
设置一个行索引并使用多个索引列查询熊猫数据
设置一个行索引并使用多个索引列查询熊猫数据
提问于 2016-09-28 11:02:25
从具有如下多维列标题结构的pandas数据rows开始,是否有一种方法可以转换Area Names和Area Codes标题,使它们跨越每个级别(也就是说,跨越多列标题行的单个Area Names和Area Codes标签?
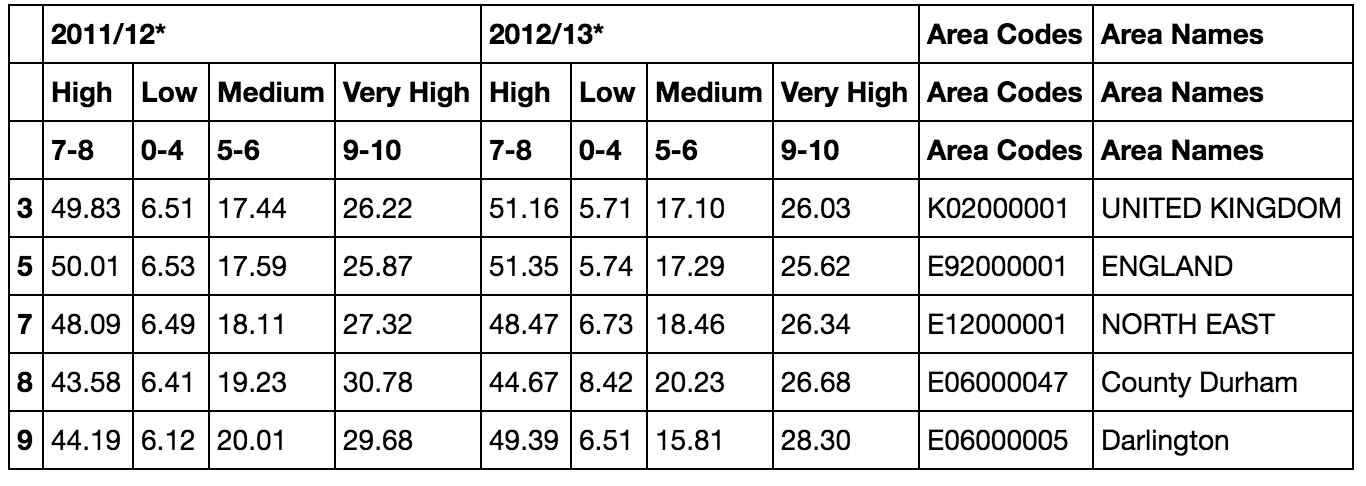
如果是这样的话,我如何才能在该列上运行一个查询,以返回与特定值对应的行(例如,E06000047区号),或者返回2012/13年度英格兰的低值和极高值
我想知道,根据区域代码或区域名称或两列行索引['*Area Code*', '*Area Names*']来定义行索引是否更容易。如果是这样的话,我如何才能从当前的表中做到这一点呢?使用当前的结构,set_index似乎对此犹豫不决?
创建上述代码片段的代码片段:
import pandas as pd
df= pd.DataFrame({('2011/12*', 'High', '7-8'): {3: 49.83,
5: 50.01,
7: 48.09,
8: 43.58,
9: 44.19},
('2011/12*', 'Low', '0-4'): {3: 6.51, 5: 6.53, 7: 6.49, 8: 6.41, 9: 6.12},
('2011/12*', 'Medium', '5-6'): {3: 17.44,
5: 17.59,
7: 18.11,
8: 19.23,
9: 20.01},
('2011/12*', 'Very High', '9-10'): {3: 26.22,
5: 25.87,
7: 27.32,
8: 30.78,
9: 29.68},
('2012/13*', 'High', '7-8'): {3: 51.16,
5: 51.35,
7: 48.47,
8: 44.67,
9: 49.39},
('2012/13*', 'Low', '0-4'): {3: 5.71, 5: 5.74, 7: 6.73, 8: 8.42, 9: 6.51},
('2012/13*', 'Medium', '5-6'): {3: 17.1,
5: 17.29,
7: 18.46,
8: 20.23,
9: 15.81},
('2012/13*', 'Very High', '9-10'): {3: 26.03,
5: 25.62,
7: 26.34,
8: 26.68,
9: 28.3},
('Area Codes', 'Area Codes', 'Area Codes'): {3: 'K02000001',
5: 'E92000001',
7: 'E12000001',
8: 'E06000047',
9: 'E06000005'},
('Area Names', 'Area Names', 'Area Names'): {3: 'UNITED KINGDOM',
5: 'ENGLAND',
7: 'NORTH EAST',
8: 'County Durham',
9: 'Darlington'}})回答 1
Stack Overflow用户
回答已采纳
发布于 2016-09-28 11:09:08
我认为您需要set_index和元组,以便由MultiIndex设置
df.set_index([('Area Codes','Area Codes','Area Codes'),
('Area Names','Area Names','Area Names')], inplace=True)
df.index.names = ['Area Codes','Area Names']
print (df)
2011/12* 2012/13* \
High Low Medium Very High High Low
7-8 0-4 5-6 9-10 7-8 0-4
Area Codes Area Names
K02000001 UNITED KINGDOM 49.83 6.51 17.44 26.22 51.16 5.71
E92000001 ENGLAND 50.01 6.53 17.59 25.87 51.35 5.74
E12000001 NORTH EAST 48.09 6.49 18.11 27.32 48.47 6.73
E06000047 County Durham 43.58 6.41 19.23 30.78 44.67 8.42
E06000005 Darlington 44.19 6.12 20.01 29.68 49.39 6.51
Medium Very High
5-6 9-10
Area Codes Area Names
K02000001 UNITED KINGDOM 17.10 26.03
E92000001 ENGLAND 17.29 25.62
E12000001 NORTH EAST 18.46 26.34
E06000047 County Durham 20.23 26.68
E06000005 Darlington 15.81 28.30 然后需要sort_index,因为:
KeyError:“MultiIndex切片要求索引为完整的词汇排序元组(2)、词汇排序深度(0)”
df.sort_index(inplace=True)切片机的最后使用选择
idx = pd.IndexSlice
print (df.loc[idx['E06000047',:], :])
2011/12* 2012/13* \
High Low Medium Very High High Low
7-8 0-4 5-6 9-10 7-8 0-4
Area Codes Area Names
E06000047 County Durham 43.58 6.41 19.23 30.78 44.67 8.42
Medium Very High
5-6 9-10
Area Codes Area Names
E06000047 County Durham 20.23 26.68 print (df.loc[idx[:,'ENGLAND'], idx['2012/13*',['Low','Very High']]])
2012/13*
Low Very High
0-4 9-10
Area Codes Area Names
E92000001 ENGLAND 5.74 25.62页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/39745627
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号