
如何识别元组/3项元组列表的“键”?
因此,给出一份收入价值表:
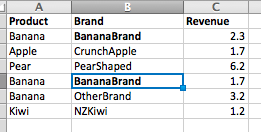
需要注意的一个关键点(以及我问题的核心)是品牌名称will will几乎总是,但并不总是包含相应的产品名称。在最后一次香蕉入场的情况下,没有。
我将提取Brand<->Revenue对的dict,首先对有多个条目的品牌进行统计,然后使用描述这里的方法对这些情况进行求和。所以:
revenuePerBrandDict = {}
brandRevenueTuples = []
i=0
for brand in ourTab.columns[1][1:-1]: # ignore first (zeroth) and last row
brandRevenueTuples.append((campaign.value, round(ourTab.columns[3][i].value,2)))
i+=1
for key, value in brandRevenueTuples:
revenuePerBrandDict[key] = revenuePerBrandDict.get(key, 0) + value然后,我将交叉引用这一条中的键和值(香蕉费用、猕猴桃费用等)中的每一条,并从收入中减去每一项目的费用。这些切块将从香蕉表、猕猴桃表等中提取,如下所示:
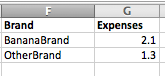
如果品牌名称总是包含在收入表中的产品名称,那么为了编制一个适当的收入值集合,以便与香蕉费用数据库进行比较,例如,我只需要提取所有名字中包含“香蕉”的品牌,并且为了匹配香蕉费用块中的密钥,对它们的值执行提取。
但事实并非如此,所以,,我需要另一种方法来知道,在收入条中,'OtherBrand‘是香蕉,(在香蕉条中,我已经知道它是香蕉,因为它来自香蕉表)。我可以提取(产品、品牌、收入)的一个或多个元组,而不是提取dict <->收入对,现在我们有了Product提供的附加信息。但是由于元组没有密钥的概念,我如何在这个新集合中迭代,以期望的方式提取每个元组的收入(即承认OtherBrand是香蕉等)。
回答 2
Stack Overflow用户
发布于 2015-07-03 21:38:08
您可以使用这些水果作为钥匙,并对品牌进行分组:
from collections import defaultdict
import csv
with open("in.csv") as f:
r = csv.reader(f)
next(r) # skip header
# fruite will be keys, values will be dicts
# with brands as keys and running totals for rev as values
d = defaultdict(lambda: defaultdict(int))
for fruit, brand, rev in r:
d[fruit][brand] += float(rev)其中使用您的输入输出:
from pprint import pprint as pp
pp(dict(d))
{'Apple': defaultdict(<type 'int'>, {'CrunchApple': 1.7}),
'Banana': defaultdict(<type 'int'>, {'BananaBrand': 4.0, 'OtherBrand': 3.2}),
'Kiwi': defaultdict(<type 'int'>, {'NZKiwi': 1.2}),
'Pear': defaultdict(<type 'int'>, {'PearShaped': 6.2})然后你可以用钥匙减去费用。
使用熊猫生活甚至更容易,您可以通过分组和求和:
import pandas as pd
df = pd.read_csv("in.csv")
print(df.groupby(("A","B")).sum())输出:
A B
Apple CrunchApple 1.7
Banana BananaBrand 4.0
OtherBrand 3.2
Kiwi NZKiwi 1.2
Pear PearShaped 6.2或者通过水果和品牌来获得这些群体:
groups = df.groupby(["A","B"])
print(groups.get_group(('Banana', 'OtherBrand')))
print(groups.get_group(('Banana', 'BananaBrand')))Stack Overflow用户
发布于 2015-07-03 20:58:41
在我看来,您希望按产品类型将第一个表中的数据分组。我建议使用字典,其中键是产品类型,值是元组的列表( [(brand, revenue),(..., ...)] )。
然后,对于字典中的每种产品类型,您可以很容易地提取出该产品的品牌列表,如果需要,可以创建一个包含三元组(brand, revenue, expenses)列表的新字典。
https://stackoverflow.com/questions/31214051
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号