
Python:从列表中填充下三角矩阵
Python:从列表中填充下三角矩阵
提问于 2013-07-08 00:40:12
我有csv格式的机票可用性的离散时间数据.这用于表示起飞窗口和到达时间窗口组合的票证可用性。假设我的一天被划分为四个时间段-
12:01 AM to 6:00 AM,
6:01 AM to 12:00 PM,
12:01 PM to 6:00 PM,
6:01 PM to 12:00 AM1意味着有可供该组合出发和到达的机票,否则为0。在本例中,假设机票可用于所有出发到达组合,csv文件将具有以下数据:
1,1,1,1,1,1,1,1,1,1此数据用于表示此矩阵(请注意,有些组合在这里变为零,因为它们在24小时内是不合逻辑的时间组合):
Departure time period
12:01 AM to 6:00 AM | 6:01 AM to 12:00 PM | 12:01 PM to 6:00 PM | 6:01 PM to 12:00 AM|
Arrival time period ------------------- | ---------------------|---------------------|---------------------|
12:01 AM to 6:00 AM 1 | 0| 0| 0|
6:01 AM to 12:00 PM 1 | 1| 0| 0|
12:01 PM to 6:00 PM 1 | 1| 1| 0|
6:01 PM to 12:00 AM 1 | 1| 1| 1|csv文件将此数据保存多天。我以字典的形式阅读了这些数据,其中日期为键,可用性组合为列表。数据处理是用Python 2.7进行的。对于特定的一天,我现在可以使用日期键检索可用性列表。
现在,我有两个问题:
- 如何将数据转换为矩阵类型的数据结构。本质上,这涉及到将列表转换为下三角矩阵加上对角线元素。我尝试过在
numpy中使用reshape函数,但这并没有达到这个效果。 - 一旦我转换了矩阵--我想用图形化的方式将可用性表示为一个主题网格--所有的1s都是绿色方块,0表示为红色方块。这在Python中是可以实现的吗?多么?
我认为,以字典的形式在csv中阅读,然后将可用性元素存储在列表中是一种方法,因为它看起来相当简单。如果你觉得有更聪明的方法来做这件事,你可以修改这个方法。
伙计们,有什么想法吗?
回答 1
Stack Overflow用户
回答已采纳
发布于 2013-07-08 01:08:03
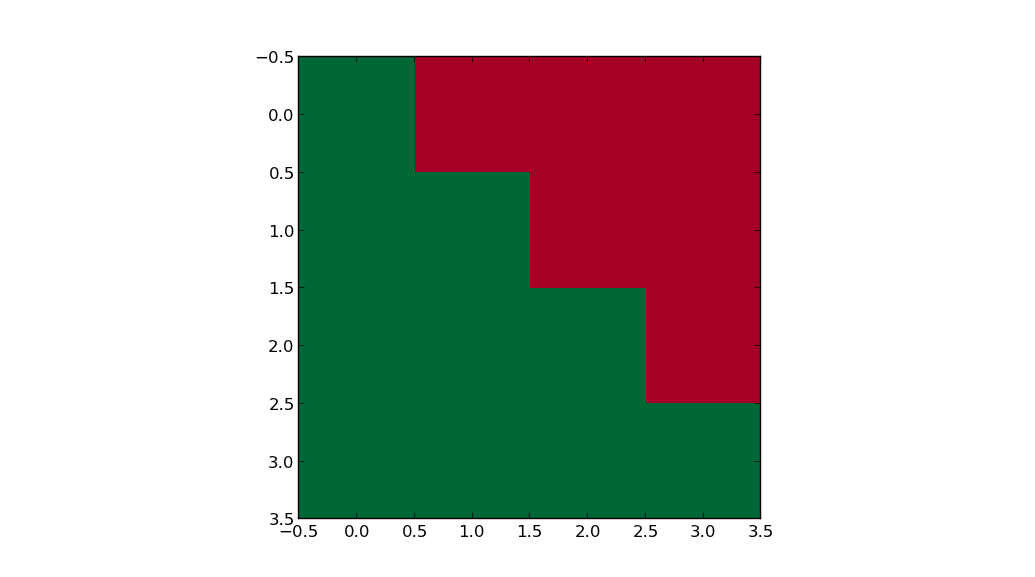
import numpy as np
import matplotlib.pyplot as plt
data = [1,1,1,1,1,1,1,1,1,1]
arr = np.zeros((4,4))
indices = np.tril_indices(4)
arr[indices] = data
print(arr)
# array([[ 1., 0., 0., 0.],
# [ 1., 1., 0., 0.],
# [ 1., 1., 1., 0.],
# [ 1., 1., 1., 1.]])
plt.imshow(arr, interpolation='nearest', cmap=plt.get_cmap('RdYlGn'))
plt.show()图
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/17517787
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号