从 0 到企业级私有云 | 当你走到 Observability,这套体系才真正完整

从 0 到企业级私有云 | 当你走到 Observability,这套体系才真正完整

一根头发丝的宽度
发布于 2026-05-06 20:57:35
发布于 2026-05-06 20:57:35
本文共 1100+ 字,阅读约需 6 分钟。

在过去的这段时间里,我们从零开始,一步步搭建了一套完整的企业级基础设施体系:
- Kubernetes 集群
- 存储与网络(Longhorn / Ceph)
- 监控系统(Prometheus + Grafana + Alertmanager)
- CI/CD + GitOps(Jenkins + ArgoCD)
- 私有云整体架构设计
很多人以为,到这里就结束了。
但现实是:这只是“能运行”,离“能用”还差最关键的一步。
这一步,叫做 Observability(可观测性)。
一、为什么必须做 Observability?
在企业环境中,真正的难题从来不是“部署”,而是:
- 服务为什么变慢?
- 某个接口为什么偶发报错?
- 哪个服务是瓶颈?
- 用户体验真的没下降吗?
- 出问题后,多久能定位根因?
没有可观测性 → 系统在跑,但你是盲的。
二、从 Monitoring 到 Observability:本质升级
很多人以为:
Prometheus + Grafana = 监控系统
但真正的企业级可观测性是:
Metrics + Logs + Tracing + SLO
层次 | 回答的问题 |
|---|---|
Metrics | 趋势如何? |
Logs | 具体发生了什么? |
Tracing | 请求路径如何? |
SLO | 用户满意吗? |
三、我们做了什么?补齐可观测性的四块拼图
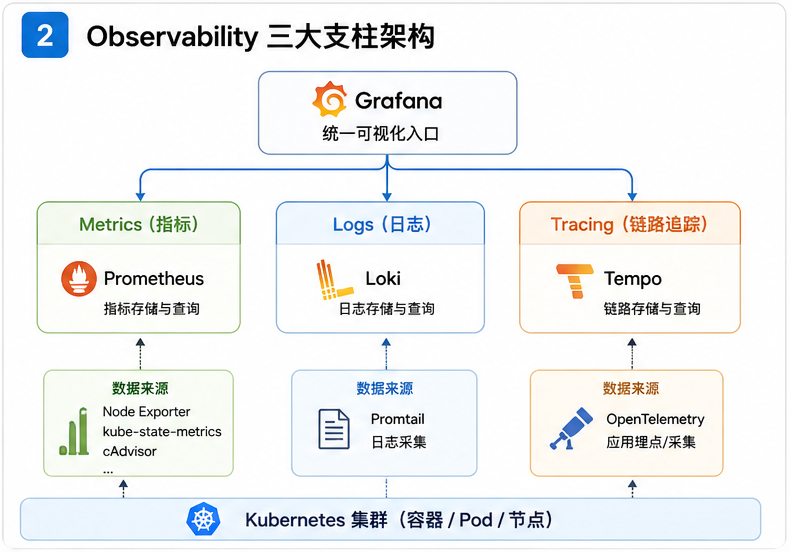
1)日志系统(Logging)
- 技术栈:Loki + Promtail + Grafana
- 能力:
- 多 Pod 日志统一采集
- 按 namespace / pod / 关键字快速检索
- 快速定位错误日志
Container → Promtail → Loki → Grafana
2)链路追踪(Tracing)
- 技术栈:Tempo + OpenTelemetry
- 能力:
- 一个请求经过哪些服务?
- 哪一步最慢?
- 错误发生在哪一层?
Trace = 一次完整请求
Span = 一个服务节点
3)APM(应用性能监控)
- 关键成果:
- Trace 可视化
- 服务调用链路
- Service Map(服务拓扑图)
frontend → api → auth → database
这将第一次真正“看见”系统是如何运行的。
4)SLI / SLO(可用性治理)
这是整个阶段的 升维点。
不再只问:“CPU 高不高?”
而是问:“用户体验达标吗?”
示例:请求成功率 ≥ 99.9%
告警不再基于资源,而基于:
- 错误率
- 延迟
- 可用性
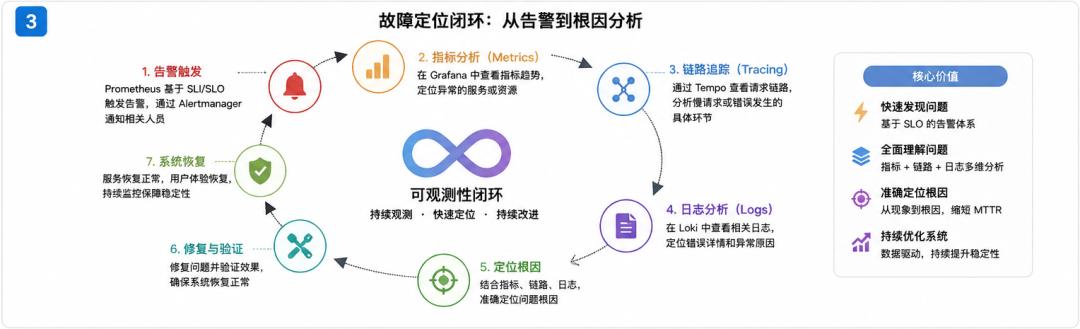
四、完整闭环:可观测性的真正价值
打通这四层之后,得到的是:
监控 → 告警 → 链路分析 → 日志定位 → 根因分析
一个端到端的故障定位闭环。
五、这一阶段的本质变化
从:
会部署系统
走向:
能理解系统
能分析问题
能定义稳定性
——这正是企业最看重的能力模型。
六、为什么 Observability 能力最“值钱”?
现实是:
- 会 K8s 的人很多
- 会 Prometheus 的人也不少
- 但真正会 Observability 的人很少
因为它要求你同时具备:
- 系统架构理解
- 分布式系统认知
- 运维与排障经验
- 数据驱动的分析能力
七、全景回顾:从 0 到企业级私有云
到现在,我们已经构建了一整套体系:
基础设施层
├── K8s 集群
├── 网络 / 存储
平台层
├── 监控系统(Prometheus)
├── 日志系统(Loki)
├── 链路追踪(Tempo)
交付层
├── CI/CD(Jenkins)
├── GitOps(ArgoCD)
治理层
├── SLO
├── 告警体系
这不再是一个“实验项目”,
而是一套 完整、可落地、可治理的企业级云原生基础设施模型。
八、接下来做什么?
接下来,将逐一进行实操部署:
- Loki 实战
- Tempo 实战
- OpenTelemetry 接入
- Service Map 构建
- SLO 设计与告警
👉 欢迎持续关注。
九、最后一句总结
前面的阶段解决的是:如何把系统跑起来Observability 解决的是:如何真正掌控系统
而这,才是企业级能力的核心。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号