
熊猫群值和日期范围的平均值
熊猫群值和日期范围的平均值
提问于 2019-01-30 16:27:54
我有一个像这样的DataFrame
df = pd.DataFrame( data = numpy_data, columns=['value','date'])
value date
0 64.885 2018-01-11
1 74.839 2018-01-15
2 41.481 2018-01-17
3 22.027 2018-01-17
4 53.747 2018-01-18
... ... ...
514 61.017 2018-12-22
515 68.376 2018-12-21
516 79.079 2018-12-26
517 73.975 2018-12-26
518 76.923 2018-12-26
519 rows × 2 columns我想要把这个value和date相提并论,我用这个
df.plot( x='date',y='value')我明白了
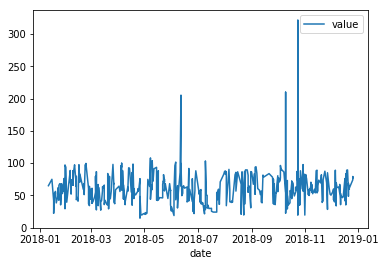
这里的点,这个图必须有许多波动,我想要软化这一点,我的想法是按日期间隔将值分组,得到平均值,例如10天,7月1日到7月10日之间的平均值,并在7月5日创建de point。
一个很长的方法是,获取日期范围,在N个范围内分离开始日期和结束日期,用日期过滤数据,计算平均值,并放入其他DataFrame
有什么捷径可以做到吗?
PD:忽略那些山峰
回答 2
Stack Overflow用户
回答已采纳
发布于 2019-01-30 19:21:26
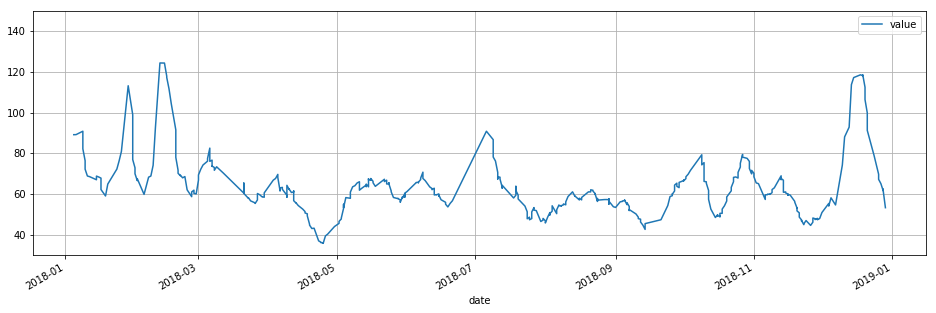
基于雅图的回答
他回答的问题是,滚动函数考虑的是作为索引的值,而不是日期,有些转换可以将时间戳读入窗口[ pandas.rolling ]
df = pd.DataFrame( data = numpy_data, columns=['value','date'])
df['date'] = df.apply(lambda row: pd.Timestamp(row.date), axis=1 )
df = df.set_index(df.date).drop('date', axis=1)
df.sort_index(inplace=True)
df.rolling('10d').mean().plot( ylim=(30,100) , figsize=(16,5),grid='true')最终结果
Stack Overflow用户
发布于 2019-01-30 16:31:02
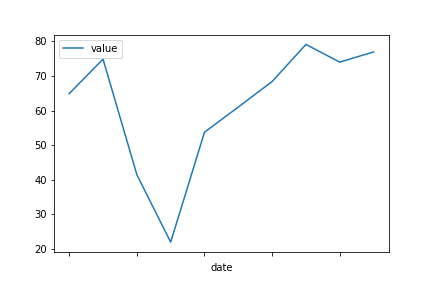
例如,您可以做的一件事是使用DataFrame.rolling和mean来获取数据的滚动平均值。
df = df.set_index(df.date).drop('date', axis=1)
df.rolling(3).mean().plot()对于您的示例dataframe,直接绘制dataframe将产生如下结果:
如果采取了滚动的手段,你就会:
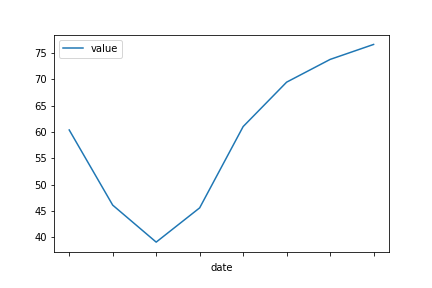
在这里,我选择了一个window of 3,但他的选择取决于你希望它成为什么样的人。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/54445152
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号