
R-消除重复值
R-消除重复值
提问于 2016-10-19 08:02:58
我有这样一个输入数据:
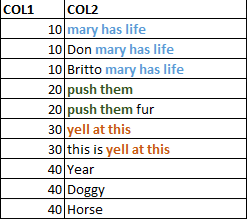
我希望输出是这样的:
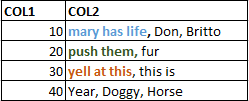
例如,我想使用第一个值(mary有生命),扫描它以针对所有具有重复COL1条目的其他行,如果存在重复的COL2值,则需要在合并非重复项时单独消除重复值。换句话说,我想做模式搜索。如果在另一行中存在相同的模式,我只想消除重复的模式并合并非重复的模式。
我尝试使用grepl和gsub函数,但是我无法正确地获得我想要的结果。
插入更简单版本的输入数据集如下:
COL1 COL2 10玛丽有生命10唐玛丽有生命玛丽有生命20推他们20推他们皮毛30大喊这30岁这是40岁的狗40马
回答 1
Stack Overflow用户
回答已采纳
发布于 2016-10-19 12:00:12
更新后:
df <- read.table(
text = "COL1; COL2
10; mary has life
10; Don mary has life
10; Britto mary has life
20; push them
20; push them fur
30; yell at this
30; this is yell at this",
sep = ";", header = TRUE,
strip.white = TRUE, stringsAsFactors = FALSE)
library(dplyr)
res <- df %>%
group_by(COL1) %>%
do(COL2 = {
first_value <- .$COL2[[1]]
paste(unlist(Reduce(function(a, b) {
new_values <- strsplit(b, first_value)[[1]]
c(a, new_values)
}, .$COL2)), collapse = ", ")
})
res$COL2 <- unlist(res$COL2)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/40125508
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号