
java中高效的字词生成算法
我正在使用libGDX框架开发一个单词游戏,我希望实现一个基本的提示功能,这样系统就可以从板上提供的17个字母中生成一个有效的7个字母单词。现在,船上的17个字母(从中挑选)的设置是完全随机的,因此我不能使用预先确定的提示词作为提示(如在4个图片1字中)。
我的解决方案是通过从所提供的17个字母中找到每一个可能的7个字母组合来做一些组合。接下来,我对每一个组合进行了排列,并将它们与wordSet英语词汇交叉检查,我得到的第一个有效单词就是提示词。
正如您已经猜到的,这个过程是在任务处理,知道17个置换7已经等于9800万个可能的排列。为了掩盖这一点,我使用FixedThreadPool将置换任务拆分为20个工作线程,现在我有了一个相对快速的单词搜索,但缺点是,这会导致低端设备严重滞后。
任何建议,如何作出更好的提示词搜索算法或改进我的方法,上述解释将不胜感激。
回答 3
Stack Overflow用户
发布于 2018-04-27 22:45:55
这里有几种优化它的方法:
- 与其生成数百万个组合并测试它们,不如迭代一遍英语单词列表,并根据你的17个字母测试这些单词。而不是做数百万的测试,你将做数千。
- 测试一个单词是否可以由你的17个字母组成,使用字母计数,而不是实际按特定顺序生成字符串,并与单词进行比较。这意味着您不必生成每个可能的字母排序。
为了实现第二次优化,有必要将单词存储在单词列表中,以便您可以轻松地比较字母计数。要做到这一点,一个简单的方法是将每个单词与另一个字符串一起存储,该字符串由按字母顺序排序的所有字母组成。例如,你会把“奶酪”和“奶酪”作为一对储存起来。你可以数一数字母的运行,看看你是否有足够的每一个。
在您的过程开始时,您可以计算您的17个字母中的每个字母的数量,并将它们存储在一个数组中。然后检查你的单词列表并测试每个单词,如下所示:
int[] letter_counts = new int[26]; // how many of each letter of the
// alphabet you have in your 17 letters
boolean test_word(String word) // pass in the sorted string e.g "ceeehs"
{
char prev = '\0'; // use this for detecting repeating letters
int count = 0;
for(int i = 0; i < word.length(); i++)
{
char c = word.charAt(i);
if(c != prev)
{
prev = c;
count = 0;
}
count++;
if(letter_counts[(int)c - 'a'] < count)
return false; // not enough letters
}
return true;
}为了避免对单词列表前面的单词有偏见(因为一旦找到单词列表就会停止),您可以从单词列表中的一个随机位置开始,然后绕到开头。
这种方法绝不是最优的,但可能足够快,而且很容易实现。
Stack Overflow用户
发布于 2018-04-27 20:34:53
使用单词列表构建一个trie /前缀树:
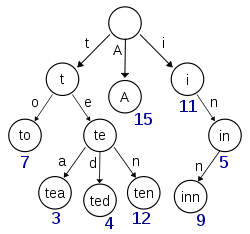
您可以从17个可用的字母中随机选择一个字母,然后只使用来自17个字母的字母开始遍历。第一个节点具有标记一个单词结束的标志,可以是一个建议。
很多预测文本程序使用这样的结构来猜测您正在键入的单词,或者帮助您输入一个错误,如果您在图中距离标记单词末尾的节点不远。在空间上更好,因为树的深度是由你最长的单词决定的。但是,您不会在以下情况下浪费空间:
do
dog
doggy
done
dunce你只在商店:
d
/ \
*o u
/ \ \
*g n n
/ \ \
g *e c
/ \
*y *e其中*是一个布尔标志,指示单词的结尾位置。
时间复杂性:
O(n)将查找文本字符串是否为单词,其中n是单词的长度。
这个站点似乎有一些优化:https://www.geeksforgeeks.org/trie-insert-and-search/
空格,取决于您是否使用数组、指针或哈希映射实现。
Stack Overflow用户
发布于 2018-04-27 19:15:36
我现在不能测试任何关于速度的东西,但是如果你把你的字典排序,你可以在上面使用搜索算法:你首先找到所有的位置,其中的单词列表从你的17个可用字母开始。然后,您查看这些列表中的每一个,以其他16个字母中的一个开始,然后继续这个列表,直到出现任何长度允许的单词。
作为一个简单的例子,请考虑以下几点:
String[] lexicon = {"parrot", "postal", "office", "spam"};
char[] letters = {'p', 'o', 's', 't', 'a', 'l'};这将产生中间的可能性:
{"parrot", "postal", "office", "spam"} (1 letter matched)
{"parrot", "postal", "spam"} (2 letters matched)
{"postal", "spam"} (3 letters matched)
{"parrot"} (4 letters matched)此时,您可以继续搜索算法,或者注意只剩下一个选项,并使用不同的测试来查看是否允许。
此算法将要求您最多使用C(17, 7) = 19,448搜索。你可能还可以提高成本使用一个完整的二进制搜索每一个字母也。
https://stackoverflow.com/questions/50067940
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号