
从字符串-python中提取年龄
从字符串-python中提取年龄
提问于 2019-06-12 10:09:45
考虑一下这条字符串:
s="""A25-54 plus affinities targeting,Demo (AA F21-54),
A25-49 Artist Affinity Targeting,M21-49 plus,plus plus A 21+ targeting"""我希望修复我的模式,该模式目前没有提取字符串中的所有年龄组(当前输出中缺少A 21+)。
当前尝试:
import re
re.findall(r'(?:A|A |AA F|M)(\d+-\d+)',s)输出:
['25-54', '21-54', '25-49', '21-49'] #doesnot capture the last group A 21+预期产出:
['A25-54','AA F21-54','A25-49','M21-49','A 21+']正如您所看到的,我也希望有最后一个组,即A 21+,它目前在我的输出中缺失。
此外,如果我能够获得与捕获组相关联的字符串。目前,我的输出除了没有捕获所有的组之外,没有年龄组之前的字符串。我想要'A25-54而不是'25-54',我想是因为?:。
感谢任何我能得到的帮助。
回答 1
Stack Overflow用户
回答已采纳
发布于 2019-06-12 11:30:10
匹配的缺失部分是由于模式包含一个捕获组,一旦正则表达式中有一个捕获组,re.findall只返回这些部分。第二个问题是,在匹配第一个或多个数字之后,您应该匹配-后面的一个或多个数字,或者匹配一个文字+符号。
你可以用
(?:A|A |AA F|M)\d+(?:-\d+|\+)注意:您可能希望在开头添加一个单词边界,以便只将那些A、AA F等作为整体单词来匹配:r'\b(?:A|A |AA F|M)\d+(?:-\d+|\+)'。
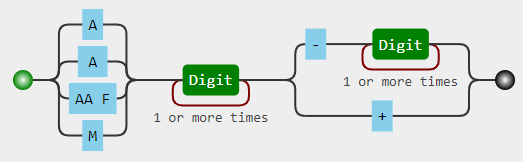
详细信息
(?:A|A |AA F|M)-非捕获组匹配A,A,AA,AA F或M\d+- 1+数字(?:-\d+|\+)-非捕获组匹配-和1+数字后,或一个单一的+符号.
import re
s="""A25-54 plus affinities targeting,Demo (AA F21-54),
A25-49 Artist Affinity Targeting,M21-49 plus,plus plus A 21+ targeting"""
print(re.findall(r'(?:A|A |AA F|M)\d+(?:-\d+|\+)',s))
# => ['A25-54', 'AA F21-54', 'A25-49', 'M21-49', 'A 21+']页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/56559625
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号