
将每个RDD值与scala中RDD中的所有其他值配对
将每个RDD值与scala中RDD中的所有其他值配对
提问于 2017-03-31 03:12:15
我试图将RDD中的每个值与相同RDD的所有其他值配对。但我想不出正确的解决办法。
RDD :下面的图像用对as->表示RDD数据(UserId,MovieName::R等级)。
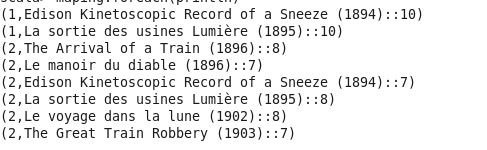
我想将每个用户的电影名称和评分配对如下:
从上面的图片:
- 用户1级爱迪生运动镜。如10和La sortie.as 10
- 用户2级到达..。as 8,Le manoir.如7,爱迪生运动镜。如7等.
所以输出应该是..。
**key**: (Edison Kinetoscopic,La sortie des)
**Value** : (10,10), (7,8) -> Since user 1 and user two rated these two movies
**Key**: (The Arrival, Le manoir)
**value**: (8,7) -> only user-2 rated these two movies. 任何帮助都很感激。
回答 1
Stack Overflow用户
回答已采纳
发布于 2017-03-31 09:47:43
如果你想建立一个推荐系统,或者计算电影和电影的相似性,那么一定有更好的方法来做到这一点。
但是,要解决问题,可以执行以下操作:
val rdd = sc.parallelize(List(
(1,"Edison", 10),
(1,"La sortie", 10),
(2,"The Arrival", 8),
(2,"Le manoir", 7),
(2,"Edison", 7),
(2,"La sortie", 8),
(2,"Le voyage", 8),
(2,"The Great", 7)
))
// first group user movies
val pairings = rdd.map{case (user,movie,rating) => (user, List((movie,rating)))}.reduceByKey(_++_)
// then get all pairs for each user
val allPairs = pairings.flatMap{case (user, movieRatings) => (1 until movieRatings.length).flatMap(i => movieRatings.zip(movieRatings drop i))}
// re-structure pairings into format we want
val finalPairing = allPairs.map{case ((m1,r1),(m2,r2)) => m1.compareTo(m2) match {case -1 => ((m1,m2),List((r1,r2))); case _ => ((m2,m1),List((r2,r1)))}}.
// group by pairings
val groupByPair = finalPairing.reduceByKey(_++_)
// look at our pairings
pairings.take(100).foreach(println)需要使用compareTo来保证电影以相同的顺序出现在元组中,因此可以分组。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/43131764
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号