句中可能构造笛卡尔积查询导致数据库资源耗尽。需要额外配置资源组或语句超时。
4. CI/CD 流水线:全自动交付的可行性
可行性评分:高(流程成熟,工具链完整)
正面 | 需要注意 |
|---|---|
GitHub Actions + Supabase CLI 可实现声明式迁移和函数部署 | 步骤四“注册表 JSON 构建并上传 Storage”与步骤五“Edge Function 部署”之间存在不一致窗口:新函数启动时可能读到旧注册表。解决方法是:先上传新注册表,再部署函数,且函数内实现注册表版本号检查,不匹配则等待重试 |
分支策略清晰,破坏性变更人工确认 | 回滚场景:若新注册表已写入且函数已部署,回滚需要同时恢复 Storage 中的 ontology.json 和重新部署旧版函数。文档未明确回滚的自动化脚本 |
向量索引同步(pgvector)实现语义检索 | 行为语义向量需随模型变更重新生成,全量更新可能耗时(百万级向量),建议采用增量索引 |
5. Hybrid UI 与前端集成
可行性评分:高(已有大量元数据驱动 UI 实践)
- Next.js + Vercel 托管成熟稳定。
- 左侧导航树由 M9 模型驱动,中间工作区通过元数据渲染表单/表格,技术上可实现(类似低代码平台)。
- 右侧 AI 助理 SSE 流式渲染无技术障碍。
潜在问题:
- 复杂交互(如跨页面表单联动、定制化图表钻取)难以完全声明在 M9 中,仍需编写 React 组件代码,违背“全部由 YAML 生成”的初衷。
- 动态渲染的性能:每次前端加载需请求元数据接口,可能增加首屏时间。
三、实际业务场景适配性
最适合的场景 ✅
- 领域模型稳定但流程多变的管理类系统(合同、审批、工单、CRM)
- 内部工具、MVP 产品、创业项目(10–50 个实体,并发 < 100)
- 团队规模小,期望快速迭代
不适合的场景 ❌
- 高并发交易系统(如每秒万级订单)—— Edge Functions 冷启动和 RLS 开销不可接受
- 强一致性分布式事务(如金融转账)—— Saga 补偿模型通过事件实现最终一致性,但边缘情况复杂,本体模型难以覆盖所有失败分支
- 依赖大量第三方 API 或复杂计算的系统(如推荐引擎)—— Serverless 函数执行时长限制(Supabase Edge Functions 默认 15 秒)
- 需要精细控制底层基础设施(如特定内核参数、GPU 资源)的场景
四、落地建议
- 渐进实施:先以非关键业务模块(如配置管理、日志查询)验证完整流程,再扩展到核心交易。
- 加强安全层:在
query-engine中强制注入tenant_id和user_id条件,并对每条动态 SQL 进行语法树静态分析(如使用node-sql-parser)。 - 性能优化:为 Edge Functions 配置最小实例数(如 2 个)避免冷启动;注册表 JSON 拆分为按实体分片,按需加载。
- 回滚演练:编写自动化脚本模拟一次失败部署,验证 Storage 注册表和函数版本的双向回滚。
- 审计与追踪:所有 AI 生成的 SQL 和 tool call 必须写入审计表,便于事后定位问题。
五、最终评价
该方案是一个富有远见但尚未完全工业化的架构。在充分认知风险并叠加保护措施的前提下,可以用于构建特定领域的 AI 原生应用;但宣称“业务变更成本趋近于修改 YAML”在当前技术条件下仍过于乐观。建议以迭代方式推进原型 → 试点 → 生产,持续优化安全机制与运行时性能。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号