
用ggplot2对3种不同数据集的3幅图进行面处理
我有3个数据集( df1、df2、df3 ),每个数据集包含三个列(csv文件:https://www.dropbox.com/s/56qh1l5kchsiof0/datasets.zip?dl=0)
每个数据集表示这三列的柱状图,如下所示:
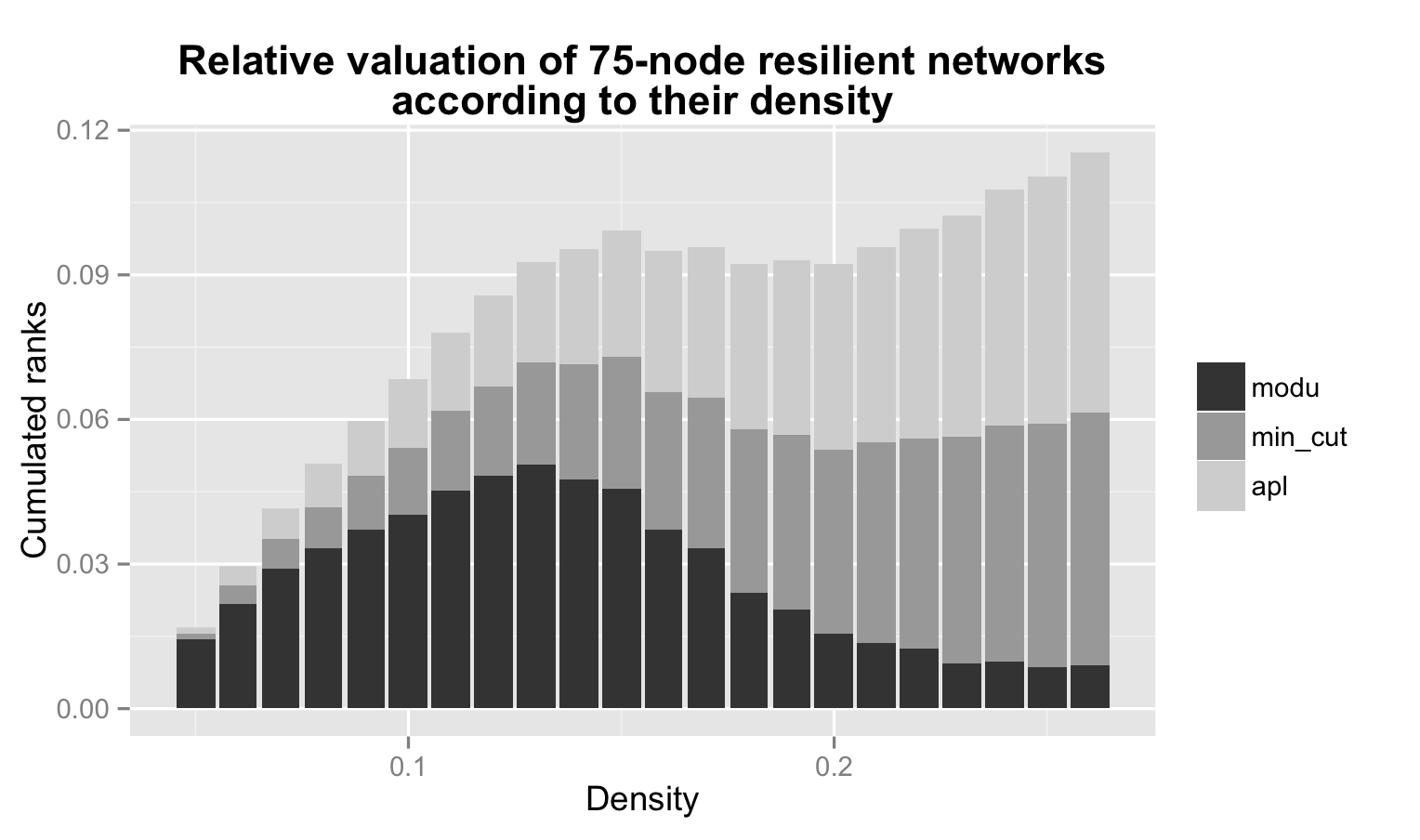
此示例显示了df3,其中dataset的三列df3.csv被堆叠在另一列之上
下面是我的r代码来生成上面的图:
require(reshape2)
library(ggplot2)
library(RColorBrewer)
df = read.csv(".../df3.csv",sep=",", header=TRUE)
df.m = melt(df,c("density"))
c = ggplot(df.m, aes(x = density, y = value/1e+06,fill = variable)) + labs(x = "Density", y = "Cumulated ranks",fill = NULL)
c = c + geom_bar(stat = "identity", position = "stack") + scale_fill_grey(..., start = 0.2, end = 0.8, na.value = "grey50")
c = c + ggtitle('Relative valuation of 75-node resilient networks\naccording to their density') + theme(plot.title = element_text(lineheight=.8, face="bold"))
c现在,我需要构建一个df1、df2和df3 (分别显示三列)共享相同x轴比例的方面图,如下所示:
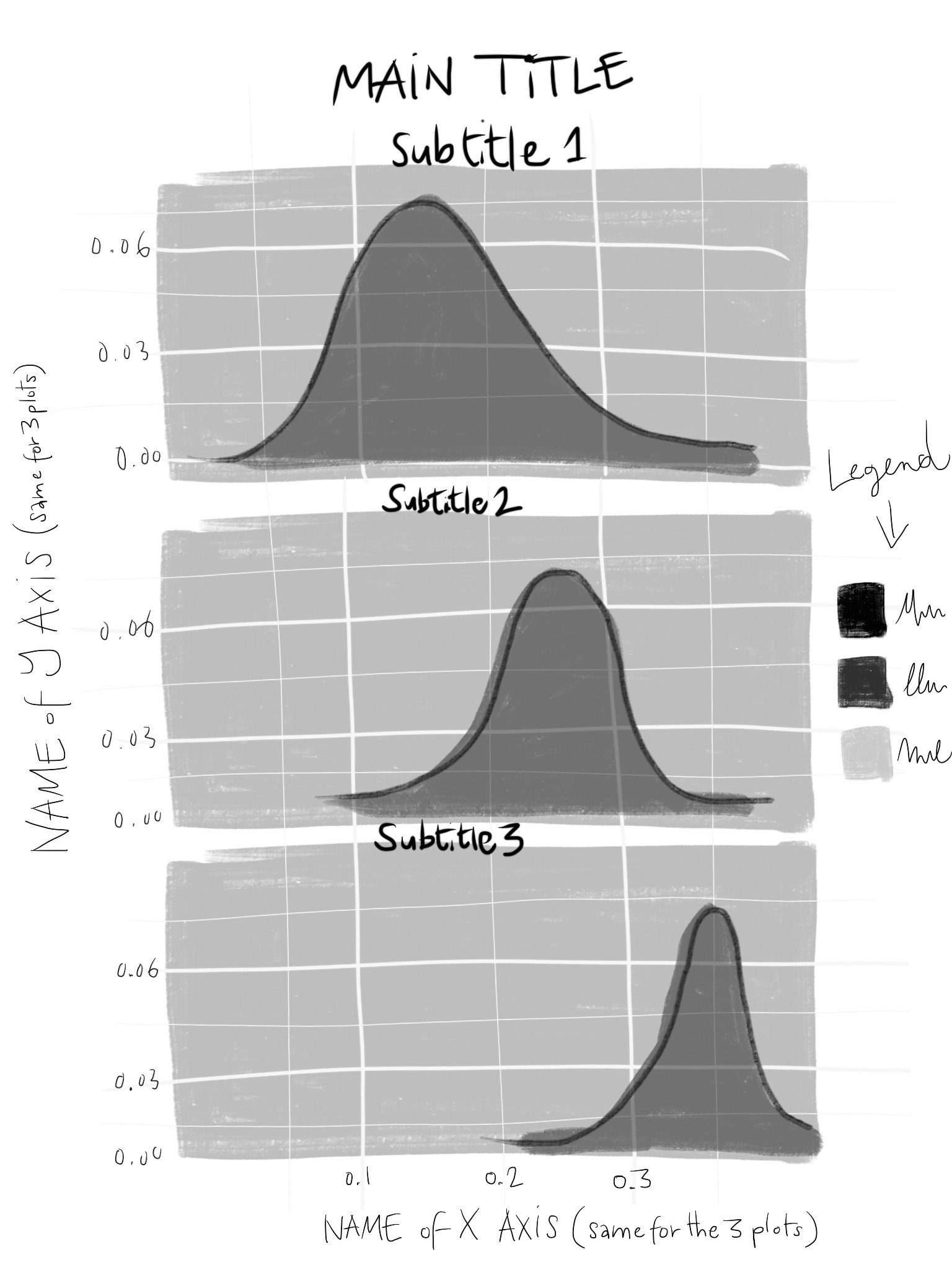
我很抱歉那些糟糕的涂鸦..。另外,每个子图应该是一个堆叠的条形图,如图1所示,而不是密度图。
我能不能这样做:
require(reshape2)
library(ggplot2)
library(RColorBrewer)
df = read.csv(".../df1.csv",sep=",", header=TRUE)
df.m = melt(df,c("density"))
a = ggplot(df.m, aes(x = density, y = value/1e+06,fill = variable)) + labs(x = "Density", y = "Cumulated ranks",fill = NULL)
a = a + geom_bar(stat = "identity", position = "stack") + scale_fill_grey(..., start = 0.2, end = 0.8, na.value = "grey50")
a = a + ggtitle('subtitle 1') + theme(plot.title = element_text(lineheight=.8, face="bold"))
df = read.csv(".../df2.csv",sep=",", header=TRUE)
df.m = melt(df,c("density"))
b = ggplot(df.m, aes(x = density, y = value/1e+06,fill = variable)) + labs(x = "Density", y = "Cumulated ranks",fill = NULL)
b = b + geom_bar(stat = "identity", position = "stack") + scale_fill_grey(..., start = 0.2, end = 0.8, na.value = "grey50")
b = b + ggtitle('subtitle 2') + theme(plot.title = element_text(lineheight=.8, face="bold"))
df = read.csv(".../df3.csv",sep=",", header=TRUE)
df.m = melt(df,c("density"))
c = ggplot(df.m, aes(x = density, y = value/1e+06,fill = variable)) + labs(x = "Density", y = "Cumulated ranks",fill = NULL)
c = c + geom_bar(stat = "identity", position = "stack") + scale_fill_grey(..., start = 0.2, end = 0.8, na.value = "grey50")
c = c + ggtitle('subtitle 3') + theme(plot.title = element_text(lineheight=.8, face="bold"))
all = facet_grid( _???_ )或者我需要以不同的方式组织我的数据?
回答 1
Stack Overflow用户
发布于 2014-09-13 19:39:20
如果你重新组织你的数据,那就更容易了。您希望所有数据都位于一个data.frame中,以便只调用ggplot一次。为了做到这一点,您需要堆叠所有融化的data.frames,并添加一个列来指示它来自哪个文件。当我需要读取一堆文件时,我使用了一个名为read.stack()的帮助函数,但是您可以使用数百种不同的方法来准备数据。
这是我试过的。首先,我们准备数据。
ff<-list.files("~/Downloads/datasets/", full=T);
dd<-read.stack(ff, sep=",", header=T, extra=list(file=basename(ff)))
mm<-melt(dd,c("density","file"))
head(mm)
# density file variable value
# 1 0.12 df1.csv modu 50
# 2 0.12 df1.csv modu 472
# 3 0.12 df1.csv modu 145
# 4 0.12 df1.csv modu 59
# 5 0.12 df1.csv modu 51
# 6 0.12 df1.csv modu 86请注意,我们刚刚添加了一个列,该列指示数据的来源,稍后我们将使用该列指定一个facet。现在我们策划..。
ggplot(mm, aes(x=density, y=value/1e6, fill=variable)) +
geom_bar(stat="identity", position="stack") +
scale_fill_grey(start = 0.2, end = 0.8, na.value = "grey50") +
labs(x = "Density", y = "Cumulated ranks",fill = NULL) +
ggtitle('Relative valuation of 75-node resilient networks\naccording to their density') +
theme(plot.title = element_text(lineheight=.8, face="bold")) +
facet_grid( file~.)结果是
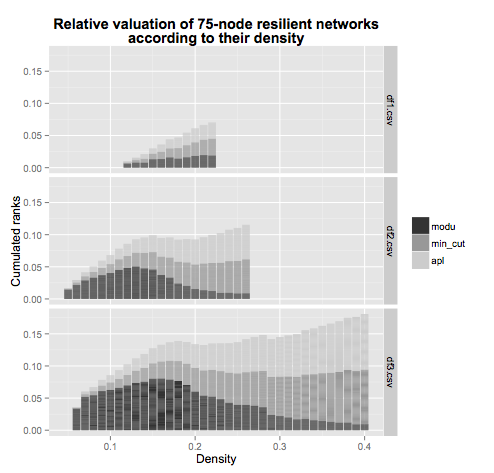
https://stackoverflow.com/questions/25826735
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号