
在字典列表中对值进行分组,以便使用Python为每个值创建具有组号的新字典?
在下面的图片中有三组触摸方块,每个方块都有编号。
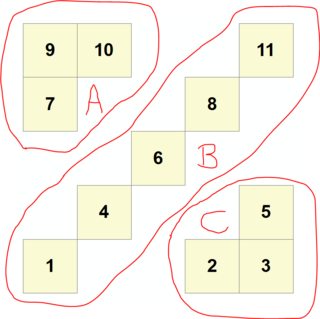
我已经能够使用空间库ArcPy来构建字典,下面的字典使用平方数作为键,并使用它所接触的正方形的数字列表作为其值。例如,方格1只触及方格4,方格4只接触正方形1和6,等等。
dict = {1: [4], 2: [3, 5], 3: [2, 5], 4: [1, 6], 5: [2, 3], 6: [4, 8], 7: [9, 10], 8: [6, 11], 9: [7, 10], 10: [7, 9], 11: [8]}从图片中可以清楚地看到,有三组触摸方块,所以我想要的结果是一本新字典,其中键是正方形,值是它所属的触摸组。我将使用字母命名这些触觉组,但是这些名称可以是任何内容,因此一种可能的解决方案是:
newDict = {9:"A",10:"A",7:"A",1:"B",4:"B",6:"B",8:"B",11:"B",5:"C",2:"C",3:"C"}从dict到newDict有毕达通的路吗?
我正在使用Python2.7.14进行测试。
回答 3
Stack Overflow用户
发布于 2018-03-21 03:16:39
为了你的考虑..。用CLRS的秩算法求解不相交集并。这是我所知道的最有效的不相交集查找算法。
本质上,只要把问题看作是一个不连通的图,就可以使用并找到每个边的父边--查找并关联它们。
输出为每个父节点关联不同的集合标识符,而不是一致A,但更有效的方法是预先生成顶点到字母的映射,而不是事后将它们关联起来。这样你可以有多达26个不相交的集合。对于更多的内容,您可能想要移动到数字标识符。
复杂性是O( | d.keys() | * log(| d.values() |) )
d = {1: [4], 2: [3, 5], 3: [2, 5], 4: [1, 6], 5: [2, 3], 6: [4, 8], 7: [9, 10], 8: [6, 11], 9: [7, 10], 10: [7, 9], 11: [8]}
class MSet(object):
def __init__(self, p):
self.val = p
self.p = self
self.rank = 0
def parent_of(x): # recursively find the parents of x
if x.p == x:
return x.val
else:
return parent_of(x.p)
def make_set(x):
return MSet(x)
def find_set(x):
if x != x.p:
x.p = find_set(x.p)
return x.p
def link(x,y):
if x.rank > y.rank:
y.p = x
else:
x.p = y
if x.rank == y.rank:
y.rank += 1
def union(x,y):
link(find_set(x), find_set(y))
vertices = {k: make_set(k) for k in d.keys()}
edges = []
for k,u in vertices.items():
for v in d[k]:
edges.append((u,vertices[v]))
# do disjoint set union find similar to kruskal's algorithm
for u,v in edges:
if find_set(u) != find_set(v):
union(u,v)
# resolve the root of each disjoint set
parents = {}
# generate set of parents
set_parents = set()
for u,v in edges:
set_parents |= {parent_of(u)}
set_parents |= {parent_of(v)}
# make a mapping from only parents to A-Z, to allow up to 26 disjoint sets
letters = {k : chr(v) for k,v in zip(set_parents, list(range(65,91)))}
for u,v in edges:
parents[u.val] = letters[parent_of(u)]
parents[v.val] = letters[parent_of(v)]
print(parents)输出:
rpg711$ python disjoint_set_union_find
{1: 'C', 2: 'B', 3: 'B', 4: 'C', 5: 'B', 6: 'C', 7: 'A', 8: 'C', 9: 'A', 10: 'A', 11: 'C'}我对您期望的字典进行了排序,以便更容易地关联集合标识符并检查我的工作:
sorted(d.items(), key=lambda k: k[0])
[(1, 'B'), (2, 'C'), (3, 'C'), (4, 'B'), (5, 'C'), (6, 'B'), (7, 'A'), (8, 'B'), (9, 'A'), (10, 'A'), (11, 'B')]在我提议的解决方案'B‘-> 'C','C’-> 'B','A‘-> 'A',但请注意,每个顶点所属的集合标识符只是您期望的一个重新映射。
PS:如果存在不接触任何其他顶点(没有边)的顶点,则应该生成或修改输入dict,使这些顶点本身具有一条边。
Stack Overflow用户
发布于 2018-03-21 05:57:02
我尝试了递归解决方案,如果您想要的话,可以尝试:
dict22 = {1: [4], 2: [3, 5], 3: [2, 5], 4: [1, 6], 5: [2, 3], 6: [4, 8], 7: [9, 10], 8: [6, 11], 9: [7, 10], 10: [7, 9], 11: [8]}
def connected_nodes(dict34):
final=[]
for i,j in dict34.items():
def recursive_approach(dict1, tem, data,check=[], dict_9={}):
if data!=None:
dict_9.update({data:dict22[data]})
dict_9.update({tem: dict1[tem]})
check.append(tem)
final.append(dict_9)
if check.count(tem) > 1:
return 0
for i, j in dict1.items():
if tem in dict1:
return recursive_approach(dict1, tem=dict1[tem][-1],data=None)
recursive_approach(dict22, tem=j[-1],data=i)
return final
bew=[]
for i in connected_nodes(dict22):
bew.append(list(i.keys()))
new_bew=bew[:]
final_result=[]
for j,i in enumerate(bew):
for m in new_bew:
if set(i).issubset(set(m)) or set(m).issubset(set(i)):
if len(i)>len(m):
final_result.append(tuple(i))
new_bew.remove(m)
else:
final_result.append(tuple(m))
else:
pass
print(set(final_result))产出:
{(2, 3, 5), (9, 10, 7), (1, 4, 6, 8, 11)}Stack Overflow用户
发布于 2018-03-21 22:29:00
您可以使用 library来确定图的簇或子组。
给定的
from string import ascii_uppercase as uppercase
import networkx as nx
import matplotlib.pyplot as plt
%matplotlib inline
d = {
1: [4], 2: [3, 5], 3: [2, 5], 4: [1, 6], 5: [2, 3], 6: [4, 8],
7: [9, 10], 8: [6, 11], 9: [7, 10], 10: [7, 9], 11: [8]
}码
G = nx.from_dict_of_lists(d)
# Label sub-groups
sub_graphs = list(nx.connected_component_subgraphs(G))
{val: label for label, sg in zip(uppercase, sub_graphs) for val in sg.nodes()}
# {1: 'A', 2: 'B', 3: 'B', 4: 'A', 5: 'B', 6: 'A', 7: 'C', 8: 'A', 9: 'C', 10: 'C', 11: 'A'}详细信息
为了便于可视化,下面是标记的子组(see also motivating code):
# Printed subgroups
for label, sg in zip(uppercase, sub_graphs):
print("Subgraph {}: contains {}".format(label, sg.nodes()))
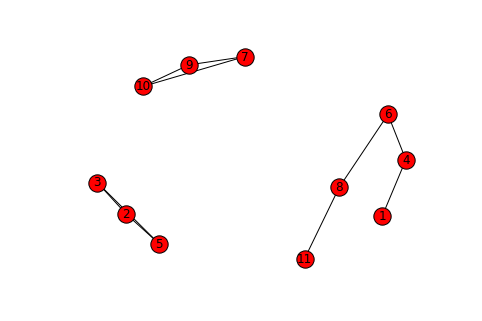
# Subgraph A: contains [8, 1, 11, 4, 6]
# Subgraph B: contains [2, 3, 5]
# Subgraph C: contains [9, 10, 7]虽然我最终会推荐一份由此产生的列表,用于更干净的数据分组:
{label: sg.nodes() for label, sg in zip(uppercase, sub_graphs)}
# {'A': [8, 1, 11, 4, 6], 'B': [2, 3, 5], 'C': [9, 10, 7]}此外,您还可以选择绘制这些图:
# Plot graphs in networkx (optional)
nx.draw(G, with_labels=True)
https://stackoverflow.com/questions/49396943
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号