
C++11 std::cout <<“字符串文字在UTF-8”到Windows控制台?(Visual Studio 2015)
摘要:如何正确地将以UTF-8编码(Windows 65001)存储的源代码中定义的字符串文本打印到使用std::cout流的cmd控制台?
动机:I想要修改优秀的Catch单元测试框架 (作为一个实验),这样它就可以显示带有重音字符的我的短信。修改应该简单、可靠,对于其他语言和工作环境也应该有用,这样作者就可以接受它作为一种增强。或者,如果你知道Catch,如果有其他的解决方案,你能发布它吗?
详细信息:,让我们从捷克版的“快棕狐”开始。
#include <iostream>
#include "windows.h"
using namespace std;
int main()
{
cout << "\n-------------------------- default cmd encoding = 852 -------------------\n";
cout << "Příšerně žluťoučký kůň úpěl ďábelské ódy!" << endl;
cout << "\n-------- Windows Central European (1250) set for the cmd console --------\n";
SetConsoleOutputCP(1250);
std::cout << "Příšerně žluťoučký kůň úpěl ďábelské ódy!" << std::endl;
cout << "\n------------- Windows UTF-8 (65001) set for the cmd console -------------\n";
SetConsoleOutputCP(CP_UTF8);
std::cout << "Příšerně žluťoučký kůň úpěl ďábelské ódy!" << std::endl;
}它打印以下内容(字体设置为Lucida控制台):
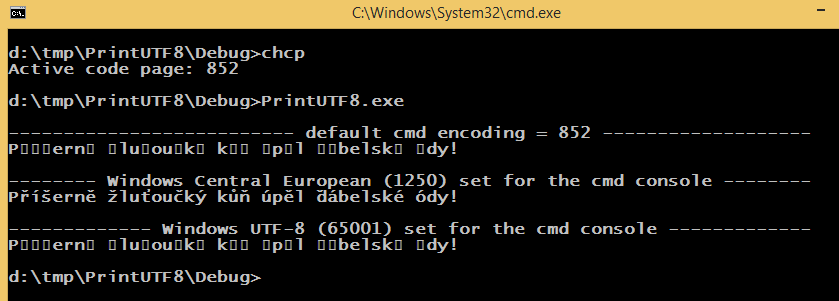
cmd默认编码为852,默认窗口编码为1250,源代码使用65001编码(UTF-8和BOM)保存。SetConsoleOutputCP(1250);以与chcp 1250相同的方式(以编程方式)更改cmd编码。
Observation:设置1250编码时,正确打印UTF-8字符串文字.我相信这是可以解释的,但这真的很奇怪。有什么像样的、人性化的方法来解决这个问题吗?
更新: "narrow string literal"是使用Windows1250编码存储的,在我的例子中(用于中欧的原生"narrow string literal"编码)。它似乎独立于源代码的编码。编译器将其保存在windows本机编码中。正因为如此,将cmd转换为该编码提供了所需的输出。这是个麻木不仁的问题,但我如何使本机窗口以编程方式编码(将其传递给SetConsoleOutputCP(cpX))?我需要的是一个对编译发生的机器有效的常量。它不应该是运行可执行文件的机器的本机编码。
C++11也引入了u8"the UTF-8 string literal",但它似乎不适合SetConsoleOutputCP(CP_UTF8);
回答 1
Stack Overflow用户
发布于 2015-09-01 14:45:41
这是通过跳过luk32的链接并确认Melebius的评论(见下面的问题)找到的部分答案。这不是完整的答案,我很乐意接受你的后续评论.
我刚刚找到了触及这个问题的UTF-8“世界各地宣言”。17.问:如何在我的C++代码中编写UTF-8字符串文字?说的要点(对于C++编译器也很明确):
但是,最简单的方法是按-原样编写字符串并保存以UTF-8编码的源文件: "∃y∀x (x≺y)“ 不幸的是,MSVC将其转换为某些ANSI代码页,从而破坏了字符串。若要解决此问题,请将文件保存在不带BOM的UTF-8中。MSVC将假设它在正确的代码页中,不会触及您的字符串。但是,它使得不可能使用Unicode标识符和宽字符串文本(无论如何都不会使用)。
我真的很喜欢宣言。为了使它简短,使用粗鲁的词语,并可能过于简化,它说:
忽略
wstring、wchar_t等诸如此类的东西。忽略代码页。忽略字符串字符串前缀,如L、u、U、u8。到处使用UTF-8。写所有的文字"naturally"。确保它也存储在编译后的二进制文件中。
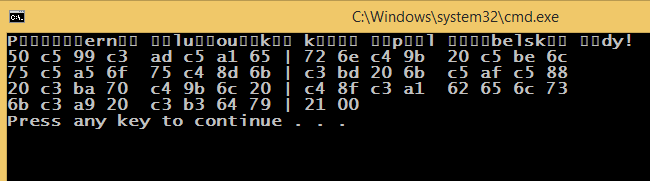
如果以下代码存储在没有BOM的UTF-8中.
#include <iomanip>
#include <iostream>
#include "windows.h"
using namespace std;
int main()
{
SetConsoleOutputCP(CP_UTF8);
cout << "Příšerně žluťoučký kůň úpěl ďábelské ódy!" << endl;
int cnt = 0;
for (unsigned int c : "Příšerně žluťoučký kůň úpěl ďábelské ódy!")
{
cout << hex << setw(2) << setfill('0') << (c & 0xff);
++cnt;
if (cnt % 16 == 0) cout << endl;
else if (cnt % 8 == 0) cout << " | ";
else if (cnt % 4 == 0) cout << " ";
else cout << ' ';
}
cout << endl;
}它的指纹(应该是UTF-8编码).
当使用BOM将源保存为UTF-8时,它会打印一个不同的结果.
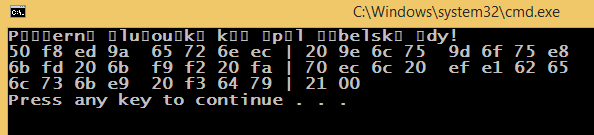
但是,问题仍然存在--如何以编程方式设置控制台编码,以便正确打印UTF-8字符串。
--我放弃了。-- cmd控制台只是瘫痪了,从外部修复它是不值得的。我接受我自己的评论,只是结束了这个问题。如果有人找到了与Catch单元测试框架相关的合适的解决方案(可能完全不同),我将很乐意接受他/她的评论作为答案。
https://stackoverflow.com/questions/32330970
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号