
Jenkins从脱机节点连接超时/关闭-码头容器-重新启动步骤-配置正在选择老港口
Jenkins版本: 1.643.2
Docker插件版本: 0.16.0
在我的Jenkins环境中,我有一个Jenkins主服务器,它有2-5个从节点服务器(slave1、slave2、slave3)。
使用Docker插件在Jenkins全局配置中配置了每个从站。
一切都在这一刻起作用。
我看到我们的监控系统在slave3上抛出了一些高交换空间使用率的警报(针对ex : 11.22.33.44),所以我转到了这台机器上,并运行了:sudo docker ps,它给了我这个slave3机器上当前正在运行的码头容器的有效输出。
通过在目标从机上运行ps -eo pmem,pcpu,vsize,pid,cmd | sort -k 1 -nr | head -10 (其中4个容器正在运行),我发现前5个进程占用了每个容器内运行的所有内存java -jar slave.jar。所以我想为什么不重新启动,然后恢复一些内存。在下面的输出中,我看到了sudo docker ps命令在docker restart <container_instance>步骤前后的状态。向右滚动,您将注意到,在以...0a02结尾的容器ID的第2行中,主机(slave3)机器上的虚拟端口(列在标题NAMES下)为1053 (该端口映射到容器的虚拟IP端口22,用于SSH)。酷,这意味着,在Jenkins Manage Node部分,如果您试图重新启动一个奴隶的容器,Jenkins将尝试连接到主机IP的11.22.33.44:1053,并做任何它应该成功地唤醒奴隶的事情。所以,詹金斯把那个港口(1053)放在某个地方。
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ae3eb02a278d docker.someinstance.coolcompany.com:443/jenkins-slave-stable-image:1.1 "bash -c '/usr/sbin/s" 26 hours ago Up 26 hours 0.0.0.0:1048->22/tcp lonely_lalande
d4745b720a02 docker.someinstance.coolcompany.com:443/jenkins-slave-stable-image:1.1 "bash -c '/usr/sbin/s" 9 days ago Up About an hour 0.0.0.0:1053->22/tcp cocky_yonath
bd9e451265a6 docker.someinstance.coolcompany.com:443/jenkins-slave-stable-image:1.1 "bash -c '/usr/sbin/s" 9 days ago Up About an hour 0.0.0.0:1050->22/tcp stoic_bell
0e905a6c3851 docker.someinstance.coolcompany.com:443/jenkins-slave-stable-image:1.1 "bash -c '/usr/sbin/s" 9 days ago Up About an hour 0.0.0.0:1051->22/tcp serene_tesla
sudo docker restart d4745b720a02; echo $?
d4745b720a02
0
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ae3eb02a278d docker.someinstance.coolcompany.com:443/jenkins-slave-stable-image:1.1 "bash -c '/usr/sbin/s" 26 hours ago Up 26 hours 0.0.0.0:1048->22/tcp lonely_lalande
d4745b720a02 docker.someinstance.coolcompany.com:443/jenkins-slave-stable-image:1.1 "bash -c '/usr/sbin/s" 9 days ago Up 4 seconds 0.0.0.0:1054->22/tcp cocky_yonath
bd9e451265a6 docker.someinstance.coolcompany.com:443/jenkins-slave-stable-image:1.1 "bash -c '/usr/sbin/s" 9 days ago Up About an hour 0.0.0.0:1050->22/tcp stoic_bell
0e905a6c3851 docker.someinstance.coolcompany.com:443/jenkins-slave-stable-image:1.1 "bash -c '/usr/sbin/s" 9 days ago Up About an hour 0.0.0.0:1051->22/tcp serene_tesla运行sudo docker restart <instanceIDofContainer>之后,我运行了free -h / grep -i swap /proc/meminfo,发现内存(之前已经充分使用,只显示剩余的230 10空闲)现在是1GB空闲的,交换大小为1G总计,1G使用(我尝试了60或10),现在是450 10的交换空间空闲。所以警报问题就解决了。凉爽的。
但是,正如您从上面的sudo docker ps输出中注意到的,在重新启动步骤之后,对于容器ID ...0a02,我现在得到了一个新的PORT# 1054!!
当我去管理节点>试图使这个节点离线,停止它,并重新启动它,Jenkins没有拿起新的端口(1054)。它仍然在以某种方式选择旧端口1053 (同时试图在端口1053上连接到11.22.33.44 (主机的IP) (该端口映射到容器的虚拟IP端口# 22 ( SSH ))。
如何在Jenkins中更改这个从容器的端口或配置,以便Jenkins能够看到新端口并成功地重新启动?
PS:单击节点上的“配置”以查看它的配置,除了Name字段之外,没有显示其他任何东西。通常,在常规从属程序中有很多字段(您可以定义标签、根dir、启动方法、属性env变量、从环境的工具,但我猜对于这些Docker容器,除了Name字段之外,我什么也看不到)。单击中的Test Connection (在 Docker 插件部分)显示它正在成功地找到Docker 1.8.3版本
现在,由于1053端口(telnet)无法工作,因为这个容器的instanceID现在是1054 (重新启动步骤之后),Jenkins重新启动步骤在SSH连接步骤期间失败(它通过SSH方法进行连接的第一件事)。

[07/27/17 17:17:19] [SSH] Opening SSH connection to 11.22.33.44:1053.
Connection timed out
ERROR: Unexpected error in launching a slave. This is probably a bug in Jenkins.
java.lang.IllegalStateException: Connection is not established!
at com.trilead.ssh2.Connection.getRemainingAuthMethods(Connection.java:1030)
at com.cloudbees.jenkins.plugins.sshcredentials.impl.TrileadSSHPasswordAuthenticator.canAuthenticate(TrileadSSHPasswordAuthenticator.java:82)
at com.cloudbees.jenkins.plugins.sshcredentials.SSHAuthenticator.newInstance(SSHAuthenticator.java:207)
at com.cloudbees.jenkins.plugins.sshcredentials.SSHAuthenticator.newInstance(SSHAuthenticator.java:169)
at hudson.plugins.sshslaves.SSHLauncher.openConnection(SSHLauncher.java:1212)
at hudson.plugins.sshslaves.SSHLauncher$2.call(SSHLauncher.java:711)
at hudson.plugins.sshslaves.SSHLauncher$2.call(SSHLauncher.java:706)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
[07/27/17 17:19:26] Launch failed - cleaning up connection
[07/27/17 17:19:26] [SSH] Connection closed.回答 1
Stack Overflow用户
发布于 2017-07-28 01:59:29
好的。齐修斯!
在JENKINS_HOME (主服务器)中,我搜索了哪个配置文件保存了那个/那些现在显示为脱机的容器节点的旧port#信息。
将目录更改为:$JENKINS_HOME中的节点文件夹,发现每个节点都有config.xml文件。
ex:$JENKINS_HOME/nodes/<slave3_node_IP>-d4745b720a02/config.xml
解析步骤
- Vim编辑了该文件,以便用新端口更改旧文件。
- 从磁盘管理Jenkins > Reload配置。
- 管理节点>选择脱机的特定节点。
- 重新启动从服务器,这次Jenkins选择了新的端口,并按预期启动了容器从(在配置更改后可以看到到新端口的SSH连接)。
我想这个页面:https://my.company.jenkins.instance.com/projectInstance/docker-plugin/server/<slave3_IP>/ web页面,它显示了所有容器的信息(以表格形式运行在给定的从机上),该页面有一个按钮(最后一列),用于停止给定奴隶容器的,而不是启动或重新启动。
有一个、START、或重新启动按钮,应该可以以某种方式完成我刚才所做的工作。
更好的解决方案:
正在发生的情况是,运行在slave3上的所有4个长寿命容器节点都在竞争获取所有可用的RAM (11-12GB),并且随着时间的推移,单个容器的JVM进程(java -jar slave.jar,重新启动步骤开始于在slave3从服务器上运行的目标容器的虚拟机(IP) )试图占用尽可能多的内存。这导致低空闲内存,从而交换,被使用,也被使用到一个点,一个监控工具将开始尖叫,通过发送通知等。
要解决这种情况,首先要做的是:
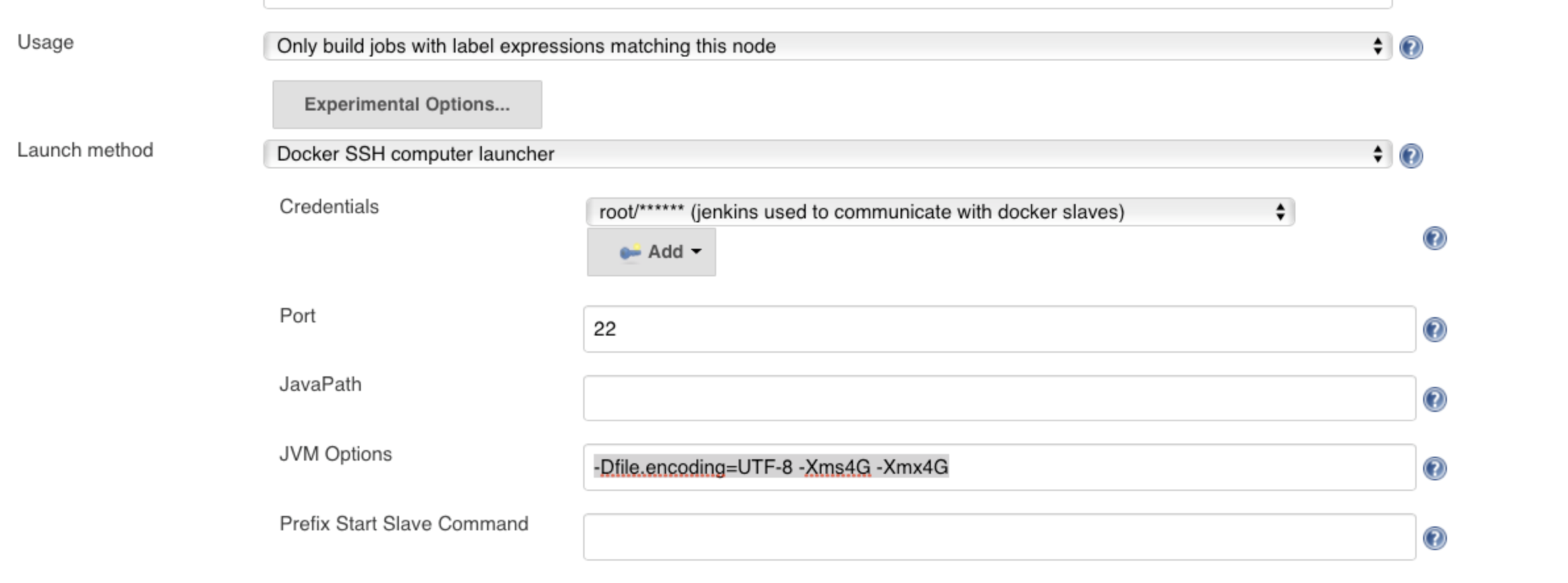
1)在(Manage > configuration > Docker部分)下,对于从服务器的图像/ Docker模板,在高级设置部分下,我们可以放置JVM选项,告诉容器不要竞争所有RAM。放置以下JVM选项会有所帮助。这些JVM设置将尽量将每个容器的堆空间保持在一个较小的盒子中,以免使系统的其余部分挨饿。
您可以从3-4GB开始,这取决于您的从/机器上运行基于容器的从节点的内存总量。
2)寻找slave.jar的任何最新版本(它可能具有一些性能/维护增强功能,这将有所帮助。
3)集成监视解决方案(Incinga/etc,您必须)自动启动Jenkins作业( Jenkins作业将运行一些操作-- BASH one liner、Python shit或Groovy Groovy、Ansible剧本等),以修复与任何此类警报相关的问题。
4)自动重新启动容器从节点(即重新启动步骤)--采取从离线、联机、重新启动的步骤,这将使从属节点恢复到更新的新鲜状态。我们所要做的就是,寻找一个空闲的从属程序(如果它没有运行任何作业),然后将它脱机>然后在线>,然后通过一个小的Groovy脚本使用Jenkins REST重新启动这个奴隶,并将所有这些都放到Jenkins作业中,如果这些从节点长期存在,让它执行上面的操作。
5)或者可以在每次Jenkins排队运行作业时使用并抛出基于容器的奴隶-使用和抛出模型。
https://stackoverflow.com/questions/45363095
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号