
numpy.shares_memory和numpy.may_share_memory有什么区别?
为什么numpy.may_share_memory存在?
给出确切结果的挑战是什么?
numpy.may_share_memory不推荐的方法吗?
numpy.may_share_memory可能会给出假阳性,但它不会给假阴性。
numpy.shares_memory没有给出一个假阳性和一个假阴性吗?
我使用numpy版本的1.11.2。
请参见:
回答 2
Stack Overflow用户
发布于 2017-07-01 21:12:08
添加了一个新函数
np.shares_memory,它可以检查两个数组是否有内存重叠。np.may_share_memory现在也可以选择花费更多的精力来减少假阳性。
在语义上,这意味着旧的may_share_memory测试的设计是为了对数组之间是否共享内存进行松散的猜测。如果肯定没有,那么我们就可以这样做。如果检测呈阳性(可能是假阳性),则必须采取谨慎措施。另一方面,新的shares_memory函数允许进行精确的检查。这需要更多的计算时间,但从长远来看是有益的,因为没有假阳性,可以使用更多可能的优化。对may_share_memory的更宽松的检查可能只是保证不返回假阴性。
就may_share_memory和shares_memory的文档而言,它们都有一个关键字参数,它告诉numpy用户需要多严格的检查。
may_share_memory
max_work : int, optional
Effort to spend on solving the overlap problem. See shares_memory for details. Default for may_share_memory is to do a bounds check.shares_memory
max_work : int, optional
Effort to spend on solving the overlap problem (maximum number of candidate solutions to consider). The following special values are recognized:
max_work=MAY_SHARE_EXACT (default)
The problem is solved exactly. In this case, the function returns True only if there is an element shared between the arrays.
max_work=MAY_SHARE_BOUNDS
Only the memory bounds of a and b are checked.从文档判断,这表明这两个函数可能调用相同的底层机器,但是may_share_memory对检查使用了一个不那么严格的默认设置。
让我们看一看在实施中
static PyObject *
array_shares_memory(PyObject *NPY_UNUSED(ignored), PyObject *args, PyObject *kwds)
{
return array_shares_memory_impl(args, kwds, NPY_MAY_SHARE_EXACT, 1);
}
static PyObject *
array_may_share_memory(PyObject *NPY_UNUSED(ignored), PyObject *args, PyObject *kwds)
{
return array_shares_memory_impl(args, kwds, NPY_MAY_SHARE_BOUNDS, 0);
}使用签名调用相同的基础函数
static PyObject *
array_shares_memory_impl(PyObject *args, PyObject *kwds, Py_ssize_t default_max_work,
int raise_exceptions)
{}在我看来,不深入探究源代码,shares_memory似乎是对may_share_memory的一种改进,它可以提供与后者相同的松散检查,并使用适当的关键字参数。较旧的函数可用于方便和向后兼容。
免责声明:这是我第一次查看源代码的这一部分,我没有进一步研究array_shares_memory_impl,所以我的印象可能是完全错误的。
至于这两个方法之间区别的一个具体例子(用默认参数调用):在上面的链接中解释了may_share_memory只检查数组绑定索引。如果两个数组是不相交的,那么它们就不可能共享内存。但是,如果它们不是不相交的,数组仍然可以是独立的!
简单示例:通过切片对连续内存块进行不相交的分区:
>>> import numpy as np
>>> v = np.arange(6)
>>> x = v[::2]
>>> y = v[1::2]
>>> np.may_share_memory(x,y)
True
>>> np.shares_memory(x,y)
False
>>> np.may_share_memory(x,y,max_work=np.MAY_SHARE_EXACT)
False如您所见,x和y是同一数组的两个不相交的切片。因此,它们的数据范围基本上是重叠的(它们几乎相同,在内存中保存一个整数)。然而,它们中没有一个元素实际上是相同的:一个包含偶数元素,另一个包含原始连续块的奇数元素。因此,may_share_memory正确地断言数组可能共享内存,但经过更严格的检查,结果发现它们没有共享内存。
至于精确计算重叠的额外困难,这项工作可以追溯到名为solve_may_share_memory的工作人员,它还包含了关于正在发生的事情的许多有用的评论。简而言之,
- 如果边界不重叠,则为
a quick check and return。 - 如果我们请求松散检查(即带有默认args的
MEM_OVERLAP_TOO_HARD),即在呼叫端处理作为“我们不知道,所以返回True” - 否则,我们实际上解决了问题映射到从这里开始的丢番图方程。
因此,上面第3点中的工作是shares_memory需要额外完成的工作(或者通常是严格检查的情况)。
Stack Overflow用户
发布于 2017-07-02 00:37:00
在阅读以下内容之前,请阅读:
http://scipy-cookbook.readthedocs.io/items/ViewsVsCopies.html
实际上,问题是如何为两个跨数组( a和b )找到内存重叠
请参阅实施NumPy (读取标题中的注释很重要)。
这个问题相当于:
求具有正系数的有界丢番图方程的解
以一维数组为例:
import numpy as np
x = np.arange(8, dtype=np.int8)
a = x[::3]
b = x[1::2]在记忆中我们有:
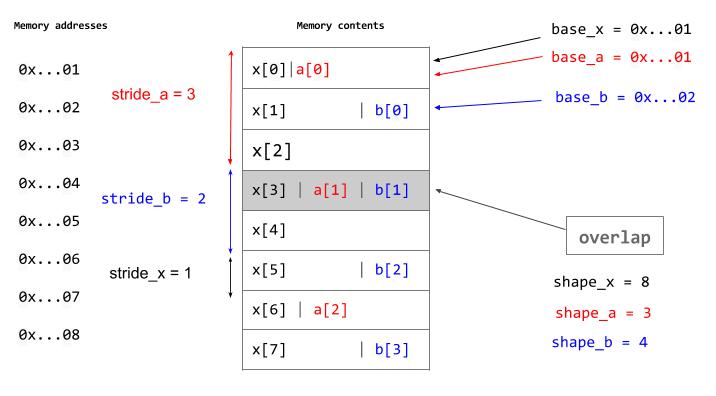
一维阵列是内存中的连续结构。我假设我们的内存有64位地址(8个字节),并且我们的数组中的每个元素都有一个字节大小(0 <= np.int8 <256个)。
要解决重叠问题,a的一个元素的可能内存地址是:
base_a + stride_a * x_a,其中x_a是一个变量(基于数组索引0)。
对于b,我们也有同样的看法:
base_b + stride_b * x_b,其中x_b是一个变量(基于数组索引0)。
有重叠的当且仅当:
base_a + stride_a * x_a = base_b + stride_b * x_b
我们有:
stride_a * x_a - stride_b * x_b = base_b - base_a
0 <= x_a < shape_a和0 <= x_b < shape_b。
我们可以转换所有负系数,而不是从上到下读取b,我们可以通过变量更改从下到上读取:
x_b' = shape_b - 1 - x_b
我们获得:
stride_a * x_a + stride_b * x_b = base_b + stride_b * (shape_b - 1) - base_a
在此:
3 x_a + 2 x_b = 7 (= 1 + 2 * (4 - 1))
0 <= x_a < 3和0 <= x_b < 4。
一个解决方案是x_a = 1和x_b = 2 (从底部读取x_b)。
……
我们可以很容易地对2D数组和XD数组进行推广,并且每个数组元素需要多个字节(例如,4个字节,所有数组元素在内存中都是必需的)。
这是一个我的github上的朴素解决方案以及与NumPy实现的性能比较。
..。
https://stackoverflow.com/questions/44865261
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号