
如何使用python提取pdf文件中每一行的文本
如何使用python提取pdf文件中每一行的文本
提问于 2017-11-24 00:27:59
我经历了许多从pdf文件中提取数据的解决方案,但没有找到解决这个问题的方法。
我有一个pdf文件,其中包含以下数据格式
UPC Product Description Subcategory Name Pkg type
018894300199 Big Y Mozzarella String 16oz 16oz Pkg Cheese PKG
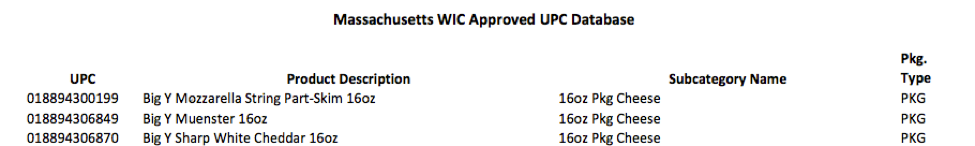
我需要使用python为pdf文件的每一行提取UPC、和Sub名称
我能够使用下面的代码从pdf文件中提取文本。
from PyPDF2 import PdfFileReader, PdfFileWriter
pdfFileObj = open('grocery2.pdf', 'rb')
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
print(pdfReader.numPages)
pageObj = pdfReader.getPage(1)
pagecontent = pageObj.extractText()我有超过500页的产品数据。对于页面的每一行,提取UPC、产品描述和子名称的最有效方法是什么?
回答 1
Stack Overflow用户
发布于 2017-11-24 00:54:20
由于它们是由空格来区分的,而且您的字符串本身也有空格,所以使用提取的文本可能不会太有帮助。我必须查看完整的pdf文件才能知道这是否有效,但请尝试:
From tabula import read_pdf
df = read_pdf("grocery2.pdf")然后,您可以执行任何数据挖掘操作来提取不同的值,即。
df1 = df[['UPC', 'Product Description']]页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/47464866
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号