
正则表达式-相同匹配的不同字符串
我知道模式r'([a-z]+)\1+'在搜索字符串中搜索重复的多字符模式,但我不明白为什么k2答案不是'aaaaa‘(5 'a'):
import re
k1 = re.search(r'([a-z]+)\1+', 'aaaa')
k2 = re.search(r'([a-z]+)\1+', 'aaaaa')
k3 = re.search(r'([a-z]+)\1+', 'aaaaaa')
print(k1) # <_sre.SRE_Match object; span=(0, 4), match='aaaa'>
print(k2) # <_sre.SRE_Match object; span=(0, 4), match='aaaa'>
print(k3) # <_sre.SRE_Match object; span=(0, 6), match='aaaaaa'>Python 3.6.1
回答 2
Stack Overflow用户
发布于 2018-02-06 23:08:42
这里的关键概念是回溯。每当模式包含不同长度的量化子模式时,正则表达式引擎可以以各种方式匹配字符串,一旦在量化部分之后的正则表达式的一部分不能匹配某些子字符串,它就可以回溯,即释放属于量化模式的字符,并尝试与随后的子模式匹配。
看一看更大的情况:
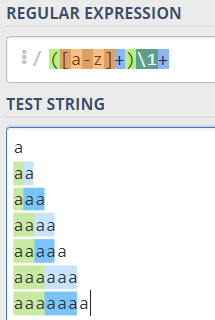
让我们看看短字符串在跳转更长的例子之前是如何匹配的.
那么,为什么a不匹配呢?因为必须至少有两个字符,因为[a-z]+和\1+需要匹配至少一个字符。
aa是匹配的,因为第一个([a-z]+)首先匹配整个字符串,然后回溯以适应\1+模式的一些文本(并且它匹配第二个a),所以有一个匹配。
3-a字符串aaa匹配为一个整体,因为第一个([a-z]+)首先匹配整个字符串,然后回溯以适应\1+模式的一些文本(注意,捕获组必须只保存一个a,因为当尝试使用两个aa时,\1+无法匹配最后的第三个a),并且有三个a的匹配。
现在来看看问题中的例子
aaaa字符串匹配的整体类似于aa匹配的方式:捕获组模式首先捕获整个aaaa,然后回溯,因为\1+也必须“查找”一些文本,而regex引擎试图将aaa捕获到第1组。然而,\1+无法匹配3a,因此回溯会继续进行,当第1组中有两个a时,量化的回引用将匹配最后两个a。
与 case:
aaaaa字符串匹配如下:
aaaaa被抓取并与([a-z]+)部件一起放入第1组\1+找不到任何文本,引擎重新尝试将字符串与\1+可以匹配不同文本之前的字符串进行不同的匹配,这要归功于+量词。- 尝试
aaaa(=放置到第1组),但没有效果,因为\1+不匹配(就像\1尝试匹配aaaa一样,但在字符串结束之前只剩下a)。 - 再次尝试
aaa无效(因为\1试图匹配aaa,但只剩下两个a) aa被放入第1组,\1匹配第三和第四个a,这是唯一的匹配,因为字符串中只保留了一个a。
这是一个字符串匹配方式的示例方案
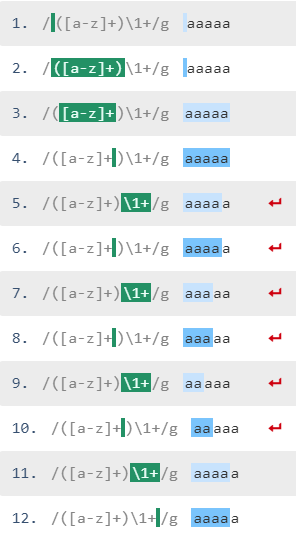
最后一个a无法匹配:

Stack Overflow用户
发布于 2018-02-06 16:34:49
因为他很贪婪。
所发生的是([a-z]+)首先匹配'aaaaa',然后返回到\1+匹配字符串为止,然后停止。因为'aa‘是([a-z]+)的第一个值,它将使\1成功匹配,这就是它返回的内容。
https://stackoverflow.com/questions/48647645
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号