从0搭建企业私有云|Alertmanager 架构完全解析:告警中枢的设计哲学与高可用实战

从0搭建企业私有云|Alertmanager 架构完全解析:告警中枢的设计哲学与高可用实战

一根头发丝的宽度
发布于 2026-05-06 20:46:17
发布于 2026-05-06 20:46:17
📖 本文约 2100+ 字 | 阅读约需 9 分钟 你将了解到:
- Alertmanager 在 K8s 告警体系中的核心位置
- 配置传递的三种方式(YAML / Secret / Helm)
- 内部处理流程:接收 → 抑制 → 分组 → 路由 → 通知
- 高可用 Gossip 协议原理
- 结合实战,理解为什么“收不到告警”
一、为什么你需要理解 Alertmanager 的架构?
在上一篇实战中,我们成功打通了:
Prometheus → Alertmanager → Email
部分读者可能会疑问:
- “我改了配置为什么不生效?”
- “两个 Alertmanager 实例之间怎么同步的?”
- “静默(Silence)存在哪里?”
👉 这些问题,只有理解了 Alertmanager 的架构才能彻底明白。
二、Alertmanager 在 K8s 告警体系中的位置
- Prometheus负责“发现问题”:执行告警规则 → 产生告警 → 推送给 Alertmanager
- Alertmanager负责“怎么通知”:去重、分组、路由、抑制 → 调用通知渠道
三、核心问题:Alertmanager 的配置到底怎么来的?
很多初学者以为 Alertmanager 的配置是写在 Pod 里的,其实不是。
3.1 配置的三种形态
部署方式 | 配置形式 | 优点 |
|---|---|---|
二进制 / 裸机 | 直接写 alertmanager.yml | 简单直观 |
原生 Kubernetes | Secret 挂载 | 符合 K8s 规范,可版本管理 |
kube-prometheus-stack(Helm) | values.yaml → 自动生成 Secret | 统一管理,支持热加载 |
3.2 上一篇实战中做的事情(本质拆解)
执行的命令:
kubectl create secret generic alertmanager-monitoring-kube-prometheus-alertmanager \
--from-file=alertmanager.yaml -n monitoring \
--dry-run=client -o yaml | kubectl apply -f -
实际上就是在做:
文件 alertmanager.yaml (SMTP配置)
↓
K8s Secret (data.alertmanager.yaml)
↓
Alertmanager Pod 挂载 /etc/alertmanager/config
↓
Alertmanager 进程读取并生效
验证方法:
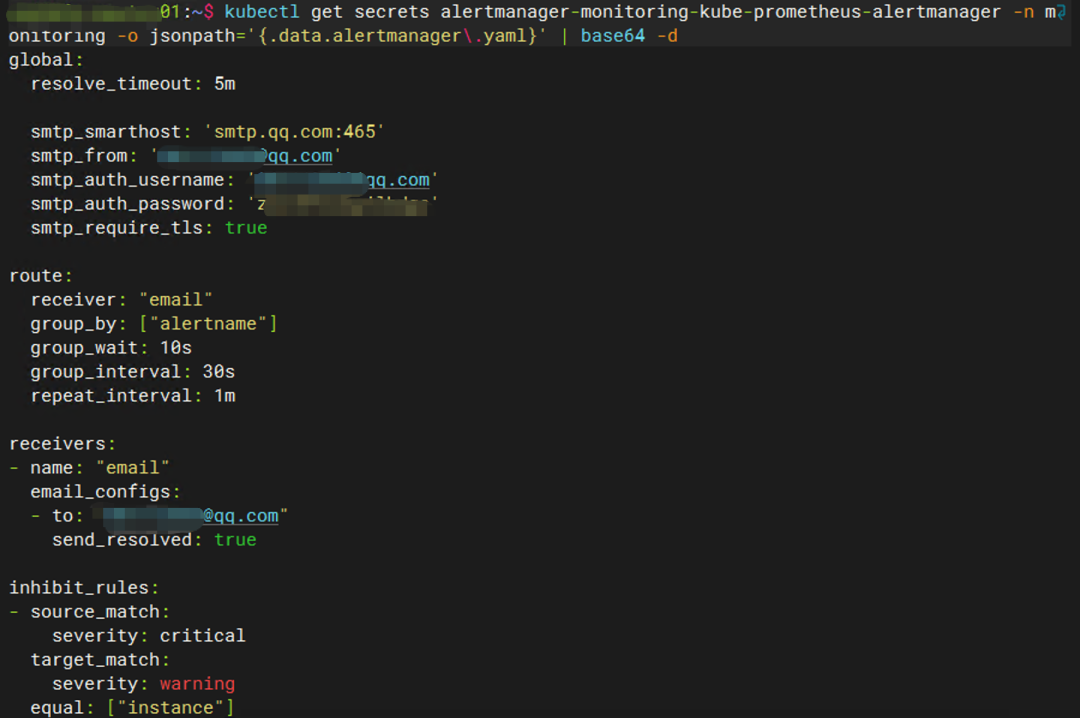
kubectl get secret alertmanager-kube-prometheus-alertmanager -n monitoring -o jsonpath='{.data.alertmanager\.yaml}' | base64 -d
你会看到你写的原始 YAML 内容。
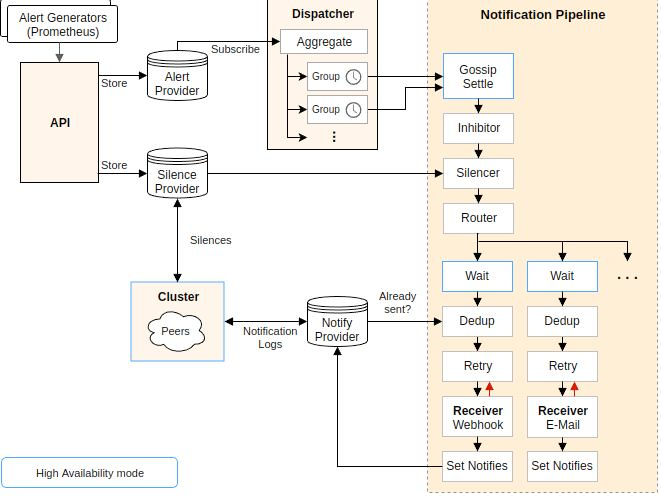
四、Alertmanager 内部架构(一张大图 + 逐层拆解)
这是本文最核心的部分。
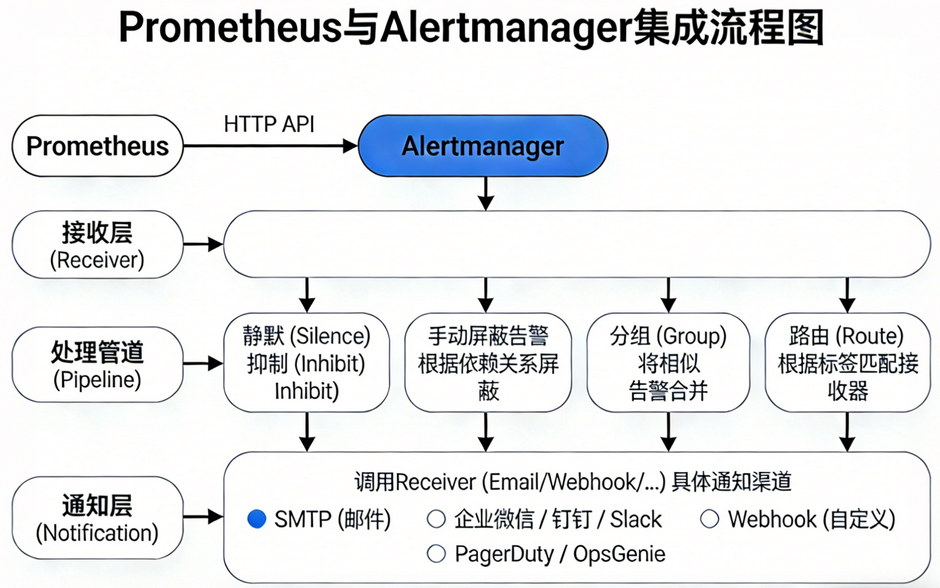
4.1 接收层(Receiver)
- Alertmanager 暴露一个 HTTP API,路径通常是
/api/v2/alerts - Prometheus 通过
--alertmanager.url将告警 POST 过来
4.2 静默(Silence)
- 作用:人工临时屏蔽某个告警(例如正在维护,不想被骚扰)
- 存储:默认在内存中,重启丢失;可配置持久化存储(如本地文件或对象存储)
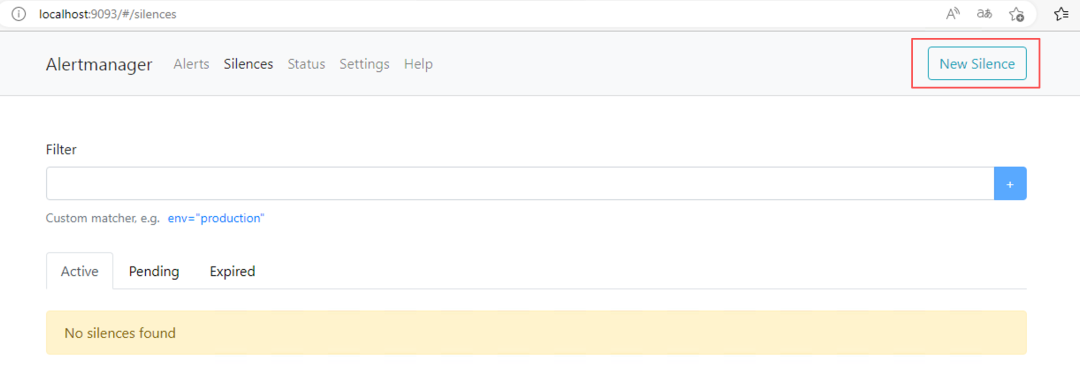
- 创建方式:Alertmanager UI → New Silence
👉 你之前收不到邮件?检查是否创建了匹配的静默规则。
4.3 抑制(Inhibit)
- 作用:当某个“根源告警”触发时,抑制其他“衍生告警”
- 典型场景:主机宕机 → 该主机上的所有服务不可达告警应该被抑制
配置示例:
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['instance']
意思是:如果同一个 instance上出现了 critical告警,则抑制所有 warning告警。
4.4 分组(Group)
- 作用:将短时间内产生的相似告警合并成一条通知
- 参数:
group_by:按哪些标签分组(如alertname、cluster)group_wait:等待第一批告警的时间(默认 30s)group_interval:同一组告警发送新通知的最小间隔(默认 5m)repeat_interval:无新告警时重复发送的间隔(默认 4h)
为什么要分组?如果没有分组,一个大规模故障可能瞬间产生几百条告警,你的邮箱会被炸掉。
👉 在上一篇实战中配置了:
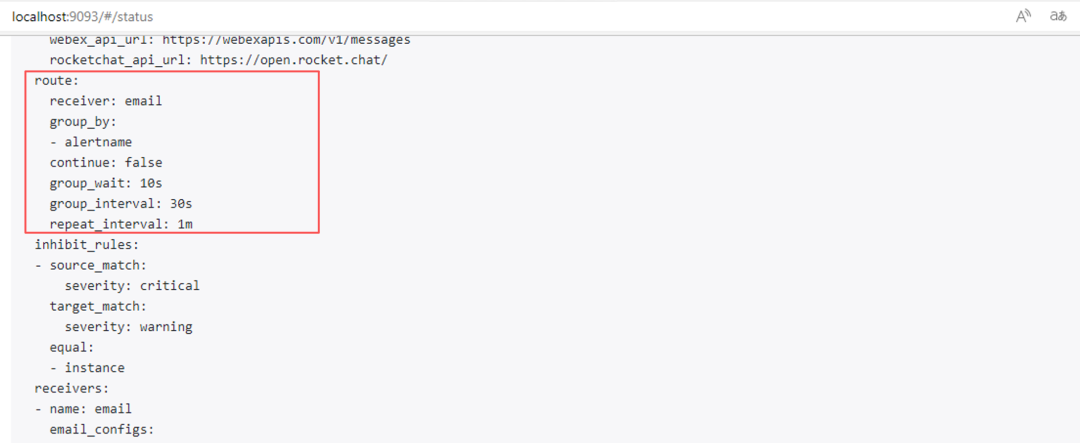
group_by: ["alertname"]
group_wait: 10s
group_interval: 30s
repeat_interval: 1m
所以 AlwaysFiring告警会每 1 分钟发一次邮件。
4.5 路由(Route)
- 作用:根据告警的标签,决定走哪个“接收器”(receiver)
- 支持树形结构:可以有多级路由,实现不同团队、不同级别发送到不同地方
示例:
route:
receiver:'default'
group_by:['alertname']
routes:
-match:
severity:critical
receiver:'pager'
-match:
team:'platform'
receiver:'email-platform'
4.6 通知层(Notification)
- 根据路由匹配到的 receiver 名称,调用对应的通知配置
- 每个 receiver 可以有多个通知方式(例如同时发邮件和钉钉)
五、高可用架构:为什么你要部署多个 Alertmanager?
在生产环境中,你不会只跑一个 Alertmanager Pod,而是会跑 2~3 个副本。
5.1 问题:多个实例之间如何同步静默和抑制?
因为静默(Silence)是用户通过 UI 或 API 动态创建的,如果只存在某一个实例的内存里,其他实例不知道,就会导致:
- 你在实例 A 上创建了静默,但告警发给了实例 B → 静默不生效
解决方案:Gossip 协议
Prometheus
/ \
/ \
Alertmanager-1 ←──→ Alertmanager-2 (Gossip 同步)
\ /
\ /
共享存储 (可选)
- 所有 Alertmanager 实例通过 Gossip 协议实时交换静默和抑制状态
- 不需要共享数据库,任何实例都可以处理告警和静默
- Prometheus 通常会配置向所有实n例发送告警(通过
--alertmanager.url=a1,a2,a3)
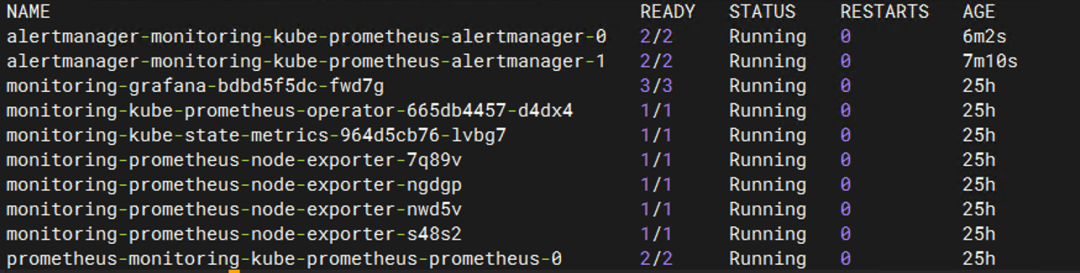
5.2 验证你集群的高可用
kubectl get pod -n monitoring
如果你看到多个 alertmanager-xxxPod,说明已经开启了高可用。
六、常见架构误区与真相(对照你的实战)
七、从架构角度回顾此实验
在上一篇做了这些事:
- 创建了一个 100% 触发的告警规则→ 验证 Prometheus 能产生告警
- 配置了 Alertmanager 的 SMTP→ 修改了配置(实际修改了 Secret)
- 重启了 Alertmanager Pod→ 让新配置生效
- 收到邮件→ 验证了路由、分组、通知层工作正常
现在回头看:
- 为什么
group_wait: 10s你等了 30 秒才收到邮件?因为还要加上 Prometheus 的for: 30s和评估周期 - 为什么只收到了 1 封邮件而不是一直发?因为
repeat_interval: 1m控制重复频率
八、总结:一张脑图记住 Alertmanager
Alertmanager = 告警的“邮局”
1. 收件 (API)
2. 处理 (静默 → 抑制 → 分组 → 路由)
3. 派送 (Email/Webhook/...)
高可用 = 多个邮局之间用 Gossip 互相通知“谁被退信了”
九、下一步预告
在理解了 Alertmanager 架构后,可继续深入:
- 高级路由:根据告警标签发送到不同团队
- 告警分级与抑制策略:减少无效告警
- 自定义 Webhook:对接内部工单系统
十、写在最后
Alertmanager 的本质并不复杂:配置由 YAML 定义(K8s 中通过 Secret 挂载),处理流程是“接收 → 抑制 → 分组 → 路由 → 通知”,高可用靠 Gossip 协议同步状态。理解了这个脉络,你就能轻松驾驭它。
如果你觉得这篇文章帮你理清了 Alertmanager 的脉络,欢迎点个 👍 或分享给需要的朋友。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号