
如何在尝试解压缩node.js时,递归地压缩目录,而不获取格式错误的文件
到目前为止,我已经尝试过ADM-ZIP和易拉链。它们都创建了一个zip,该zip大部分是成功的,但是有一些格式错误的文件:
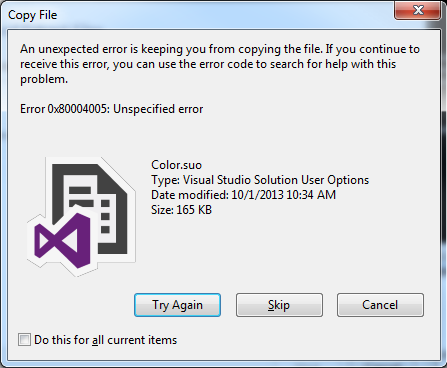
这种情况发生在各种文件类型(包括常规图片和html页面)。我怀疑文件类型甚至不是一个问题。不管怎样,如果它不能完美的工作,我就不能使用它。
有些人建议使用节点存档,但是没有关于如何压缩文件的说明,更不用说在保持文件结构的同时递归地压缩目录。
更新
按照要求,这里是我使用的代码(adm-zip)。
var Zip = require("adm-zip");
var zip = new Zip();
zip.addLocalFolder("C:\\test");
zip.writeZip("C:\\test\\color.zip");回答 4
Stack Overflow用户
发布于 2013-10-15 08:55:27
正如您所提到的,我会使用node-archiver。您可以通过以下方式从node-archiver获得嵌套文件夹:
var archiver = require('archiver');
var archive = archiver('zip')
// create your file writeStream - let's call it writeStream
archive.pipe(writeStream);
// get all the subfiles/folders for the given folder - this can be done with readdir
// take a look at http://nodejs.org/api/fs.html#fs_fs_readdir_path_callback
// and https://stackoverflow.com/questions/5827612/node-js-fs-readdir-recursive-directory-search
// appending to the archiver with a name that has slashes in it will treat the payload as a subfolder/file
// iterate through the files from the previous walk
ITERATE_THROUGH_RESULTS_FROM_WALK
// look into http://nodejs.org/api/fs.html#fs_fs_readfile_filename_options_callback
GET_READ_STREAM_ON_FILE_FROM_FS
archive.append((new Buffer(data), 'utf-8'), {name: NAME_WITH_SLASHES_FOR_PATH});
archive.finalize(function (err) {
// handle the error if there is one
});希望这是一个很好的推动,朝着正确的方向(基本上所有的步骤都在你身边)。如果还不清楚的话:
- 使用“zip”选项创建您的存档。
- 管道到要保存zip文件的地方创建的writestream。
- 递归遍历文件夹,将路径保存在集合(数组)中。
- 迭代这个路径集合,打开每个文件。
- 当您拥有每个文件的数据时,从它创建一个
Buffer并将其以及路径传递到archive.append。 - 打给
archive.finalize。
为了可读性,而且我相信我已经给出了您所需要的几乎所有步骤,所以我没有包含所有的代码(最显著的是遍历--无论如何,这是在链接中列出的)。
Stack Overflow用户
发布于 2013-10-07 14:57:42
您已经请求了一个zip,但是如果您只需要存档用于传输的文件,那么我建议您使用tar.gz。使用它在生产中传输目录
下面是使用示例:https://github.com/cranic/node-tar.gz#usage
var targz = require('tar.gz');
var compress = new targz().compress('/path/to/compress', '/path/to/store.tar.gz', function(err){
if(err)
console.log(err);
console.log('The compression has ended!');
});并解压缩:
var targz = require('tar.gz');
var compress = new targz().extract('/path/to/stored.tar.gz', '/path/to/extract', function(err){
if(err)
console.log(err);
console.log('The extraction has ended!');
});Stack Overflow用户
发布于 2014-02-18 16:49:16
archiver有一个支持格伦特的“文件阵列”格式的bulk方法。下面是一个递归压缩文件夹foo及其中的所有内容的递归示例。
foo
├── bar
| ├── a.js
| └── b.js
└── index.html基于JavaScript的归档器中的此示例
var output = fs.createWriteStream('foo.zip');
var archive = archiver('zip');
output.on('close', function() { console.log('done') });
archive.on('error', function(err) { throw err });
archive.pipe(output);
archive.bulk([
{ expand: true, cwd: 'foo', src: ['**/*'] }
]).finalize();https://stackoverflow.com/questions/19227771
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号