
熊猫人类指数
熊猫人类指数
提问于 2017-09-28 11:38:23
可能以前有人问过这个问题,但我找不到任何信息
df = pd.DataFrame(
{"i1":[1,1,1,1,2,4,4,2,3,3,3,3],
"i2":[1,3,2,2,1,1,2,2,1,1,3,2],
"d1":['c1','ac2','c3','c4','c5','c6','c7','c8','c9','c10','c11','a']}
)
df.set_index('d1', inplace=True)
df.sortlevel()收益率
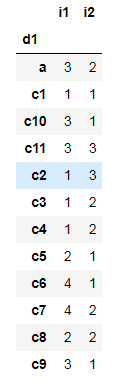
显然,这是不可取的。我想把c10和c11放在最后。如何为排序算法提供密钥(例如,拆分字符串和ints)?
回答 2
Stack Overflow用户
回答已采纳
发布于 2017-09-28 11:56:30
使用sorted和key的普通蟒蛇
您可以定义一个函数,以便将索引拆分为一对字母(字符串)和数字(作为整数):
d1 = ['c1','ac2','c3','c4','c5','c6','c7','c8','c9','c10','c11','a']
import re
pattern = re.compile('([a-z]+)(\d*)', re.I)
def split_index(idx):
m = pattern.match(idx)
if m:
letters = m.group(1)
numbers = m.group(2)
if numbers:
return (letters, int(numbers))
else:
return (letters, 0)例如:
>>> split_index('a')
('a', 0)
>>> split_index('c11')
('c', 11)
>>> split_index('c1')
('c', 1)然后,可以将此函数用作按字典顺序对索引进行排序的键:
print(sorted(d1, key=split_index))
# ['a', 'ac2', 'c1', 'c3', 'c4', 'c5', 'c6', 'c7', 'c8', 'c9', 'c10', 'c11']熊猫分类
您可以使用split_index中的元组创建一个新的临时列,根据该列进行排序并删除它:
import pandas as pd
df = pd.DataFrame(
{"i1":[1,1,1,1,2,4,4,2,3,3,3,3],
"i2":[1,3,2,2,1,1,2,2,1,1,3,2],
"d1":['c1','ac2','c3','c4','c5','c6','c7','c8','c9','c10','c11','a']}
)
df['order'] = df['d1'].map(split_index)
df.sort_values('order', inplace=True)
df.drop('order', axis=1, inplace=True)
df.set_index('d1', inplace=True)
print(df)它的产出如下:
i1 i2
d1
a 3 2
ac2 1 3
c1 1 1
c3 1 2
c4 1 2
c5 2 1
c6 4 1
c7 4 2
c8 2 2
c9 3 1
c10 3 1
c11 3 3Stack Overflow用户
发布于 2017-09-28 12:00:56
我认为您需要从index值中提取数字,并对extracted numbers (\d+)创建的MultiIndex和sort_index创建的非数字(\D+)进行排序。
#change ordering from default
df = df.sort_index(ascending=False)
a = df.index.str.extract('(\d+)', expand=False).astype(float)
b = df.index.str.extract('(\D+)', expand=False)
df.index = [b, a, df.index]
print (df)
i1 i2
d1 d1 d1
c 9.0 c9 3 1
8.0 c8 2 2
7.0 c7 4 2
6.0 c6 4 1
5.0 c5 2 1
4.0 c4 1 2
3.0 c3 1 2
11.0 c11 3 3
10.0 c10 3 1
1.0 c1 1 1
ac 2.0 ac2 1 3
a NaN a 3 2df = df.sort_index(level=[0,1]).reset_index([0,1], drop=True)
print (df)
i1 i2
d1
a 3 2
ac2 1 3
c1 1 1
c3 1 2
c4 1 2
c5 2 1
c6 4 1
c7 4 2
c8 2 2
c9 3 1
c10 3 1
c11 3 3np.lexsort只使用numeric :(
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/46468195
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号