【Python基础】(五)Python 库使用全攻略:从标准库到第三方库,让开发效率翻倍

【Python基础】(五)Python 库使用全攻略:从标准库到第三方库,让开发效率翻倍

_OP_CHEN
发布于 2026-01-14 12:13:04
发布于 2026-01-14 12:13:04

前言
荀子曰:"君子性非异也,善假于物也"。对于 Python 开发者而言,"物" 便是那些千千万万的优秀库 —— 别人早已写好的代码,我们拿来就能用,无需重复 "造轮子"。Python 能成为如今最流行的编程语言之一,除了简洁易懂的语法,更离不开其生态完备的库体系。无论是日常数据处理、网络编程,还是复杂的可视化、人工智能开发,都有对应的库为我们保驾护航。 这篇博客将从库的基础概念出发,详细拆解标准库与第三方库的使用方法,带你从入门到精通 Python 库的应用。全文干货满满,建议收藏慢慢研读!下面就让我们正式开始吧!
一、Python 库的核心认知:什么是库?为什么要用库?
1.1 库的本质:现成的 "代码工具箱"
简单来说,Python 库就是一组预先编写好的代码集合,包含了函数、类、变量等,专门用于解决某一类特定问题。就像我们做饭时不需要自己种蔬菜、磨面粉,直接去超市买现成的食材就能快速烹饪 —— 使用库,就是直接调用别人已经验证过的优质代码,省去从零开发的时间和精力。
比如我们要实现 "计算两个日期的间隔天数",如果自己手写代码,需要处理闰年、每个月的天数差异等复杂逻辑,稍有不慎就会出错;但如果使用 Python 内置的datetime库,几行代码就能搞定,既高效又可靠。

1.2 库的分类:标准库 vs 第三方库
Python 的库主要分为两大类,二者各有侧重,共同构成了 Python 强大的生态系统:
(1)标准库:Python 自带的 "基础工具箱"
标准库是 Python 安装包自带的库,无需额外安装,开箱即用。就像买手机时自带的基础功能(打电话、发短信),满足日常开发的核心需求。Python 的标准库非常丰富,覆盖了几乎所有基础开发场景,主要包括:
- 内置函数与类型:如
print()、len()、字符串str、列表list等,无需导入可直接使用; - 文本处理:字符串拼接、分割、正则匹配等;
- 时间日期:日期构造、时间差计算、格式转换等;
- 数学计算:三角函数、随机数生成、数值运算等;
- 文件目录:文件读写、目录遍历、路径操作等;
- 数据存储:数据库连接、JSON 序列化等;
- 加密解密:MD5、SHA 等哈希算法;
- 操作系统交互:进程管理、环境变量操作等;
- 并发编程:多进程、多线程、协程等;
- 网络编程:HTTP 请求、Socket 通信等;
- 图形化界面:Tkinter 等基础 GUI 工具。
我们不需要死记硬背标准库的所有功能,只需大概了解其覆盖范围,用到时查阅官方文档(Python 3.10 标准库文档)即可。
(2)第三方库:全球开发者共建的 "扩展工具箱"
标准库虽强,但无法覆盖所有细分场景(比如生成二维码、操作 Excel、机器学习等)。这时就需要第三方库 —— 由全球 Python 开发者贡献的开源库,托管在PyPI(Python Package Index)上,相当于一个巨大的 "应用商店",你需要什么功能,几乎都能找到对应的库。
第三方库的优势在于:
- 针对性强:专门解决某一细分问题,功能更专业(如
pandas处理数据、requests发送网络请求); - 更新迭代快:由社区持续维护,不断修复 bug、增加新功能;
- 开箱即用:经过大量用户验证,稳定性有保障。
使用第三方库的核心流程是:确定需求→找到合适的库→用 pip 安装→导入使用,后面会详细拆解这个流程。
1.3 使用库的核心优势:效率翻倍的关键
为什么高手写代码又快又好?核心原因之一就是善于用库。使用库的优势主要体现在:
- 节省开发时间:避免重复编写基础代码,把精力集中在核心业务逻辑上;
- 提升代码质量:库的代码经过大量测试和优化,比自己手写的代码更稳定、效率更高;
- 降低学习成本:无需深入掌握某一领域的底层原理,只需学会库的 API 调用即可实现功能;
- 增强程序扩展性:库的功能往往很丰富,后续需要扩展功能时,可直接调用库的其他接口。
比如要实现 "生成二维码",如果自己从零开发,需要掌握二维码的编码规则、图像生成等知识,难度极大;但使用qrcode库,只需 3 行代码就能生成二维码,门槛极低。
二、标准库实战:内置工具的高效用法
标准库是 Python 的基本功,掌握常用标准库的用法,能解决日常开发中 80% 的问题。下面结合 4 个高频场景,带你实战标准库的核心用法。
2.1 日期时间处理:datetime库(计算日期差、格式转换)
日常开发中,日期时间处理是高频需求(如计算两个日期的间隔、格式化日期字符串等),datetime库是处理这类问题的利器。
实战需求:计算你和心爱的人认识多少天
比如你和 TA 在 2012 年 2 月 14 日相识,想知道到 2022 年 7 月 12 日一共认识了多少天,用datetime库只需 5 行代码:
# 导入datetime模块
import datetime
# 构造两个日期对象(参数格式:年、月、日)
date1 = datetime.datetime(2012, 2, 14) # 相识日期
date2 = datetime.datetime(2022, 7, 12) # 目标日期
# 两个日期对象直接相减,得到时间差
time_diff = date2 - date1
# 输出结果(days属性获取天数)
print(f"相识天数:{time_diff.days} 天")·运行结果:
相识天数:3801 天扩展用法:日期格式化与解析
除了计算日期差,datetime库还支持日期与字符串的相互转换,这在处理日志、数据库存储时非常有用:
import datetime
# 1. 获取当前日期时间
now = datetime.datetime.now()
print("当前日期时间(默认格式):", now) # 输出:2024-05-20 14:30:00.123456
# 2. 日期格式化为字符串(strftime方法)
# 格式化规则:%Y(4位年)、%m(2位月)、%d(2位日)、%H(24小时)、%M(分钟)、%S(秒)
now_str = now.strftime("%Y-%m-%d %H:%M:%S")
print("格式化后:", now_str) # 输出:2024-05-20 14:30:00
# 3. 字符串解析为日期(strptime方法)
date_str = "2024-01-01"
date_obj = datetime.datetime.strptime(date_str, "%Y-%m-%d")
print("解析后的日期对象:", date_obj) # 输出:2024-01-01 00:00:00官方文档:datetime 库详细用法
2.2 字符串操作:内置字符串方法(解决 LeetCode 经典题)
字符串是 Python 的内置类型,其自带的方法(无需导入库)就能解决大部分字符串处理需求。下面结合 3 道 LeetCode 经典题,实战字符串方法的用法。
实战 1:翻转单词顺序(LeetCode 剑指 Offer 58)
题目链接:https://leetcode.cn/problems/fan-zhuan-dan-ci-shun-xu-lcof/description/

题目:输入一个英文句子,翻转句子中单词的顺序,但单词内字符的顺序不变。例如输入 "I am a student.",输出 "student. a am I"。
解题思路:使用split()分割字符串→reverse()反转列表→join()拼接字符串:
def reverse_words(s):
# split()默认以空格分割,自动忽略首尾空格和多个连续空格
tokens = s.split()
# 反转列表中的单词顺序
tokens.reverse()
# 用空格拼接列表中的单词
return ' '.join(tokens)
# 测试
print(reverse_words("I am a student. ")) # 输出:student. a am I
print(reverse_words(" Hello world! ")) # 输出:world! Hello实战 2:旋转字符串(LeetCode 796)
题目链接:https://leetcode.cn/problems/rotate-string/description/

题目:给定两个字符串s和goal,如果在若干次旋转操作后s能变成goal,返回True。旋转操作是将s最左边的字符移动到最右边(如s="abcde",旋转一次为"bcdea")。
解题思路:如果s旋转后能得到goal,则goal一定是s+s的子串(如s="abcde",s+s="abcdeabcde",旋转后的"cdeab"是其子串):
def rotate_string(s, goal):
# 首先判断长度是否一致,不一致直接返回False
return len(s) == len(goal) and goal in s + s
# 测试
print(rotate_string("abcde", "cdeab")) # 输出:True
print(rotate_string("abcde", "abced")) # 输出:False实战 3:统计前缀字符串数目(LeetCode 2255)
题目链接:https://leetcode.cn/problems/count-prefixes-of-a-given-string/description/

题目:给定字符串数组words和字符串s,返回words中是s前缀的字符串数目(前缀是出现在字符串开头的连续子串)。
解题思路:遍历words,使用startswith()方法判断是否为s的前缀:
def count_prefixes(words, s):
count = 0
for word in words:
# startswith()判断word是否是s的前缀
if s.startswith(word):
count += 1
return count
# 测试
words = ["a", "b", "c", "ab", "bc", "abc"]
s = "abc"
print(count_prefixes(words, s)) # 输出:3("a"、"ab"、"abc"都是前缀)字符串方法总结:
- 分割:
split(sep)—— 按指定分隔符分割字符串; - 拼接:
join(iterable)—— 用字符串拼接可迭代对象; - 前缀 / 后缀判断:
startswith(prefix)、endswith(suffix); - 替换:
replace(old, new)—— 替换字符串中的指定子串; - 去除空格:
strip()—— 去除首尾空格,lstrip()/rstrip()去除左 / 右空格。
官方文档:字符串方法详细列表
2.3 文件查找工具:os库(递归遍历目录)
os库是 Python 与操作系统交互的核心库,其中os.walk()方法能递归遍历指定目录下的所有文件和子目录,非常适合实现 "文件查找" 功能。
实战需求:根据关键词查找指定目录下的文件
比如你想在D:/project目录下查找所有文件名包含 "report" 的文件,用os.walk()就能实现:
import os
def search_files_by_keyword():
# 输入待搜索路径和关键词
input_path = input("请输入待搜索路径(如D:/project):")
keyword = input("请输入待搜索关键词(如report):")
# 验证路径是否存在
if not os.path.exists(input_path):
print("路径不存在,请检查输入!")
return
# os.walk()递归遍历目录:返回(当前路径, 子目录列表, 文件列表)
for dirpath, dirnames, filenames in os.walk(input_path):
# 遍历当前目录下的所有文件
for filename in filenames:
# 判断文件名是否包含关键词
if keyword in filename:
# 拼接完整路径并输出
full_path = os.path.join(dirpath, filename)
print(f"找到文件:{full_path}")
# 执行查找
search_files_by_keyword()运行示例:
请输入待搜索路径(如D:/project):D:/test
请输入待搜索关键词(如report):data
找到文件:D:/test/2024_data.csv
找到文件:D:/test/backup/data_202405.txt
找到文件:D:/test/docs/data_analysis.docx核心函数解析:
os.path.exists(path):判断路径是否存在;os.walk(path):递归遍历路径,返回三元组(当前路径、子目录列表、文件列表);os.path.join(dirpath, filename):拼接目录和文件名,生成完整路径(避免手动拼接路径分隔符出错)。
官方文档:os 库详细用法
2.4 数学计算:math库(三角函数、随机数、常量)
math库提供了丰富的数学运算功能,涵盖三角函数、对数函数、随机数生成、常量定义等,满足科学计算的基本需求。
实战示例:数学运算常用功能
import math
import random # 随机数模块(属于标准库)
# 1. 常量
print("圆周率π:", math.pi) # 输出:3.141592653589793
print("自然常数e:", math.e) # 输出:2.718281828459045
# 2. 三角函数(弧度制)
print("sin(π/2):", math.sin(math.pi/2)) # 输出:1.0
print("cos(π):", math.cos(math.pi)) # 输出:-1.0
print("tan(π/4):", math.tan(math.pi/4)) # 输出:1.0
# 3. 对数与指数
print("ln(10):", math.log(10)) # 自然对数,输出:2.302585093
print("log10(100):", math.log10(100)) # 以10为底,输出:2.0
print("e^2:", math.exp(2)) # 指数运算,输出:7.38905609893
# 4. 数值运算
print("绝对值:", math.fabs(-10.5)) # 输出:10.5
print("向上取整:", math.ceil(3.2)) # 输出:4
print("向下取整:", math.floor(3.8)) # 输出:3
print("四舍五入:", round(3.456, 2)) # 输出:3.46(round是内置函数)
print("阶乘:", math.factorial(5)) # 输出:120(5×4×3×2×1)
# 5. 随机数生成
print("0-1之间的随机浮点数:", random.random()) # 输出:0.345678...
print("1-10之间的随机整数:", random.randint(1, 10)) # 输出:5(示例)
print("从列表中随机选择一个元素:", random.choice(["a", "b", "c"])) # 输出:b(示例)注意事项:
math库的三角函数默认使用弧度制,如果需要用角度制,需先通过math.radians(angle)将角度转换为弧度;- 随机数模块是
random(独立于math库),常用于模拟、抽样等场景。
三、第三方库实战:解锁更多高级功能
如果说标准库是 "基础工具箱",第三方库就是 "专业工具箱"。下面带你掌握第三方库的核心使用流程(找库→安装→使用),并结合 3 个高频实战案例,让你快速上手。
3.1 第三方库使用流程:3 步搞定
步骤 1:找到合适的库
当遇到标准库无法解决的需求时,如何找到对应的第三方库?推荐 3 个方法:
- 搜索引擎:直接百度 / Bing 搜索 "Python + 需求"(如 "Python 生成二维码"),通常会找到相关库推荐;
- PyPI 官网:https://pypi.org/,Python 官方第三方库仓库,可搜索库名查看详情;

- 社区推荐:GitHub、CSDN、知乎等平台,看其他开发者的实战分享。
步骤 2:用 pip 安装库
pip 是 Python 内置的包管理器(类似手机的应用商店),用于安装、卸载、管理第三方库。安装 Python 时,pip 会自动附带(需勾选 "Add Python 3.10 to PATH")。
(1)pip 基本命令
- 安装库:
pip install 库名(如pip install qrcode); - 安装指定版本:
pip install 库名==版本号(如pip install xlrd==1.2.0); - 卸载库:
pip uninstall 库名; - 查看已安装的库:
pip list; - 升级 pip:
pip install --upgrade pip(解决 pip 版本过低的警告)。
(2)常见问题解决
问题 1:命令行输入pip提示 "不是内部或外部命令"?解决:Python 安装时未勾选 "Add Python to PATH",需手动将 Python 安装目录下的Scripts文件夹添加到系统环境变量,或卸载重装 Python(记得勾选该选项)。
问题 2:安装库时速度慢、超时?解决:使用国内镜像源(如阿里云、清华源),命令格式:pip install 库名 -i 镜像源地址,示例:
# 阿里云镜像
pip install qrcode -i https://mirrors.aliyun.com/pypi/simple/
# 清华源
pip install qrcode -i https://pypi.tuna.tsinghua.edu.cn/simple/问题 3:PyCharm 中安装库后仍提示 "找不到模块"?解决:检查 PyCharm 的 Python 解释器配置 —— 打开Settings → Project → Python Interpreter,确保选择的解释器是安装库时使用的 Python 版本(如果电脑安装了多个 Python 版本,容易出现此问题)。
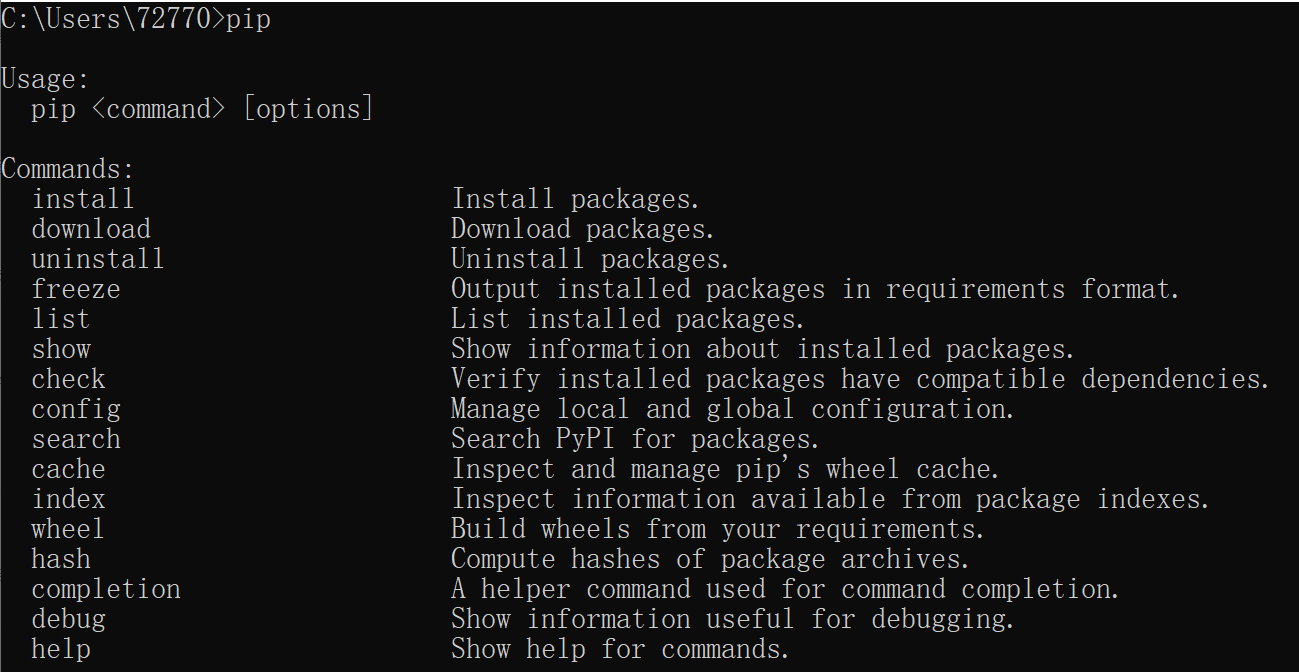
若能正常使用pip,则在命令行输入pip,会输出以下内容:
步骤 3:导入库并使用
安装完成后,通过import 库名导入,即可调用库的功能。下面结合 3 个实战案例,带你实操。
3.2 实战 1:生成二维码(qrcode库)
二维码广泛用于网址跳转、信息存储等场景,qrcode库是 Python 生成二维码的常用工具,简单易用。
步骤 1:安装qrcode库
qrcode库依赖图像处理库PIL,安装时需一并安装:
pip install qrcode[pil]步骤 2:生成基础二维码
生成包含文本、网址的二维码,保存为图片文件:
import qrcode
# 1. 生成文本二维码
img1 = qrcode.make("Hello Python!这是我的第一个二维码")
# 保存图片(支持png、jpg等格式)
img1.save("text_qrcode.png")
print("文本二维码生成成功!")
# 2. 生成网址二维码(扫码自动跳转)
img2 = qrcode.make("https://blog.csdn.net/")
img2.save("url_qrcode.png")
print("网址二维码生成成功!")步骤 3:自定义二维码样式(高级用法)
可自定义二维码的大小、边框、颜色等参数:
import qrcode
# 创建二维码配置对象
qr = qrcode.QRCode(
version=1, # 二维码大小(1-40,越大越复杂)
error_correction=qrcode.constants.ERROR_CORRECT_L, # 纠错级别(L/M/Q/H,纠错能力递增)
box_size=10, # 每个格子的像素大小
border=4, # 边框宽度(默认4)
)
# 添加二维码内容
qr.add_data("https://github.com/")
qr.make(fit=True) # 自动适配大小
# 自定义颜色(前景色、背景色)
img = qr.make_image(fill_color="blue", back_color="white")
img.save("custom_qrcode.png")
print("自定义二维码生成成功!")运行效果:
生成的text_qrcode.png、url_qrcode.png等文件,用微信、支付宝扫码即可查看内容(网址二维码会自动跳转)。

核心原理:
二维码的本质是用黑白点阵表示字符串,扫码工具(如微信)会解析点阵信息,还原为原始字符串(如果是网址,则自动跳转)。
3.3 实战 2:操作 Excel 文件(xlrd库读取、xlwt库写入)
Excel 是日常工作中常用的数据存储格式,xlrd库用于读取 Excel 文件,xlwt库用于写入 Excel 文件,二者配合可实现 Excel 数据的自动化处理。
需求:计算 100 班学生的平均分
假设有 Excel 文件d:/test.xlsx,数据如下:
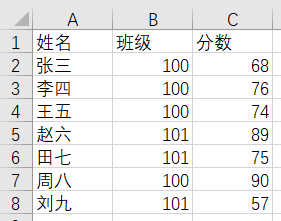
需计算 100 班学生的平均分。
步骤 1:安装xlrd库
注意:xlrd最新版本(2.0+)已删除对xlsx格式的支持,需安装 1.2.0 版本:
pip install xlrd==1.2.0步骤 2:编写代码读取 Excel 并计算平均分
import xlrd
def calculate_class_average():
# 1. 打开Excel文件(支持xlsx、xls格式)
excel_file = xlrd.open_workbook("d:/test.xlsx")
# 2. 获取工作表(通过索引,0表示第一个工作表)
sheet = excel_file.sheet_by_index(0)
# 3. 获取总行数(sheet.nrows)和总列数(sheet.ncols)
total_rows = sheet.nrows
print(f"Excel文件共有 {total_rows} 行数据")
# 4. 遍历数据,计算101班的总分和人数
class_id_target = 101 # 目标班级
total_score = 0 # 总分
student_count = 0 # 人数
# 从第2行开始遍历(第1行是表头)
for row in range(1, total_rows):
# 获取班级(第2列,索引为1)和分数(第3列,索引为2)
class_id = sheet.cell_value(row, 1)
score = sheet.cell_value(row, 2)
# 判断是否为目标班级,且分数为数字
if class_id == class_id_target and isinstance(score, float):
total_score += score
student_count += 1
# 5. 计算平均分
if student_count > 0:
average_score = total_score / student_count
print(f"{class_id_target}班共有 {student_count} 名学生,平均分为:{average_score:.2f}")
else:
print(f"未找到 {class_id_target} 班的学生数据!")
# 执行计算
calculate_class_average()运行结果:
Excel文件共有 8 行数据
101班共有 3 名学生,平均分为:73.67扩展:用xlwt库写入 Excel 文件
如果需要将计算结果写入新的 Excel 文件,可使用xlwt库:
import xlwt
def write_to_excel():
# 1. 创建工作簿
workbook = xlwt.Workbook(encoding="utf-8")
# 2. 创建工作表(命名为"101班平均分")
sheet = workbook.add_sheet("101班平均分")
# 3. 写入表头
sheet.write(0, 0, "班级")
sheet.write(0, 1, "学生人数")
sheet.write(0, 2, "平均分")
# 4. 写入数据(假设已计算出结果)
sheet.write(1, 0, 101)
sheet.write(1, 1, 3)
sheet.write(1, 2, 73.67)
# 5. 保存文件
workbook.save("d:/101班成绩统计.xls")
print("Excel文件写入成功!")
# 执行写入
write_to_excel()注意事项:
xlwt库生成的是.xls格式文件(不支持.xlsx),如果需要生成.xlsx格式,可使用openpyxl库;- 读取 Excel 时,单元格索引从 0 开始(第 1 列索引为 0,第 1 行索引为 0)。
3.4 实战 3:程序猿鼓励师(pynput+playsound库)
长时间编程容易疲劳,我们可以做一个 "程序猿鼓励师":每按键盘 20 次,自动播放一段鼓励音频(如 "加油,你真棒!"),缓解编程压力。
步骤 1:安装依赖库
pynput:监听键盘按键;playsound:播放音频文件。
注意版本兼容问题,推荐安装指定版本:
pip install pynput==1.6.8
pip install playsound==1.2.2步骤 2:准备音频文件
在 Python 代码同级目录下,准备一个音频文件(如ding.mp3,可自行录制鼓励语音或下载音效)。
步骤 3:编写基础版代码
from pynput import keyboard
from playsound import playsound
# 按键计数
key_count = 0
def on_key_release(key):
"""按键释放时触发的回调函数"""
global key_count
key_count += 1
print(f"已按键 {key_count} 次")
# 每按键10次,播放鼓励音频
if key_count % 10 == 0:
playsound("ding.mp3")
print("加油,你真棒!继续努力!")
# 创建键盘监听器
listener = keyboard.Listener(on_release=on_key_release)
# 启动监听器
listener.start()
# 让程序持续运行(等待用户按键)
listener.join()步骤 4:优化版(多线程解决音频卡顿)
基础版代码在播放音频时会导致键盘监听卡顿(因为playsound是阻塞式的),可使用多线程解决:
from pynput import keyboard
from playsound import playsound
from threading import Thread # 多线程库(标准库)
key_count = 0
def play_encouragement():
"""播放鼓励音频(单独线程执行)"""
playsound("ding.mp3")
print("加油,你真棒!继续努力!")
def on_key_release(key):
global key_count
key_count += 1
print(f"已按键 {key_count} 次")
if key_count % 10 == 0:
# 创建线程播放音频(非阻塞)
thread = Thread(target=play_encouragement)
thread.start()
# 启动监听器
listener = keyboard.Listener(on_release=on_key_release)
listener.start()
listener.join()运行效果:
运行程序后,每按 10 次键盘,就会自动播放ding.mp3音频并打印鼓励语,且不会影响键盘输入(解决了卡顿问题)。
核心原理:
pynput.keyboard.Listener监听键盘事件,on_release参数指定按键释放时的回调函数;- 多线程(
Thread)让音频播放在后台执行,避免阻塞主线程的键盘监听。
四、综合实战:开发命令行版学生管理系统
前面我们学习了标准库和第三方库的基础用法,现在结合这些知识,开发一个实用的命令行版学生管理系统,实现学生信息的增删查改、存档读档功能,并最终打包成 exe 程序。
4.1 需求说明
系统功能:
- 新增学生(学号、姓名、性别、班级);
- 显示所有学生信息;
- 根据姓名查找学生;
- 根据学号删除学生;
- 自动存档(新增 / 删除后保存到文件);
- 启动时自动读档(加载历史数据);
- 支持打包成 exe,无需 Python 环境运行。
4.2 技术选型
- 标准库:
os(文件操作)、sys(程序退出)、threading(可选,用于优化体验); - 无第三方库依赖(保证打包后体积小、兼容性好)。
4.3 完整代码实现
import os
import sys
# 全局变量:存储所有学生信息(列表+字典)
students = []
def load_data():
"""读档函数:启动时加载历史数据(从d:/record.txt读取)"""
global students
# 清空现有数据
students = []
# 定义存档文件路径
data_file = "d:/record.txt"
# 如果文件不存在,直接返回(首次使用无存档)
if not os.path.exists(data_file):
print("未找到存档文件,将创建新数据!")
return
# 读取文件并解析数据
try:
with open(data_file, "r", encoding="utf-8") as f:
for line_num, line in enumerate(f, start=1):
# 去除换行符和首尾空格
line = line.strip()
# 跳过空行
if not line:
continue
# 按制表符分割数据(格式:学号\t姓名\t性别\t班级)
parts = line.split("\t")
# 验证数据格式(必须包含4个字段)
if len(parts) != 4:
print(f"存档文件第{line_num}行格式错误,跳过该条数据:{line}")
continue
# 构造学生字典
student = {
"student_id": parts[0],
"name": parts[1],
"gender": parts[2],
"class_name": parts[3]
}
# 添加到学生列表
students.append(student)
print(f"读档成功!共加载 {len(students)} 条学生数据")
except Exception as e:
print(f"读档失败:{str(e)}")
def save_data():
"""存档函数:新增/删除学生后保存数据到d:/record.txt"""
data_file = "d:/record.txt"
try:
with open(data_file, "w", encoding="utf-8") as f:
for student in students:
# 按格式写入:学号\t姓名\t性别\t班级\n
line = f"{student['student_id']}\t{student['name']}\t{student['gender']}\t{student['class_name']}\n"
f.write(line)
print(f"存档成功!共保存 {len(students)} 条学生数据")
except Exception as e:
print(f"存档失败:{str(e)}")
def show_menu():
"""显示系统菜单"""
print("=" * 40)
print(" Python 学生管理系统 v1.0")
print("=" * 40)
print(" 1. 新增学生信息")
print(" 2. 显示所有学生信息")
print(" 3. 根据姓名查找学生")
print(" 4. 根据学号删除学生")
print(" 0. 退出系统")
print("=" * 40)
# 获取用户输入并转换为整数
while True:
choice = input("请输入您的选择(0-4):")
if choice.isdigit():
choice = int(choice)
if 0 <= choice <= 4:
return choice
else:
print("输入错误!请输入0-4之间的数字")
else:
print("输入错误!请输入有效的数字")
def add_student():
"""新增学生信息"""
print("\n【新增学生】")
# 输入学生信息
student_id = input("请输入学号(如2024001):").strip()
name = input("请输入姓名:").strip()
gender = input("请输入性别(男/女):").strip()
class_name = input("请输入班级(如101):").strip()
# 数据验证
if not student_id or not name or not gender or not class_name:
print("新增失败:所有字段不能为空!")
return
if gender not in ("男", "女"):
print("新增失败:性别必须是'男'或'女'!")
return
# 验证学号唯一性(避免重复)
for student in students:
if student["student_id"] == student_id:
print("新增失败:该学号已存在!")
return
# 构造学生字典并添加到列表
new_student = {
"student_id": student_id,
"name": name,
"gender": gender,
"class_name": class_name
}
students.append(new_student)
print(f"新增成功!{name}(学号:{student_id})已添加到系统")
# 自动存档
save_data()
def show_all_students():
"""显示所有学生信息"""
print("\n📋 【显示所有学生】")
if not students:
print("系统中暂无学生数据!")
return
# 打印表头
print(f"{'学号':<10} {'姓名':<6} {'性别':<4} {'班级':<6}")
print("-" * 30)
# 遍历打印学生信息
for student in students:
print(f"{student['student_id']:<10} {student['name']:<6} {student['gender']:<4} {student['class_name']:<6}")
print("-" * 30)
print(f"共显示 {len(students)} 条学生数据\n")
def search_student_by_name():
"""根据姓名查找学生"""
print("\n查找学生】")
if not students:
print("系统中暂无学生数据!")
return
search_name = input("请输入要查找的学生姓名:").strip()
if not search_name:
print("查找失败:姓名不能为空!")
return
# 查找匹配的学生(支持模糊查询,如输入"张"匹配"张三")
result = []
for student in students:
if search_name in student["name"]:
result.append(student)
# 显示查找结果
if not result:
print(f"未找到姓名包含'{search_name}'的学生!")
return
print(f"共找到 {len(result)} 条匹配数据:")
print(f"{'学号':<10} {'姓名':<6} {'性别':<4} {'班级':<6}")
print("-" * 30)
for student in result:
print(f"{student['student_id']:<10} {student['name']:<6} {student['gender']:<4} {student['class_name']:<6}")
print()
def delete_student_by_id():
"""根据学号删除学生"""
print("\n🗑️ 【删除学生】")
if not students:
print("系统中暂无学生数据!")
return
delete_id = input("请输入要删除的学生学号:").strip()
if not delete_id:
print("删除失败:学号不能为空!")
return
# 查找要删除的学生
deleted_count = 0
for i in range(len(students)-1, -1, -1): # 倒序遍历,避免删除后索引错乱
if students[i]["student_id"] == delete_id:
deleted_student = students.pop(i)
print(f"删除成功!已删除学生:{deleted_student['name']}(学号:{delete_id})")
deleted_count += 1
if deleted_count == 0:
print(f"删除失败:未找到学号为'{delete_id}'的学生!")
return
# 自动存档
save_data()
def main():
"""程序入口函数"""
# 启动时自动读档
load_data()
print("\n欢迎使用Python学生管理系统!")
# 主循环:持续接收用户操作
while True:
choice = show_menu()
if choice == 0:
# 退出系统
print("\n感谢使用,再见!")
sys.exit()
elif choice == 1:
add_student()
elif choice == 2:
show_all_students()
elif choice == 3:
search_student_by_name()
elif choice == 4:
delete_student_by_id()
# 每次操作后暂停,让用户看清结果
input("\n按回车键继续...")
# 程序启动入口
if __name__ == "__main__":
main()4.4 代码解析
(1)核心数据结构
用全局列表students存储所有学生信息,每个学生是一个字典,结构如下:
{
"student_id": "2024001", # 学号
"name": "张三", # 姓名
"gender": "男", # 性别
"class_name": "101" # 班级
}(2)存档与读档
- 存档文件:
d:/record.txt,采用文本格式存储,每行一条学生数据,字段用制表符\t分隔; - 读档(
load_data()):程序启动时读取文件,解析数据并加载到students列表; - 存档(
save_data()):新增 / 删除学生后,将students列表的数据写入文件,确保数据持久化。
(3)功能模块
- 菜单显示(
show_menu()):清晰展示功能选项,支持输入验证; - 新增学生(
add_student()):输入验证(字段非空、性别合法、学号唯一); - 显示所有(
show_all_students()):格式化输出,美观易读; - 查找学生(
search_student_by_name()):支持模糊查询(如输入 "张" 匹配 "张三"); - 删除学生(
delete_student_by_id()):按学号删除,避免误删。
(4)用户体验优化
- 输入验证:避免无效输入导致程序崩溃;
- 操作反馈:每个操作后打印成功 / 失败提示;
- 自动存档:无需手动保存,数据不丢失;
- 读档容错:存档文件格式错误时跳过异常数据,不影响整体运行。
4.5 打包成 exe 程序(pyinstaller库)
当前代码是.py文件,需要在安装了 Python 环境的电脑上运行。为了让程序在任何 Windows 电脑上运行,我们可以用pyinstaller库将其打包成 exe 文件。
步骤 1:安装pyinstaller库
pip install pyinstaller步骤 2:打包程序
- 打开命令行,切换到学生管理系统代码所在的目录(如
cd D:/python_project); - 执行打包命令:
pyinstaller -F -w 学生管理系统.py命令参数说明:
-F:打包成单个 exe 文件(方便传输,不带其他依赖文件);-w:隐藏命令行窗口(运行 exe 时不会弹出黑框,更美观);- 最后是 Python 脚本文件名(如
学生管理系统.py)。
步骤 3:找到 exe 文件
打包完成后,会在代码目录下生成dist文件夹,exe 文件就在其中(文件名与脚本名一致,如学生管理系统.exe)。
步骤 4:运行 exe 程序
双击学生管理系统.exe,即可直接运行(无需 Python 环境),功能与.py 文件完全一致,存档文件仍保存在d:/record.txt。
常见问题:
- 打包后 exe 文件太大?可以使用虚拟环境(
venv)只安装必要的库,再进行打包; - 运行 exe 时提示 "找不到存档文件"?正常现象,首次运行会自动创建存档文件;
- 中文乱码?打包时确保代码文件编码为 UTF-8,且运行环境支持中文。
五、Python 库学习资源推荐
掌握了库的基本使用方法后,想要进一步提升,可以参考以下优质资源:
5.1 书籍推荐
- 《Python Cookbook》(第 3 版):Python 进阶经典书籍,针对各种典型场景提供高效解决方案,覆盖标准库和第三方库的高级用法;

- 《Python 编程:从入门到实践》:适合初学者,包含大量实战案例,涉及
pygame(游戏开发)、Django(Web 开发)等第三方库; - 《流畅的 Python》:深入 Python 底层原理,讲解如何高效使用 Python 库和语言特性。
5.2 在线资源
- PyPI 官网:https://pypi.org/,查找第三方库的权威渠道,包含库的安装说明、文档链接、版本历史;
- Awesome Python:https://gitee.com/awesome-lib/awesome-python,整理了 Python 优质第三方库,按功能分类(如 Web 开发、数据科学、机器学习等);
- 500 Lines or Less:https://github.com/aosabook/500lines,用不超过 500 行 Python 代码实现有趣的程序(如 Web 服务器、搜索引擎),适合学习库的综合应用;
- Python 官方文档:https://docs.python.org/3/,标准库的权威指南,详细介绍每个模块的 API 和用法。
5.3 学习技巧
- 按需学习:不需要掌握所有库,遇到具体需求时再针对性学习对应的库;
- 多看源码:优秀的库(如
requests)源码简洁易懂,阅读源码能学习到优雅的编程思路; - 多做实战:将库的用法融入实际项目(如爬虫、数据分析、小工具),才能真正掌握;
- 关注社区:GitHub、Stack Overflow、CSDN 等平台,及时了解库的更新动态和常见问题解决方案。
总结
Python 库是提升开发效率的神器,标准库满足基础需求,第三方库拓展高级功能。本文从库的核心概念出发,详细讲解了标准库(
datetime、os、math)和第三方库(qrcode、xlrd、pynput)的使用方法,通过 5 个实战案例和 1 个综合项目,带你从入门到精通。 最后,记住荀子的 "善假于物"—— 作为开发者,不必纠结于重复造轮子,而是要善于利用现有的优质库,将精力集中在核心业务逻辑上,才能高效地开发出高质量的程序。 如果你有常用的 Python 库想要分享,或者在使用库的过程中遇到了问题,欢迎在评论区留言交流!祝大家编程之路越走越顺,效率翻倍!
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-12-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号