
如何计算查询的TF-以色列国防军?
如何计算查询的tf-idf?我理解如何计算一组文件的tf-以色列国防军,定义如下:
tf =发生在文档中/文档中的总单词 idf = log(#documents / #documents (其中出现术语)
但我不明白这和查询有什么关系。
例如,,我读了资源,它声明了查询"life learning“的值
寿命- tf = .5 学习情况: tf = .5 _tf= 1.405507153 _x tf_idf = 0.702753576
我理解的tf值,在两个可能的术语中,每个术语只出现一次,因此是1/2,但我不知道idf来自何处。
我认为#documents =1和case = 1,log(1) = 0,所以idf是0,但情况似乎并非如此。它是基于你使用的任何文件吗?如何计算查询的tf-以色列国防军?
回答 3
Stack Overflow用户
发布于 2016-08-18 04:03:26
只有tf(生命)取决于查询本身。但是,查询的idf依赖于背景文档,因此idf(生命)= 1+ ln(3/2) ~= 1.405507153。这就是tf被定义为将局部分量(术语频率)与全局分量(反向文档频率)相乘的原因。
Stack Overflow用户
发布于 2017-10-18 14:19:00
假设您的查询是最佳汽车保险,您的总词汇表包含car、best、auto、insurance,并且您有N=1,000,000文档。所以您的查询如下所示:
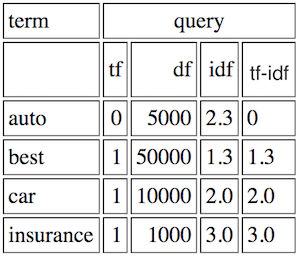
你的一份文件可能是:
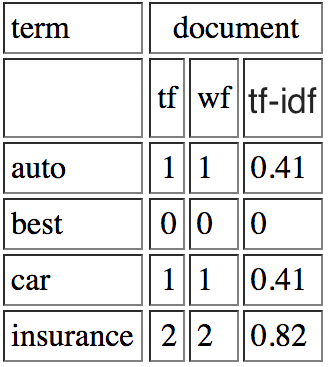
现在计算TF-IDF的Query和Document之间的余弦相似度。
Stack Overflow用户
发布于 2021-04-10 09:17:22
即使这个问题被标记为答案。我不觉得它被完全回答了。所以如果将来有人需要这个:
但我不知道国防军是从哪里来的。
在这个示例:项目3,第2部分:使用TF-国防军进行搜索中,介绍了如何计算查询和一组文档之间的余弦相似度。
正如@低毒所指出的,以色列国防军是一个全球组成部分,因此,一个词的以色列国防军对于每个文件都是相同的:
注意:从技术上讲,我们将查询视为一个新文档。但是,您不应该重新计算IDF值:只需使用前面计算的值即可。
https://stackoverflow.com/questions/37106194
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号