
使用selenium C#获取保持其顺序的不同标记类
使用selenium C#获取保持其顺序的不同标记类
提问于 2017-12-04 12:58:29
我正在抓取一本ePUB圣经(每一章都有HTML页面),我希望保留散布在HTML页面上的几个标签的顺序。“圣经”的所有章节都是相似的,并且都是这样写的,或者是这样的变体:
<div>
<p class="p">
<a class="v">1</a> This is a verse.
<a class="v">2</a> This is a verse.
<a class="v">3</a> This is a verse.
</p>
<h3 class="s1">This is a pericope</h3>
<h4 class="r">This is a reference for this pericope.</h4>
<p class="p">
<a class="v">4</a> This is a verse.
<a class="v">5</a> This is a verse.
</p>
<p class="p">
<a class="v">6</a> This is a verse with a quote:
</p>
<p class="q">"This is the content</p>
<p class="q">of a quote;</p>
<p class="q">or a spoken word."</p>
<h3 class="s1">This is another pericope</h3>
...
</div>实质上:
<class="v"> is a "a" element with the number of the verse
<class="p"> is a "p" element with a verse or a collection of verses;
<class="q"> is a blockquote;
<class="s1"> is a pericope;
<class="r"> is a reference to a periscope;获得所有的p元素可以给我很好的结果,这是与另一个相关的问题是这样,但它是否有可能废除一个页面,保持调用的顺序?
对于上面的例子,我可以按照元素类的顺序排列元素,这样我就可以用文本将该章的内容重写为:
1这是一节诗。 这是一节诗。 3这是一节诗。 ,这是一个佩里科普, 这是这个佩里科普的参考资料。 4这是一节诗。 5这是一节诗。 6这是一节引语: “这就是内容。 引用一段话; 或口语“ 这是另一个潜望镜 ..。
似乎找不到一种使用Selenium的方法,但是如果有,它会是什么呢?
回答 1
Stack Overflow用户
发布于 2017-12-04 13:49:54
尝试这个代码块并更新我的状态:
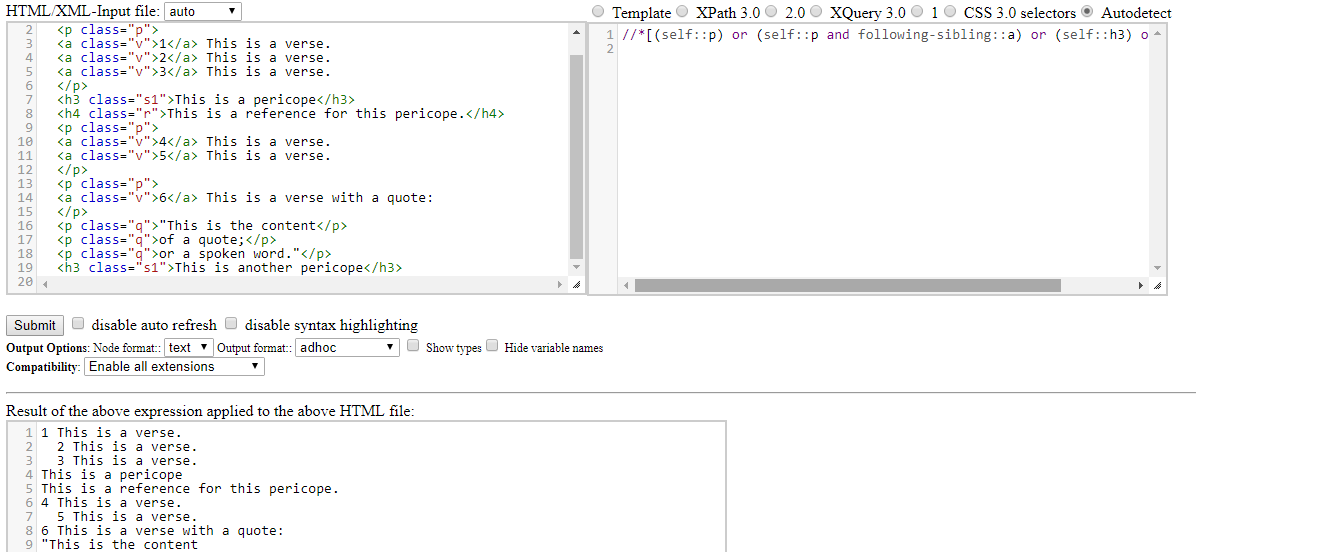
IList<IWebElement> elements = driver.FindElements(By.xpath("//*[(self::p) or (self::p and following-sibling::a) or (self::h3) or (self::h4)]"));
foreach (IWebElement element in elements)
{
string my_text = element.GetAttribute("innerHTML");
Console.WriteLine(my_text);
}我的控制台上的输出如下:
1 This is a verse.
2 This is a verse.
3 This is a verse.
This is a pericope
This is a reference for this pericope.
4 This is a verse.
5 This is a verse.
6 This is a verse with a quote:
"This is the content
of a quote;
or a spoken word."
This is another pericope最新情况:
看到xpath是正确的,并返回正确的结果。以下是快照:
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/47633978
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号