终于有人把 Doris / SelectDB 说明白了!面向 AI 的极速分析与搜索数据库

终于有人把 Doris / SelectDB 说明白了!面向 AI 的极速分析与搜索数据库

一臻数据
发布于 2026-04-21 20:39:30
发布于 2026-04-21 20:39:30
见字如面,我是一
“午间,数据科学家小李正盯着屏幕上卡住的进度条“这AI模型还等着我的用户向量数据做检索召回呢,结果查询慢成这样,明天汇报怎么办?”他低声抱怨。 旁边的同事小王走过来,递给他一份新部署文档:“别急,试试 Apache Doris 4.0。我上周在项目里用过,数据从写入到分析搜索,全程秒级响应,混合检索一次搞定。” 小李半信半疑地点点头,心里却涌起一丝期待——终于不用再为数据延迟头疼了。
Apache Doris作为开源 AI检索分析数据库,从4.0版本开始就把向量搜索、全文检索和结构化分析统一到一个引擎里,SelectDB则在此基础上提供私有化和云原生企业版本。可谓真正实现了面向AI的极速分析与搜索,一条SQL就能处理混合负载,落地效率直接拉满。

Doris的核心AI原生能力
Apache Doris从4.0版本起正式引入向量索引,支持HNSW和IVF两种ANN算法,向量数据以固定长度数组形式存储,无需额外数据类型。
结合原生SQL,你可以直接在同一查询里完成向量相似度搜索、关键词精确匹配和多维聚合分析。
这就是 混合检索与分析(HSAP) 的落地形式——既保证语义召回,又保留结构化过滤的精准性。
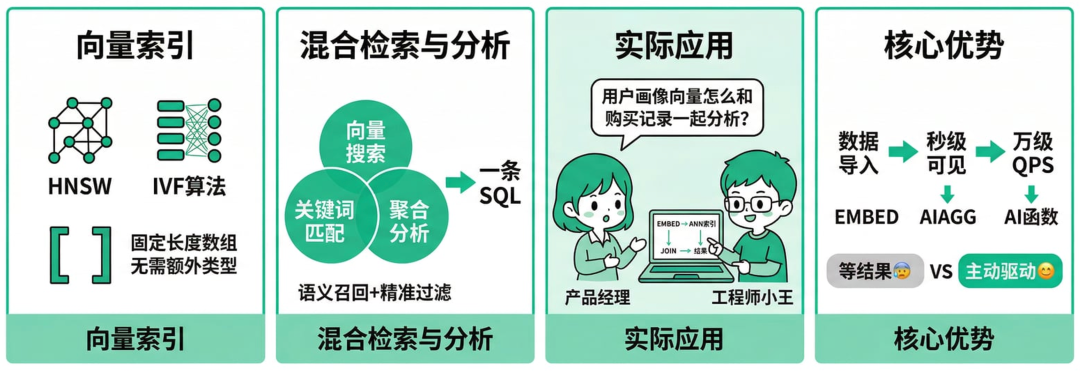
举个实际对话场景:
团队晨会上,产品经理问:“用户画像向量怎么和最近购买记录一起分析?”
工程师小王直接敲代码演示:“看这条SQL,EMBED函数把文本转向量,ANN索引秒搜相似用户,再JOIN结构化表过滤,最后聚合出推荐列表,整个过程库内完成,不用出库调用外部API。”
#建表
-- 用户画像表(存储描述文本的向量,带 HNSW ANN 索引)
CREATE TABLE user_profiles (
user_id BIGINT NOT NULL,
user_desc STRING,
embedding ARRAY<FLOAT> NOT NULL,
INDEX ann_idx (embedding) USING ANN PROPERTIES (
"index_type" = "hnsw",
"metric_type" = "l2_distance",
"dim" = "768"
)
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 8
PROPERTIES ("replication_num" = "1");
-- 结构化用户行为表(购买记录)
CREATE TABLE user_orders (
user_id BIGINT,
product_id BIGINT,
product_category VARCHAR(100),
purchase_amount DOUBLE
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 8
PROPERTIES ("replication_num" = "1");
#写入向量数据(使用 EMBED 函数)
SET default_ai_resource = 'your_embed_resource';
INSERT INTO user_profiles (user_id, user_desc, embedding) VALUES
(1, '年轻科技爱好者,喜欢游戏和数码产品', EMBED('年轻科技爱好者,喜欢游戏和数码产品')),
(2, '户外运动达人,热爱跑步和登山', EMBED('户外运动达人,热爱跑步和登山')),
(3, '科技宅,喜欢编程和电子产品', EMBED('科技宅,喜欢编程和电子产品'));
#核心推荐查询
-- EMBED 文本 → ANN 搜相似用户 → JOIN 结构化表 → 聚合推荐品类
SELECT
o.product_category,
COUNT(DISTINCT u.user_id) AS similar_user_count,
AVG(o.purchase_amount) AS avg_purchase_amount,
SUM(o.purchase_amount) AS total_purchase_amount
FROM user_profiles u
JOIN user_orders o ON u.user_id = o.user_id
WHERE l2_distance_approximate(
u.embedding,
EMBED('喜欢科技产品和游戏的年轻用户') -- 文本实时转向量
) < 0.5 -- ANN 索引加速过滤相似用户
GROUP BY o.product_category
ORDER BY similar_user_count DESC
LIMIT 10;
小李当时眼睛亮了——以前要跨系统拼数据,现在一条语句全解决,开发周期从几天缩短到小时。
Doris的实时导入能力也值得一提。
通过Kafka或Flink等多种方式,数据产生后秒级可见,高并发查询支持万级QPS,ClickBench榜单多项指标领先。
AI函数进一步让数据库灵活起来:内置EMBED生成嵌入、AIAGG做文本聚合,还能直接在SQL里调用大模型完成情感分析或摘要提取。
数据工程师的心理变化很真实——从过去等结果到如今AI+主动驱动,那种掌控感,让加班都少了很多。
SelectDB的云原生AI增强
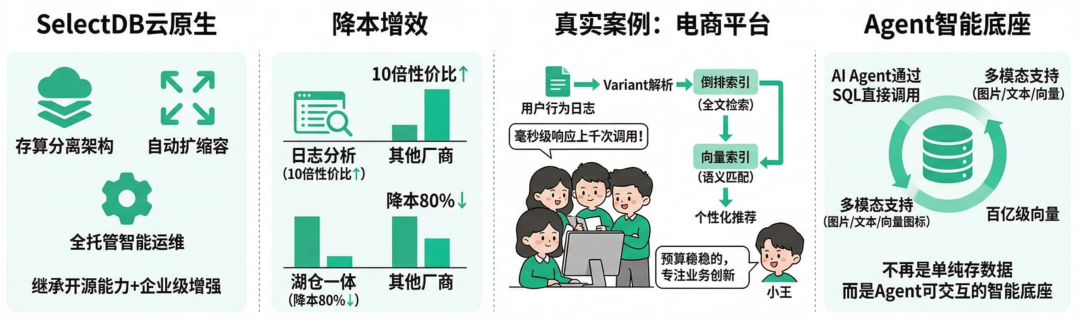
SelectDB 由 Apache Doris 原创团队打造,包含私有化和云原生版本。其商业化云服务版,继承全部开源能力,同时补齐企业级痛点:存算分离架构、自动扩缩容、全托管智能运维。
多家Top企业的应用,在日志分析场景下,它能实现近10倍性价比,湖仓一体分析最高降本80%。
在一家电商平台的真实案例中,运营团队需要实时处理用户行为日志,提取向量后做个性化推荐。
以前数据孤岛严重,AI模型训练常因延迟卡壳。
切换SelectDB后,Variant半结构化字段轻松解析,倒排索引支持全文检索,向量索引则精准匹配语义相似商品。
AI Agent甚至能通过SQL直接调用最新数据做决策,毫秒级响应上千次调用。小王后来分享:“以前担心云上成本,现在SelectDB的自动优化让预算稳稳的,团队专注业务创新,不再纠结基础设施。”
这种融合统一的设计,客观上解决了AI时代数据基础设施的根本变化——不再是单纯存数据,而是成为Agent可直接交互的智能底座。
多模态支持也在持续增强,未来百亿级向量也能高效落盘检索。
业务场景中的落地价值
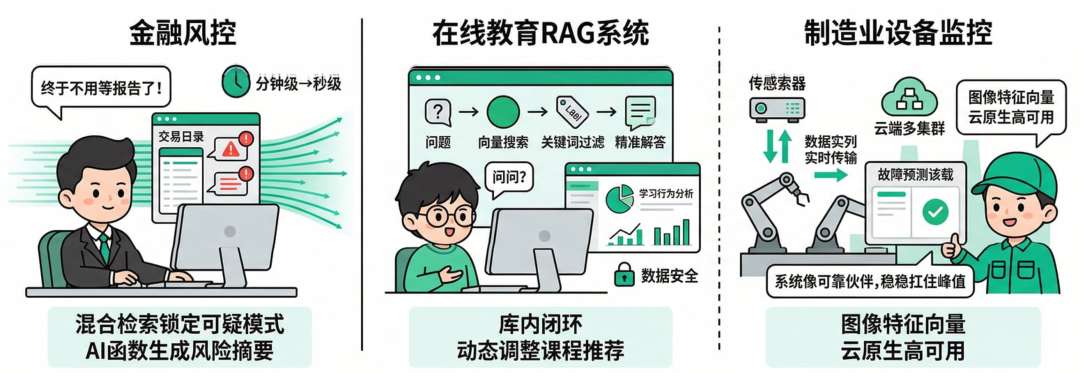
回想常见的一些 Data+AI 项目痛点,大家会不会也有共鸣?
1. 在金融风控里,海量交易日志需要即时异常检测:Doris/SelectDB 用混合检索快速锁定可疑模式,AI函数辅助生成风险摘要,决策时间从分钟级压到秒级,业务方反馈“终于不用等报告了”。
2. 在线教育平台则用它构建知识库RAG系统。
学生提问时,系统先用向量搜索语义相近内容,再叠加关键词过滤结构化课程标签,最后返回精准答案。
教师后台还能实时分析学习行为向量,动态调整课程推荐。
整个流程库内闭环,减少了数据泄露风险,也让产品迭代更快。
3. 另一个场景是制造业设备监控。
传感器数据实时入库,结合图像特征向量做故障预测。
SelectDB的AI+云原生特性让多集群扩展无感,高可用保障生产不中断。
团队成员常说:“以前数据一多就慌,现在系统像可靠伙伴一样,稳稳扛住峰值。”
这些场景里,技术早已不再是瓶颈了,似乎逐渐真正把AI从概念推向规模化价值。
结语
随着AI Agent和多模态应用的普及,数据底座必须同时具备实时极速、融合统一和AI-Ready 三大特质。
Apache Doris -> SelectDB,正以统一引擎、高性能混合检索和云原生便利性,帮企业和开发者省掉层层架构,加速从数据到智能的闭环。
不久,这样的技术必然会让每一次查询都更加地智能且自然服务于业务决策,真正把数据变成生产力。
各位小伙伴觉着呢?
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号