
偷工作的并行工作似乎不会占用太多的工作。
偷工作的并行工作似乎不会占用太多的工作。
提问于 2018-02-01 16:43:09
这个想法是在一台96核的机器上运行一个并行作业,通过窃取ForkJoinPool的工作。
下面是我目前正在使用的代码:
import scala.collection.parallel.ForkJoinTaskSupport
import scala.concurrent.forkjoin.ForkJoinPool
val sequence: ParSeq[Item] = getItems().par
sequence.tasksupport = new ForkJoinTaskSupport(new ForkJoinPool())
val results = for {
item <- sequence
res = doSomethingWith(item)
} yield res在这里,sequence大约有20,000件商品。大多数项目需要2-8秒的时间来处理,其中只有200件需要更长的时间,大约40秒。
问题:
一切运行良好,然而,偷工作方面似乎不太好。下面是与实际负载(蓝色)相比较的预期总CPU负载(黑色):
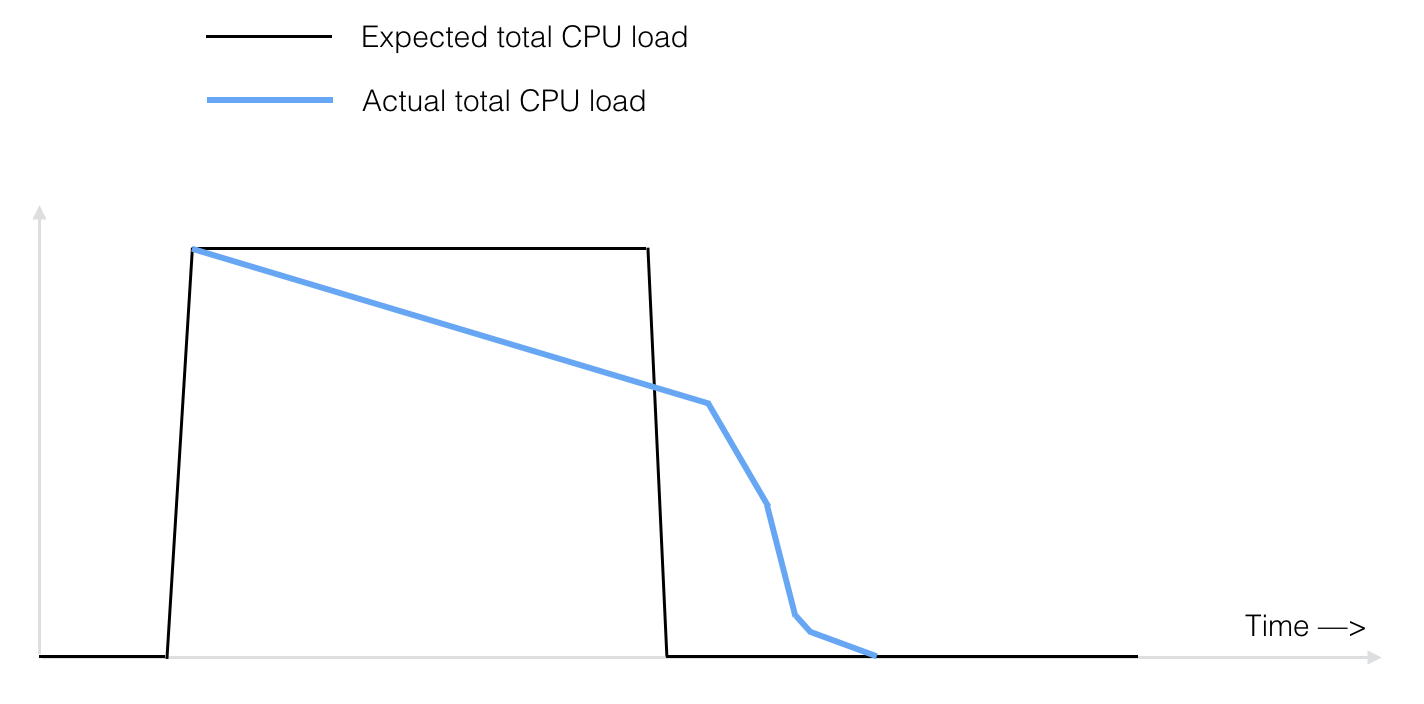
在查看CPU活动时,非常清楚的是,随着工作的完成,越来越少的核心被使用。在过去的10分钟里,只有2到3个核心仍在忙着依次处理几十个项目。
为什么仍然在队列中的项目不会被其他免费内核窃取,即使使用ForkJoinPool,这应该是偷工作的吗?
https://docs.oracle.com/javase/8/docs/api/java/util/concurrent/ForkJoinPool.html
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-02-01 17:03:23
每个工作线程都有自己的内部任务队列,可以防止从其他线程窃取工作,从而限制工作人员之间的交互。
这可能解释了您所看到的行为,特别是如果项集中出现的长任务不是随机的。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/48567725
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号