
在带有正则表达式的文件名末尾提取版本号
我有一个文件名列表,其中一些以版本号结尾。我试图使用一个正则表达式提取版本号:
filename.doc --> NULL
filename.1.0.doc --> 1.0
filename.2.0.pdf --> 2.0
filename.3.0.docx --> 3.0到目前为止,我发现以下正则表达式与扩展一起提取它:
[0-9]+\.[0-9]+\.(docx|pdf|rtf|doc|docm)$但我不想分机。所以我搜索的是在字符串中最后一个点出现之前的[0-9]+\.[0-9]+,但是我找不到怎么做。
谢谢你的帮忙!
回答 3
Stack Overflow用户
发布于 2019-05-23 14:10:46
Stack Overflow用户
发布于 2019-05-23 14:05:12
Python有命名群
一个更重要的特性是命名组:而不是用数字来引用它们,而是可以用名称来引用组。 命名组的语法是Python特定的扩展之一:(?P.)。很明显,名字是这个团体的名字。命名组的行为与捕获组完全一样,并将名称与组相关联。处理捕获组的match对象方法都接受按数字引用组的整数或包含所需组名称的字符串。命名组仍然有编号,因此可以通过两种方式检索有关组的信息:P= re.compile(r'(?P\b\w+\b)') >> m= p.search(大量标点符号) >> m.group('word')‘>>’>> m.group(1) ' Lots‘
因此,在您的示例中,您可以将regex修改为:
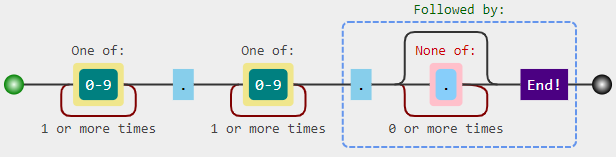
(?P<version>[0-9]+\.[0-9]+)\.(docx|pdf|rtf|doc|docm)$
和使用:
found.group('version')
若要从找到的regex匹配中选择版本,请执行以下操作。
Stack Overflow用户
发布于 2019-05-23 14:07:09
试试这个-
import re
try:
version = [float(s) for s in re.findall(r'-?\d+\.?\d*', 'filename.1.0.doc')][0]
print(version)
except:
pass在这里,如果它有一个数字,那么它将存储在变量版本中,否则它将传递。
这应该有效!)
https://stackoverflow.com/questions/56276966
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号