
如何使用h5py库存储时间序列数据?
如何使用h5py库存储时间序列数据?
提问于 2016-12-15 21:00:32
我有一些以前使用hdf5作为pytables文件存储的时间序列数据。最近,我尝试用h5py库存储同样的内容。但是,由于numpy数组的所有元素都必须是相同的dtype,所以在使用h5py库存储它之前,我必须将日期(通常是索引)转换为'float64‘类型。当我使用pytables**,时,索引及其dtype被保留下来,这使得我可以查询时间序列,而不需要将其全部提取到内存中。我想使用** h5py 是不可能的。我是不是遗漏了什么?,如果没有,在什么情况下我应该使用h5py库来存储时间序列数据?我问这个问题的原因,澄清这一点可以帮助我设计一个更有效的(处理和存储)项目。
下面是简单的代码,为了将其存储为单个dtype对象,我必须丢失索引信息。
dt_range = pd.date_range('2016-12-01','2016-12-10')
data = np.arange(0,20).reshape(-1,2)
df = pd.DataFrame(data,index = dt_range, columns = list('ab'), dtype = 'float')
df.index = df.index.to_julian_date()
df = df.reset_index()
h = h5py.File(r'path\temp.h5', 'w')
dset = h.create_dataset('temp',data = df.values, shape = (10,3))回答 2
Stack Overflow用户
发布于 2016-12-15 22:54:22
我会用熊猫to_hdf
dt_range = pd.date_range('2016-12-01','2016-12-10')
data = np.arange(0,20).reshape(-1,2)
df = pd.DataFrame(data,index = dt_range, columns = list('ab'), dtype = 'float')
df.index = df.index.to_julian_date()
df = df.reset_index()
with pd.HDFStore('temp.h5', 'w') as h:
df.to_hdf(h, 'temp')
pd.read_hdf('temp.h5', 'temp')
Stack Overflow用户
发布于 2016-12-15 23:04:35
当我运行@piRSquared代码并查看带有h5py的文件时,我看到:
In [4]: import h5py
In [5]: f=h5py.File('temp.h5')
In [8]: list(f.keys())
Out[8]: ['temp']
In [9]: f['temp']
Out[9]: <HDF5 group "/temp" (4 members)>
In [10]: list(f['temp'].keys())
Out[10]: ['axis0', 'axis1', 'block0_items', 'block0_values']
In [11]: f['temp']['axis0'][:]
Out[11]:
array([b'index', b'a', b'b'],
dtype='|S5')
In [12]: f['temp']['axis1'][:]
Out[12]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=int64)
In [13]: f['temp']['block0_items'][:]
Out[13]:
array([b'index', b'a', b'b'],
dtype='|S5')
In [14]: f['temp']['block0_values'][:]
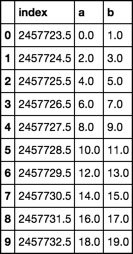
Out[14]:
array([[ 2.45772350e+06, 0.00000000e+00, 1.00000000e+00],
[ 2.45772450e+06, 2.00000000e+00, 3.00000000e+00],
[ 2.45772550e+06, 4.00000000e+00, 5.00000000e+00],
[ 2.45772650e+06, 6.00000000e+00, 7.00000000e+00],
[ 2.45772750e+06, 8.00000000e+00, 9.00000000e+00],
[ 2.45772850e+06, 1.00000000e+01, 1.10000000e+01],
[ 2.45772950e+06, 1.20000000e+01, 1.30000000e+01],
[ 2.45773050e+06, 1.40000000e+01, 1.50000000e+01],
[ 2.45773150e+06, 1.60000000e+01, 1.70000000e+01],
[ 2.45773250e+06, 1.80000000e+01, 1.90000000e+01]])因此,它将索引信息保存在3个系列中,将值保存在另一个系列中,后者以2d numpy数组的形式加载。
这是我希望从pytables创建的文件中看到的相同类型的信息。
根据它的文档,pd.HDFStore正在使用pytables。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/41173254
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号